Statistical Communication and Workflow
STAT1003 – Statistical Techniques
Australian National University
These slides are best viewed on a modern browser like Google Chrome on a desktop or laptop. Some interactive components may require some time to fully load.
File paths
- Your file has to be in the right location to be read!
- To point to the right location of the data , you may use
- a relative path (e.g.
data/data.csv) or - an absolute path (e.g.
C:\\user/myproject/data.csv)
- a relative path (e.g.
You should avoid using absolute path! Why?
- You can get and set the current path using
getwd()andsetwd(), respectively.
Reading Excel sheets
- Data can also come in a propriety format (e.g. xls and xlsx) – these require special ways to open/view/read it.
data/template_Morris.xlsx
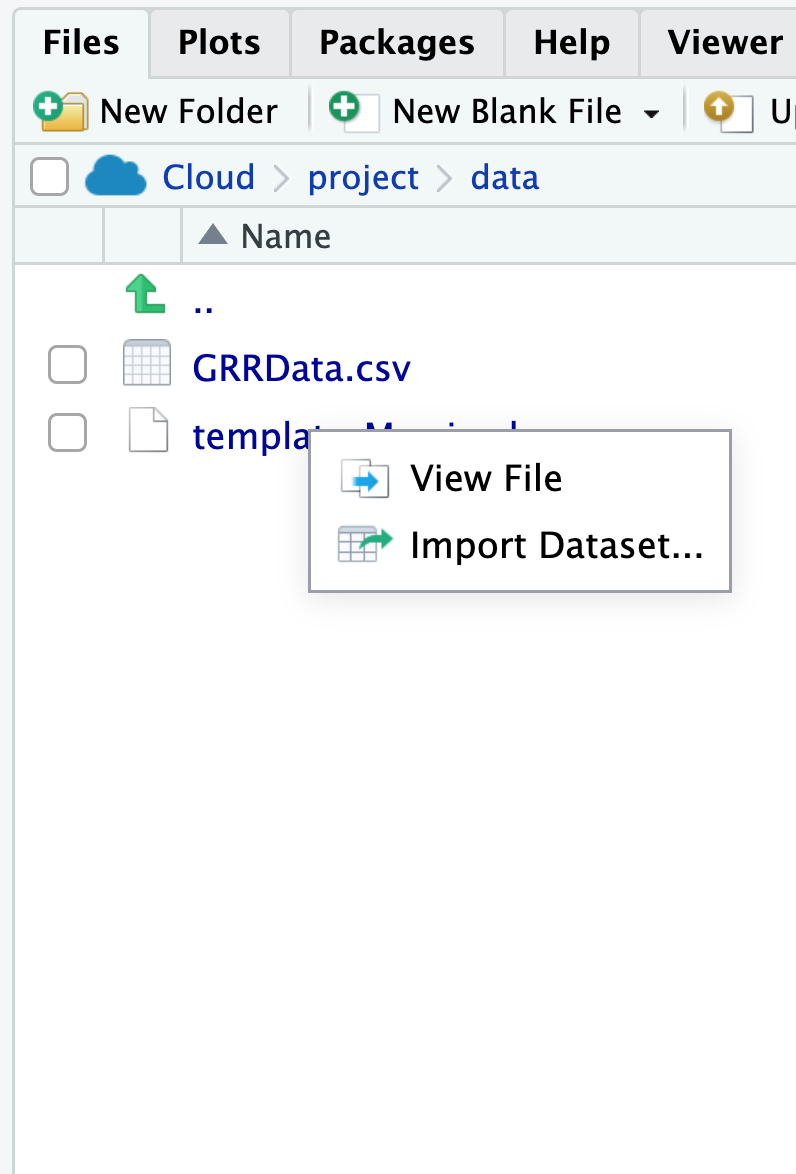
Importing through the GUI
In RStudio Desktop, you can click on the file for importing via GUI.
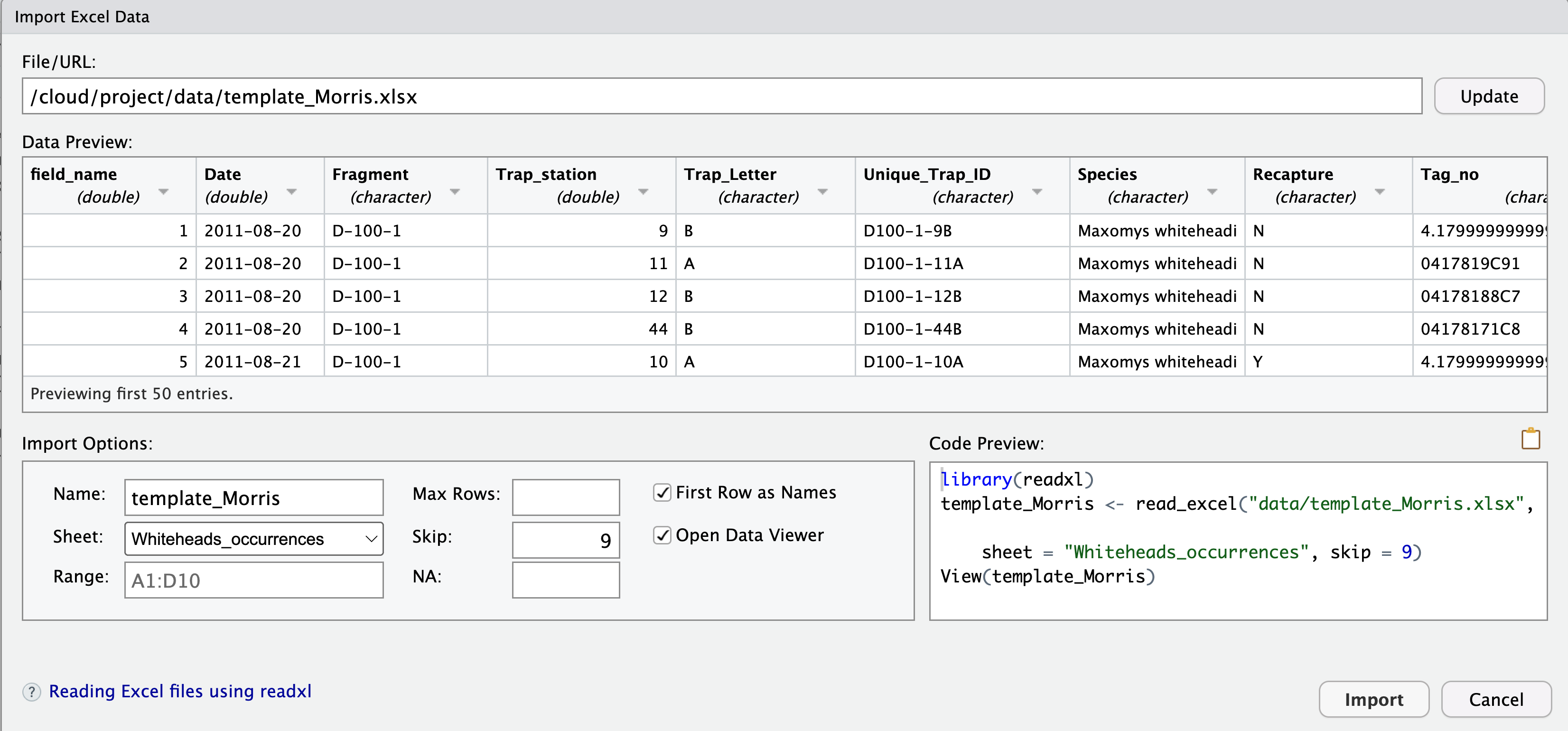
Data import cheatsheet


Quarto in a nutshell
Quarto integrates text + code in one source document with ability to render to many output formats (via Pandoc), e.g. docx, pdf or html.
