Architecture of Large Language Models
Introduction to Large Language Models for Statisticians
15th October 2024
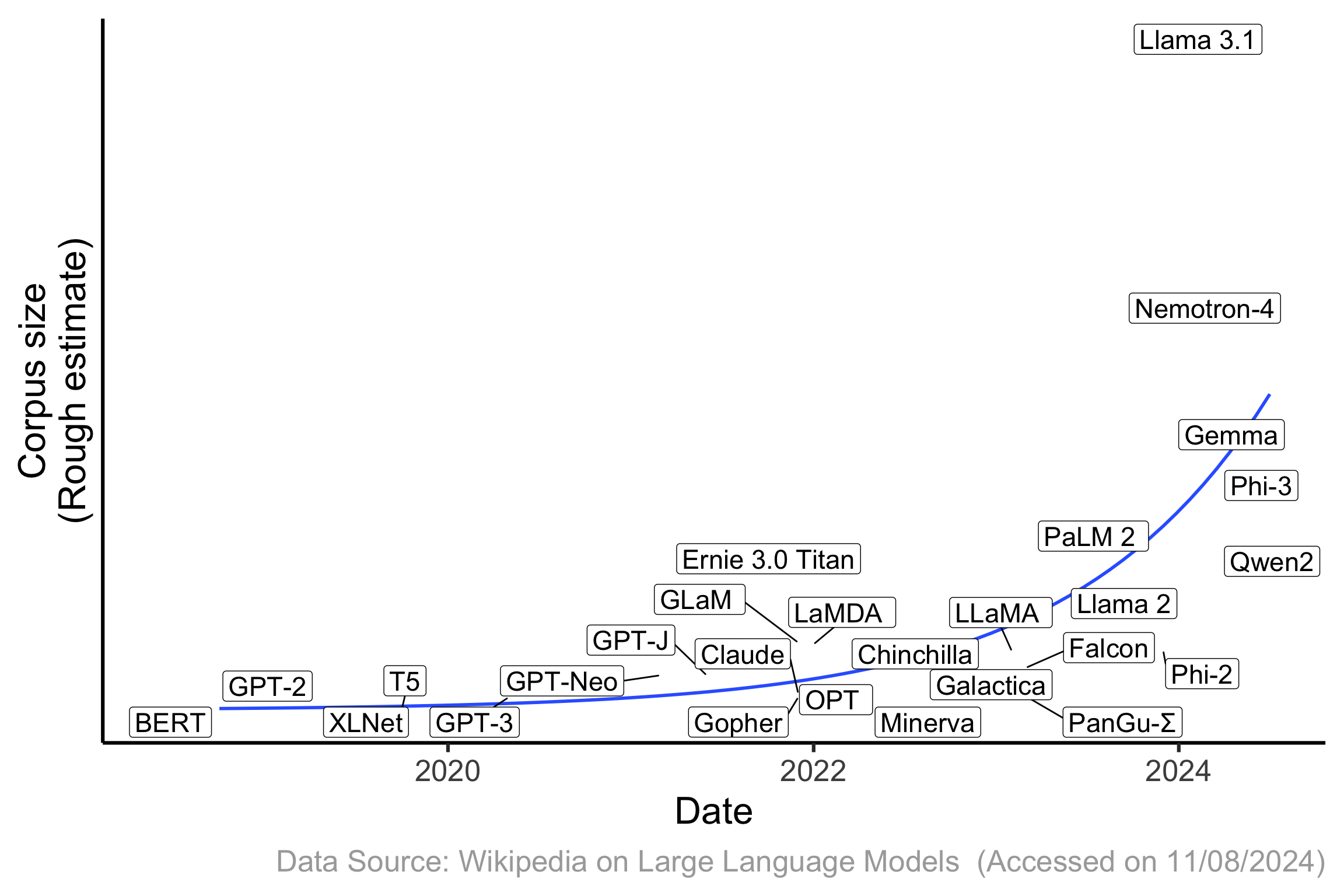
Corpus size used for training increasing over time
- Note: not all vendors publicly document their corpus size for training.
Embeddings
- Language modelling typically use (token) embeddings.
- Embedding models convert items to numerical vectors such that similar items are closer together than dissimilar items based on this embedding space.