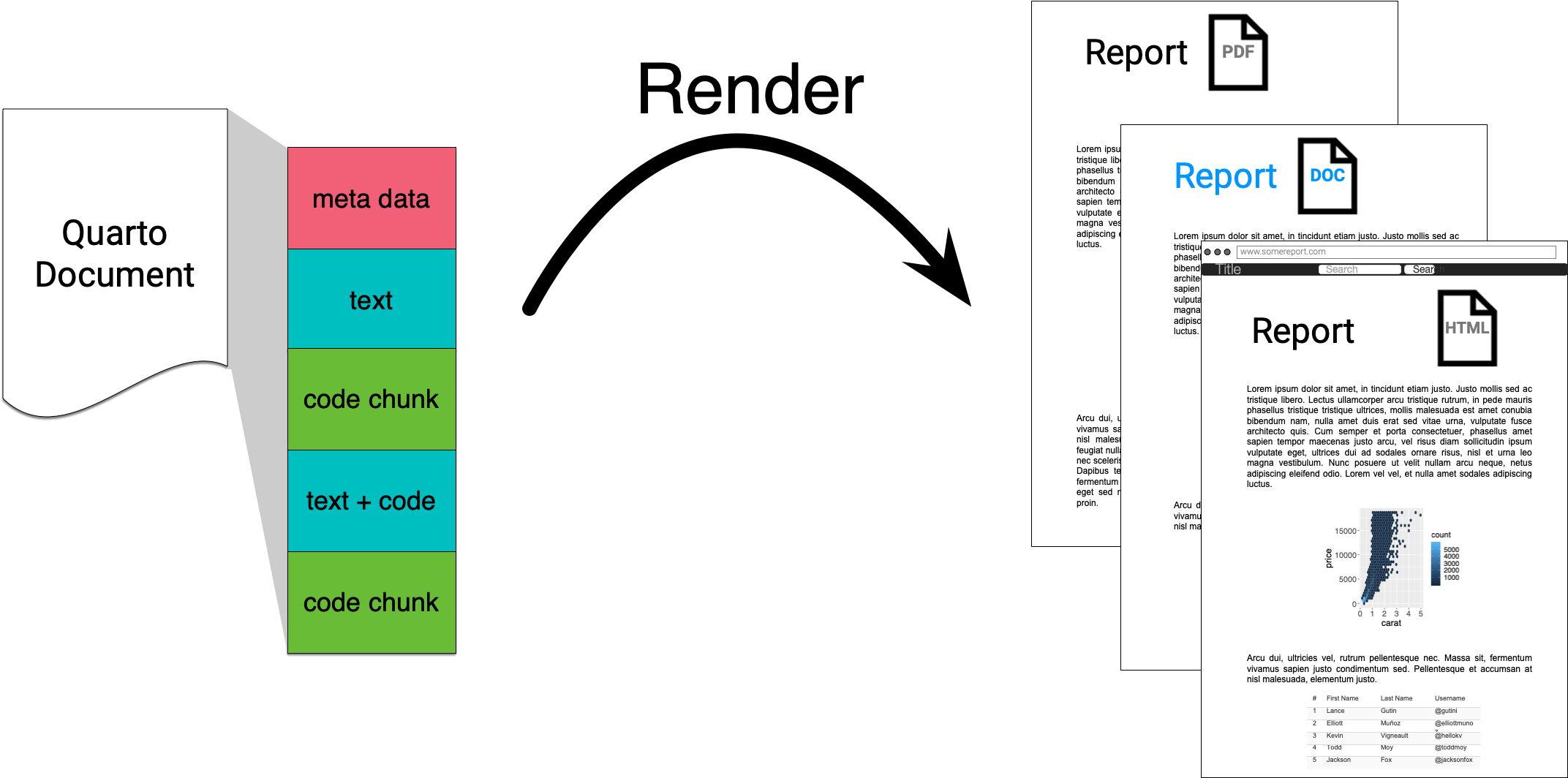
- Note: Quarto is the next generation of R Markdown.
R Markdown
- Quarto and R Markdown are very similar.
- The same team that created R Markdown created Quarto.
- Quarto supersedes R Markdown so we focus on Quarto.
R Markdown
Quarto
Thesis

This PhD thesis (online and pdf) is made using Quarto.
Available at https://thesis.patrickli.org/
Quarto basics
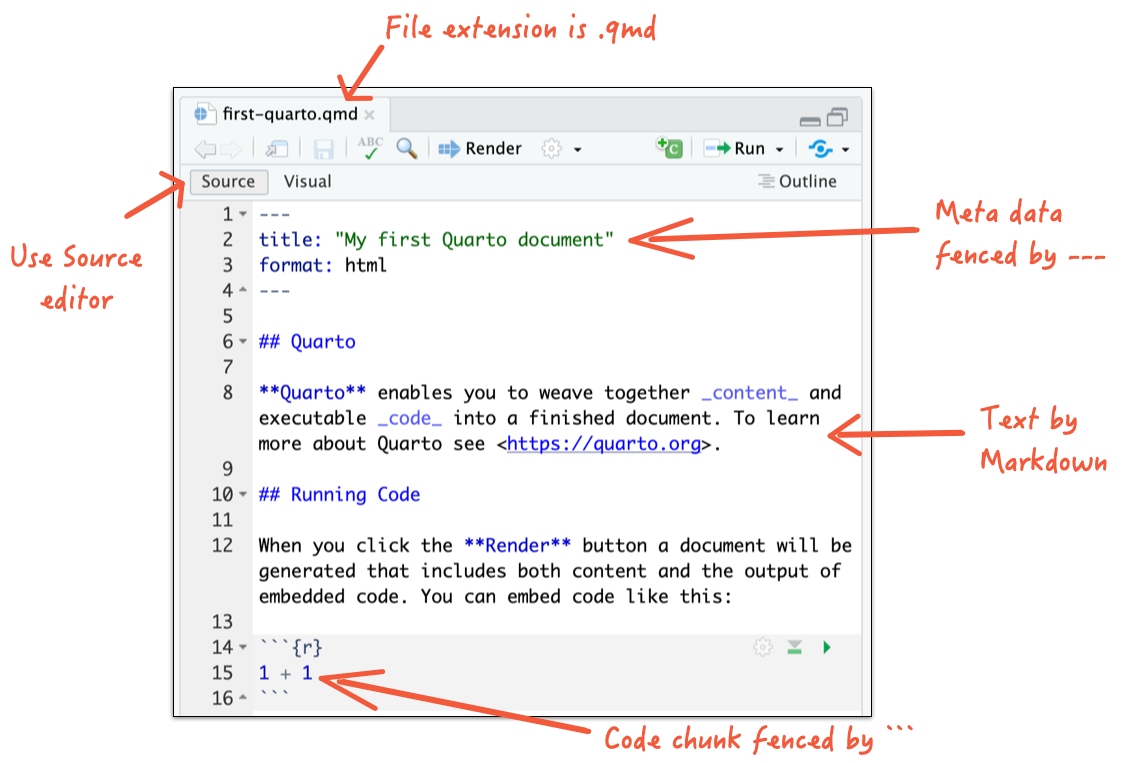
- If you are not using RStudio Desktop, open with your own editor.
Render to a HTML document
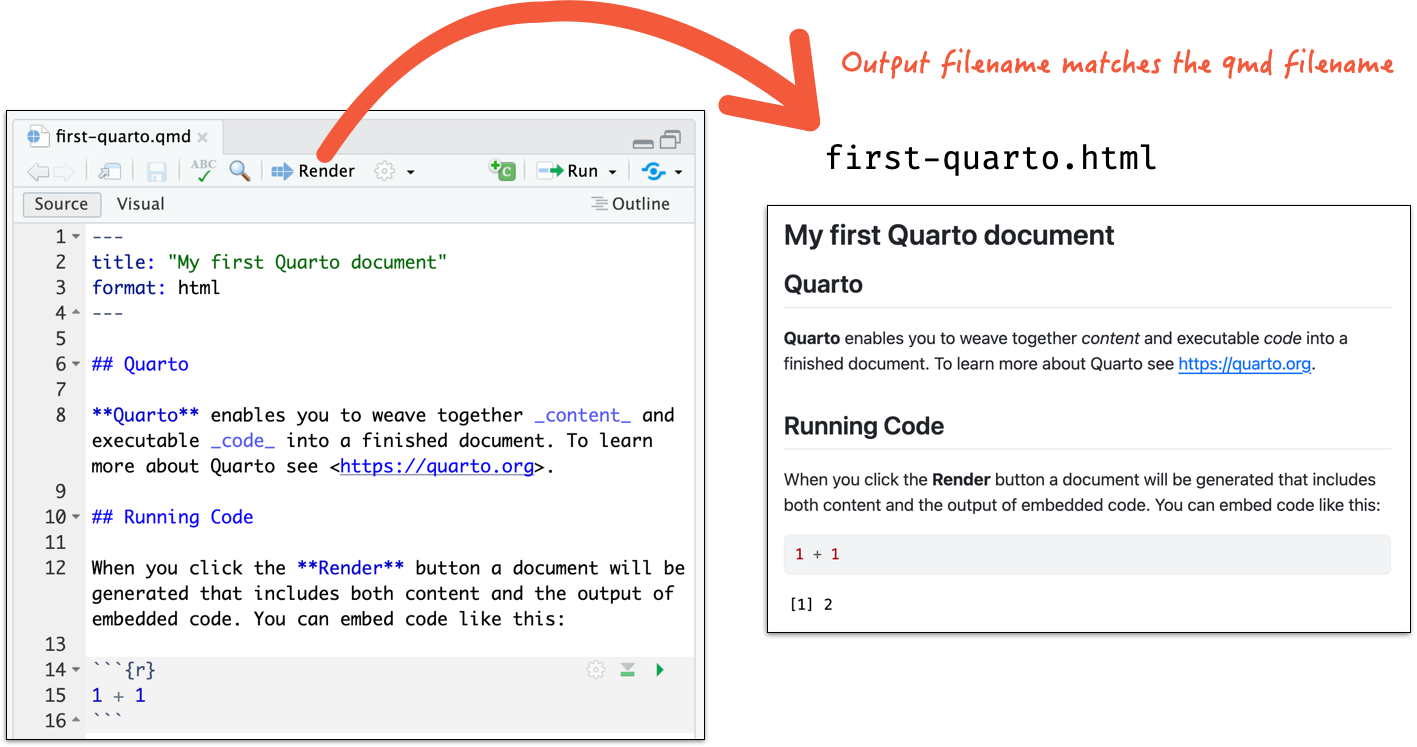
- If you are not using RStudio Desktop, open the terminal and run
Render to a PDF document
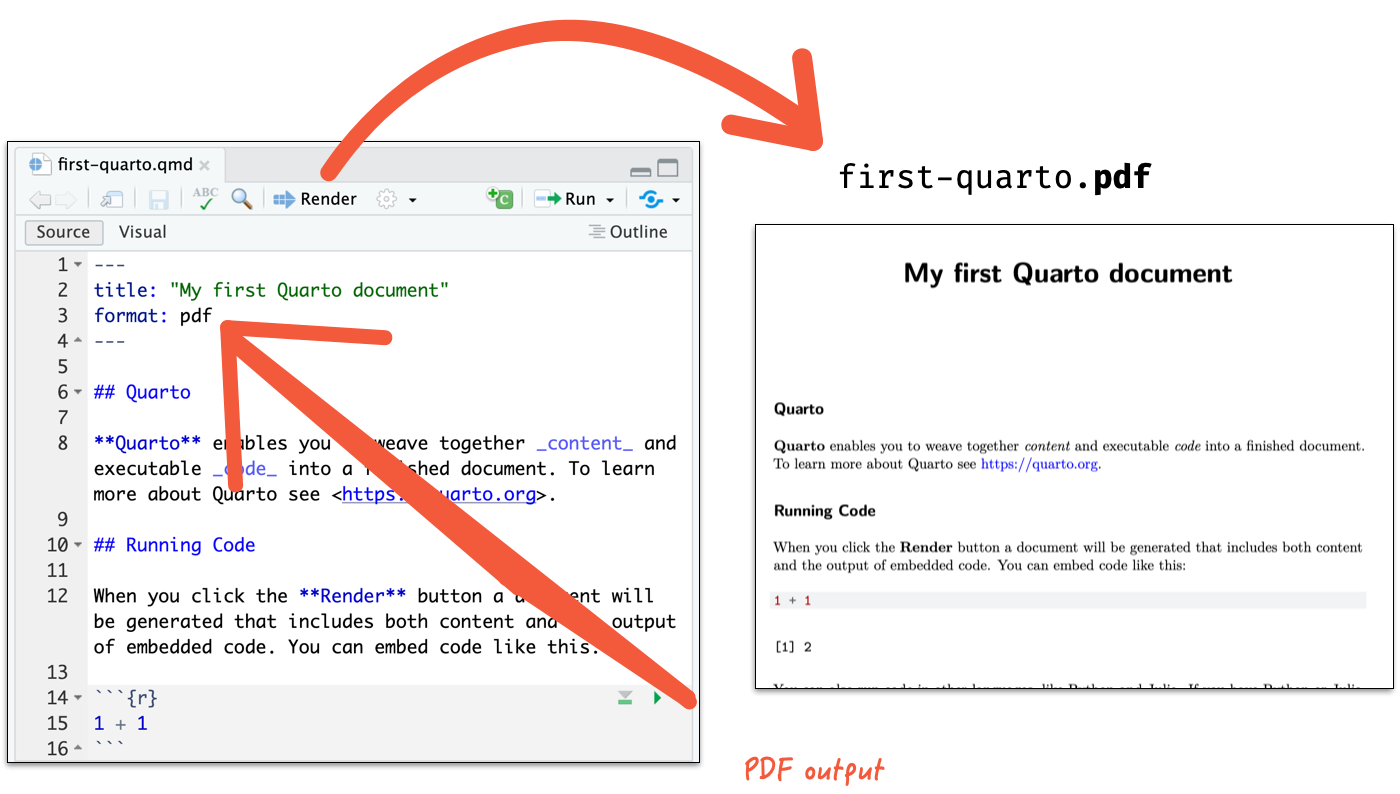
- If you are not using RStudio Desktop, open the terminal and run
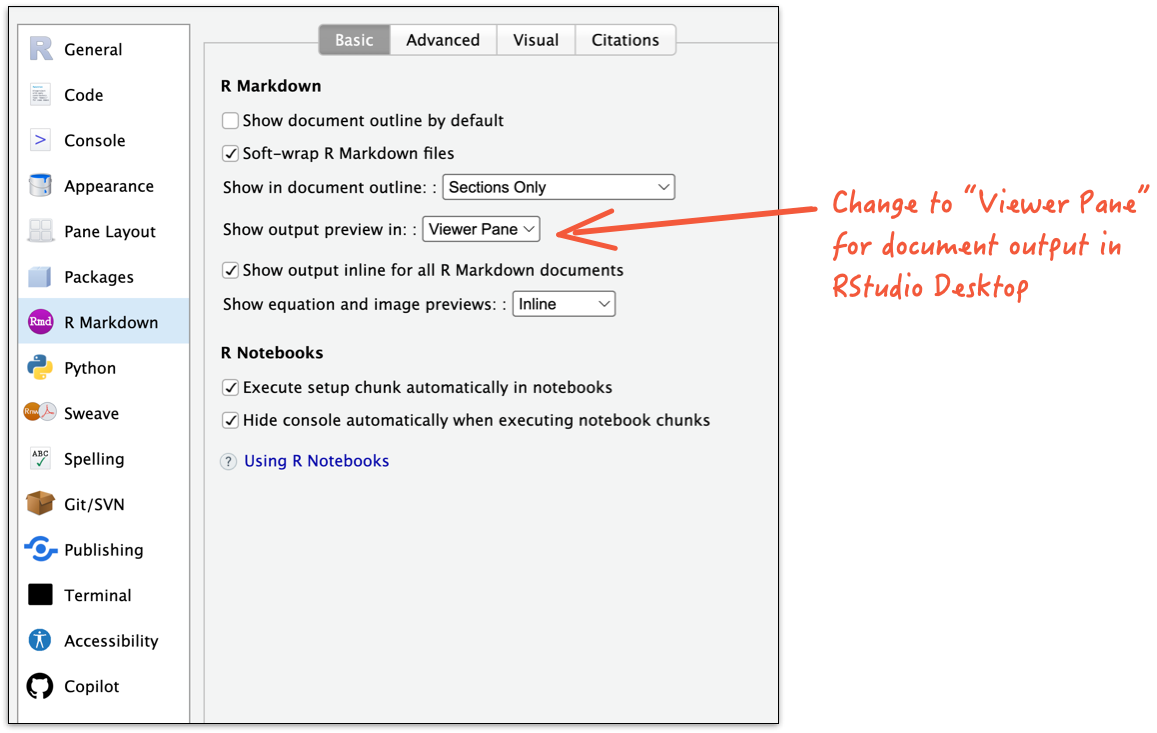
RStudio Desktop
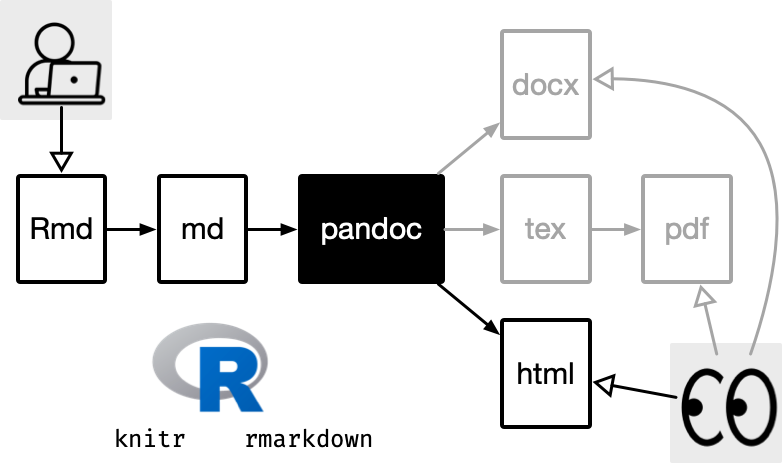
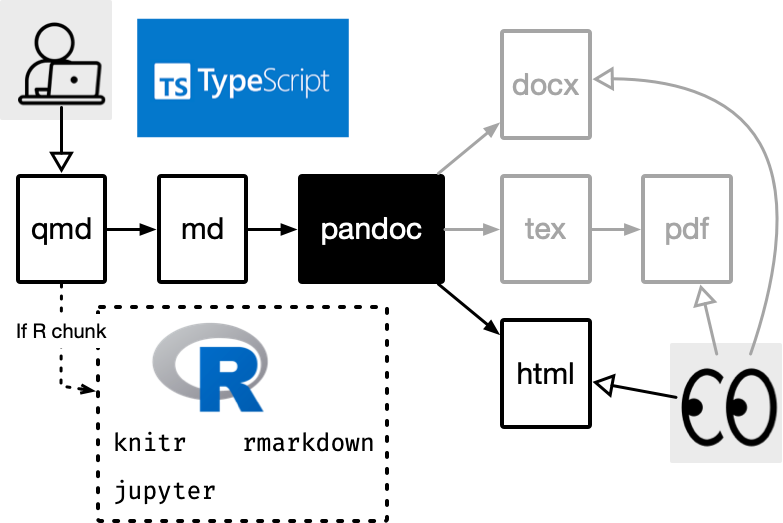
How does it all work?
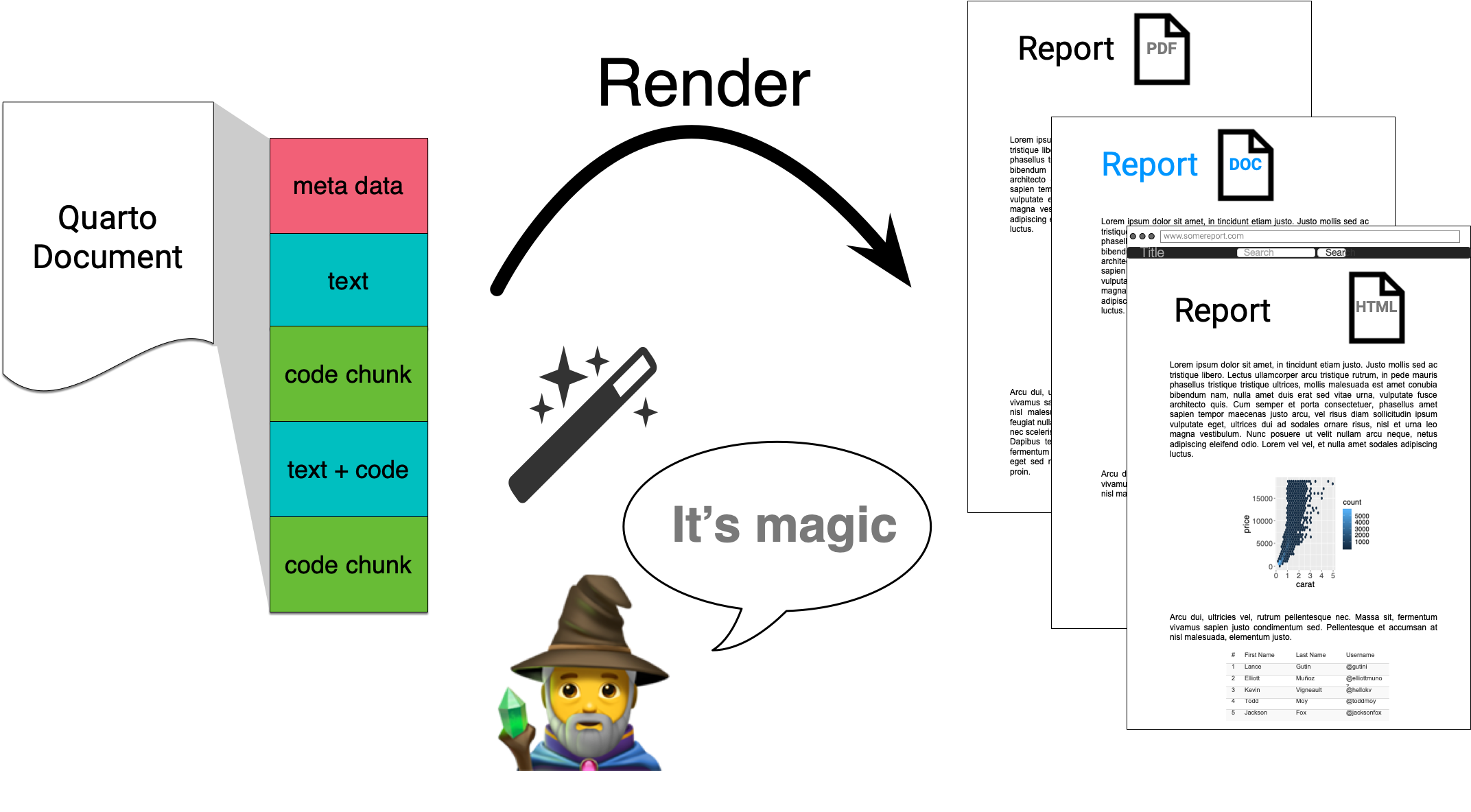
Quarto via knitr/jupyter: qmd md
Pandoc: md html, pdf, docx
Meta Data with YAML
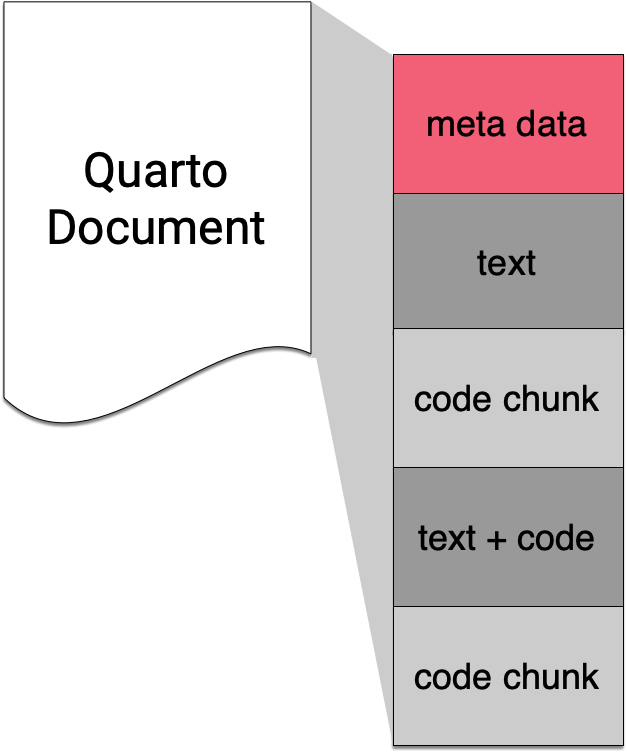
Values spanning multiple lines
A value can span multiple lines in two ways:
- Using the pipe symbol
|to preserve line breaks. - Using the greater-than symbol
>to fold lines (line breaks become spaces).

Text with Markdown
Headers
Lists

Formatting text

Inserting images and links
RStudio > Help > Markdown Quick Reference
Dynamic Documents with Data Analysis Code
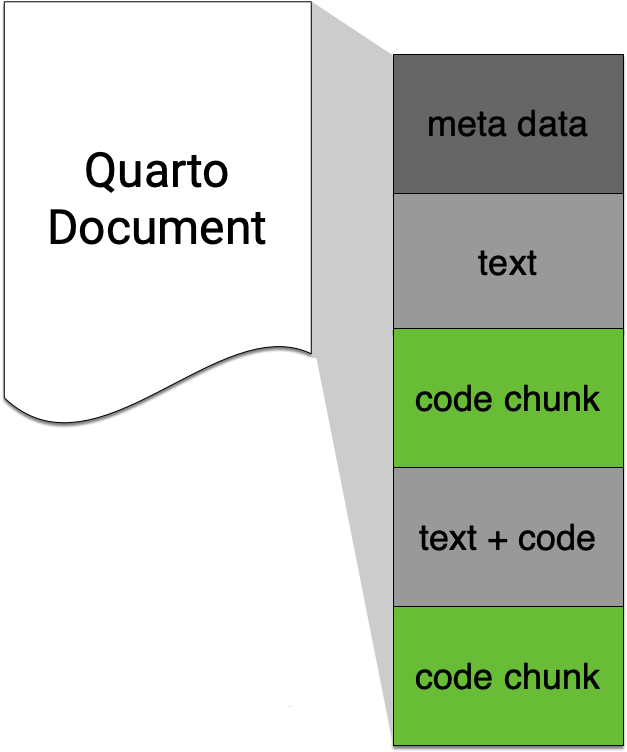
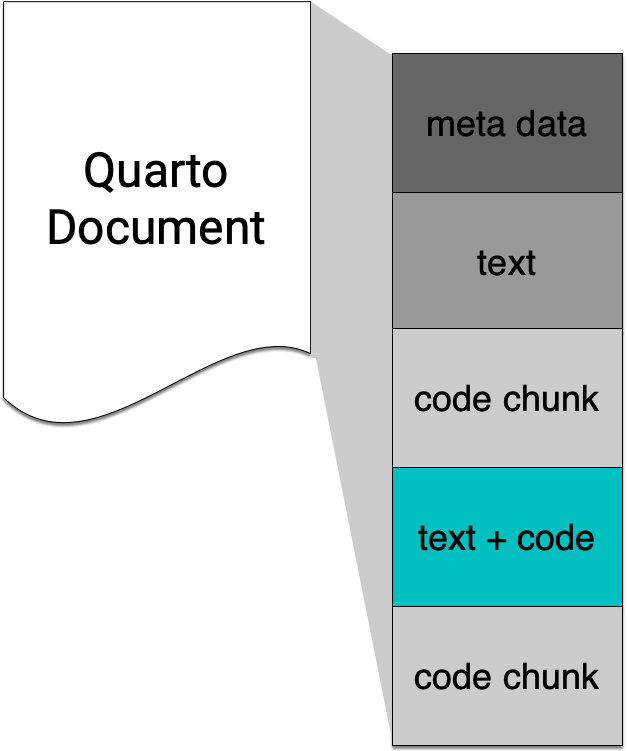
Code chunks
- In Quarto (and R Markdown), code is included in code chunks.
- Code chunks are delimited by triple backticks
```with the language specified after the opening backticks.
Chunk options
Inline R code
`r some_r_code()`The number of observations in the ChickWeight dataset is 578.
The value of \(\pi\) is 3.1415927.
- Note that these inline R command only work if
engine: knitr. - This doesn’t work for other languages.
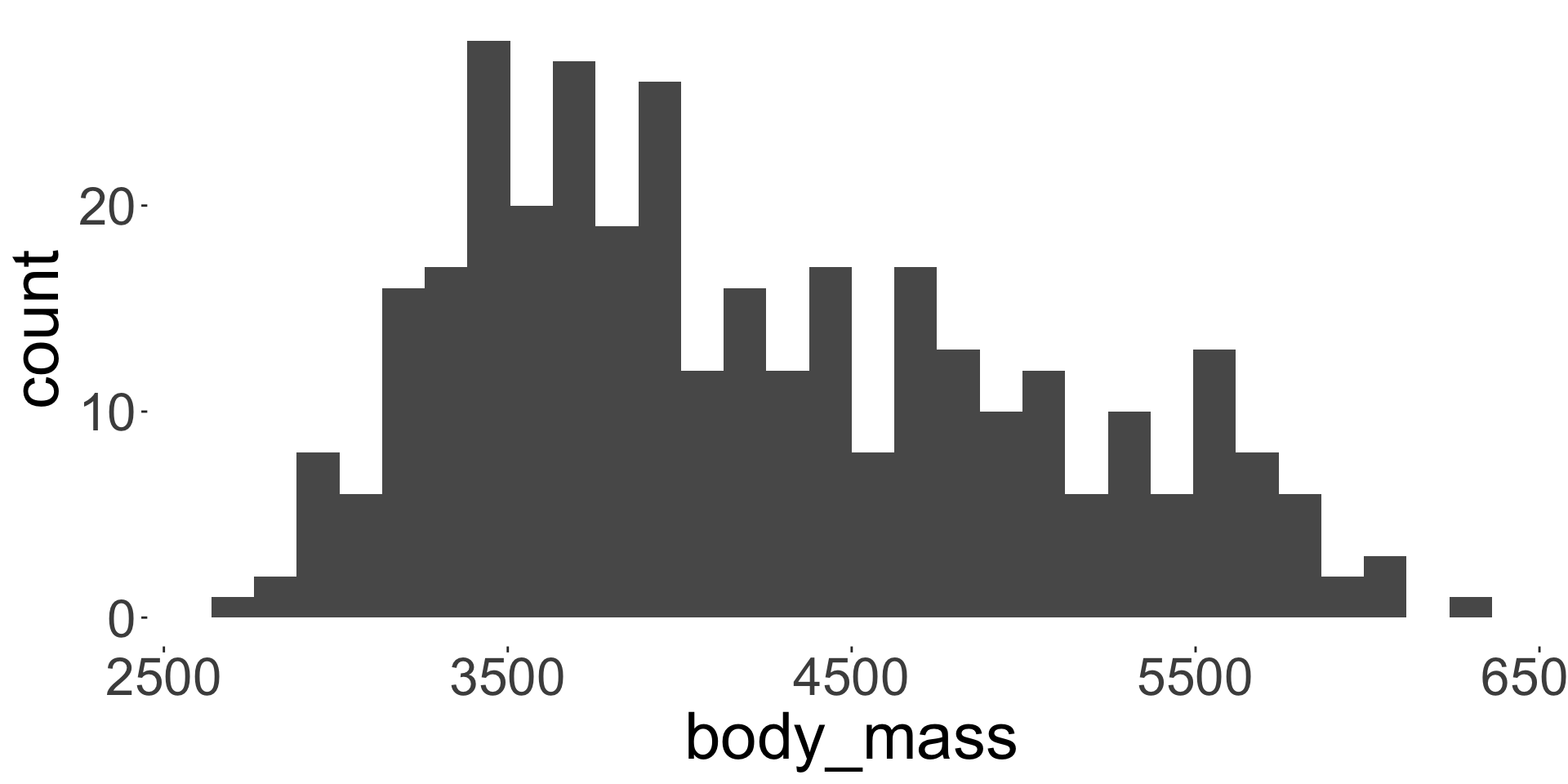
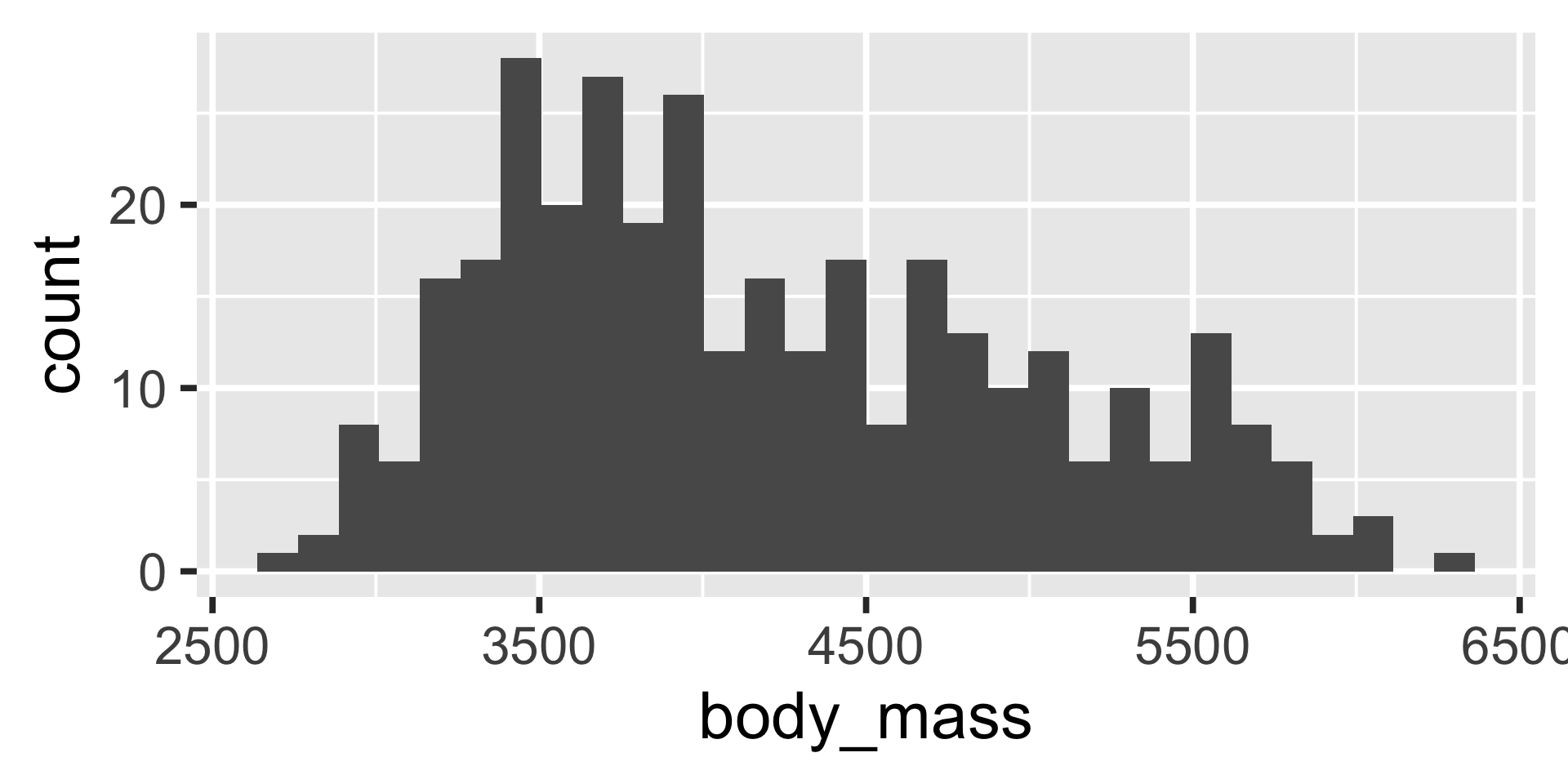
Figure references
The chunk label with prefix fig- can be referenced in text as a figure.
The body mass distribution of penguins is shown in Figure 2.
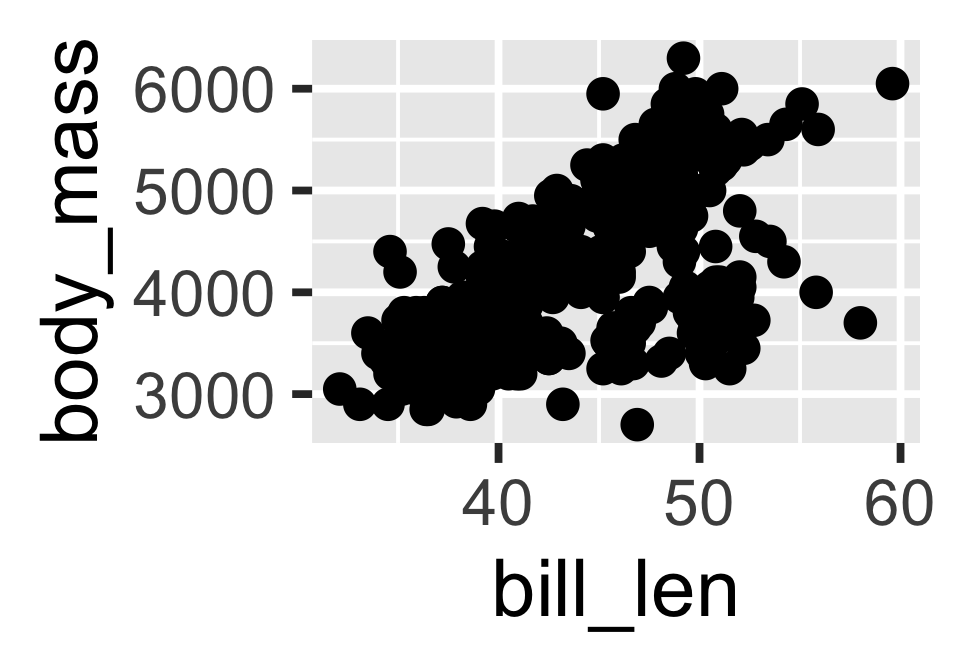
- Above we use the
ggplot2package to create a figure, but you can use base R plotting functions or other packages.
Summary
Weave together text, code, and output (figures, tables, etc.) in a single document using Quarto into various output formats (HTML, PDF, Word, etc.).
- Use YAML to control document’s meta data.
- Use Markdown syntax in the body of the document to write content.
- Use R (or Python, Julia, etc.) for data analysis and visualization.
- Focus on writing the content instead of formatting!
- The best guide for Quarto is at https://quarto.org/docs/guide/.
Quarto cheatsheet


Non-robust workflow
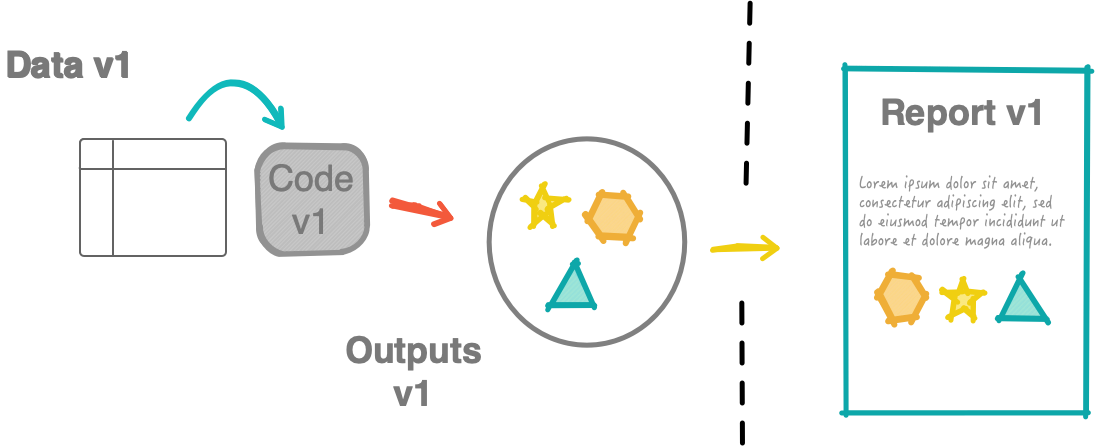
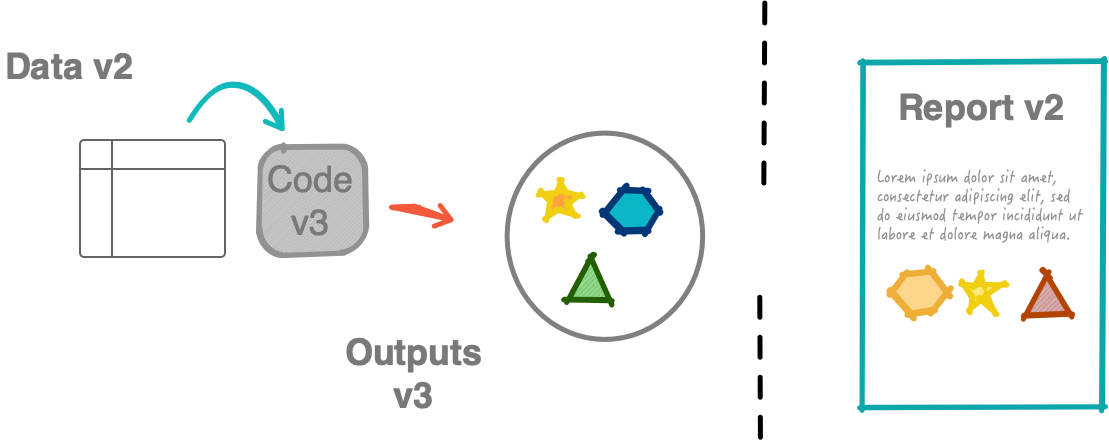
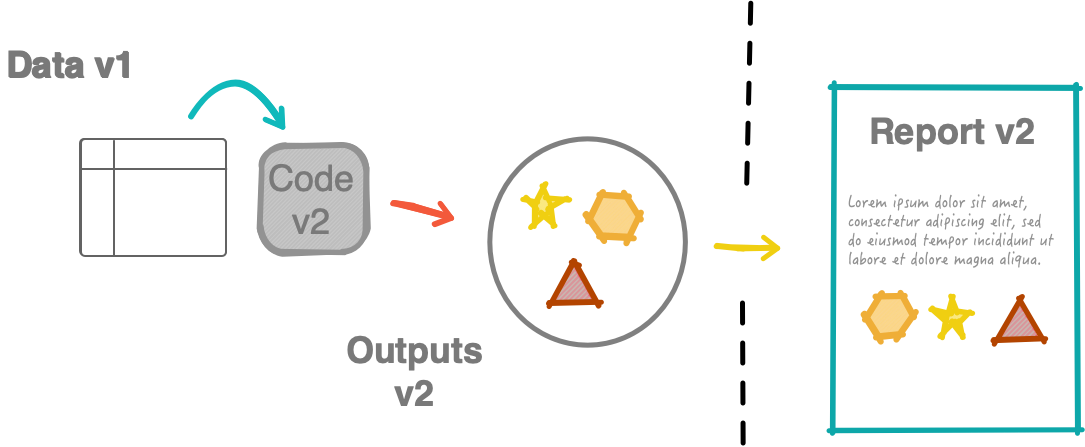
What should have been submitted:

Analysis framework

Tidy data
- Each column is a variable.
- Each row is an observation.
- Each cell is a single value.
Tools
- Git/GitHub for version control and collaboration
- Open-source programming languages (e.g. R and Python) for coding
- Quarto with markdown syntax for interoperable reproducible reports
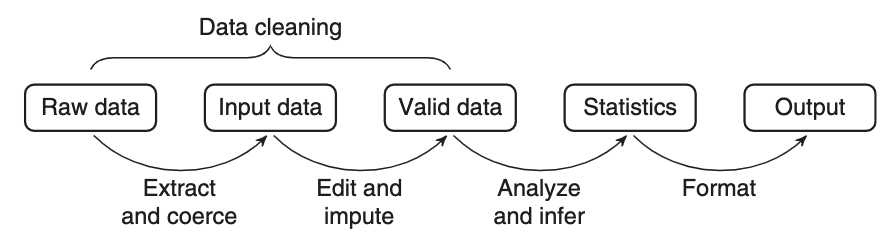
Statistical value chain
… a statistical value chain is constructed by defining a number of meaningful intermediate data products, for which a chosen set of quality attributes are well described …
– van der Loo & de Jonge (2018)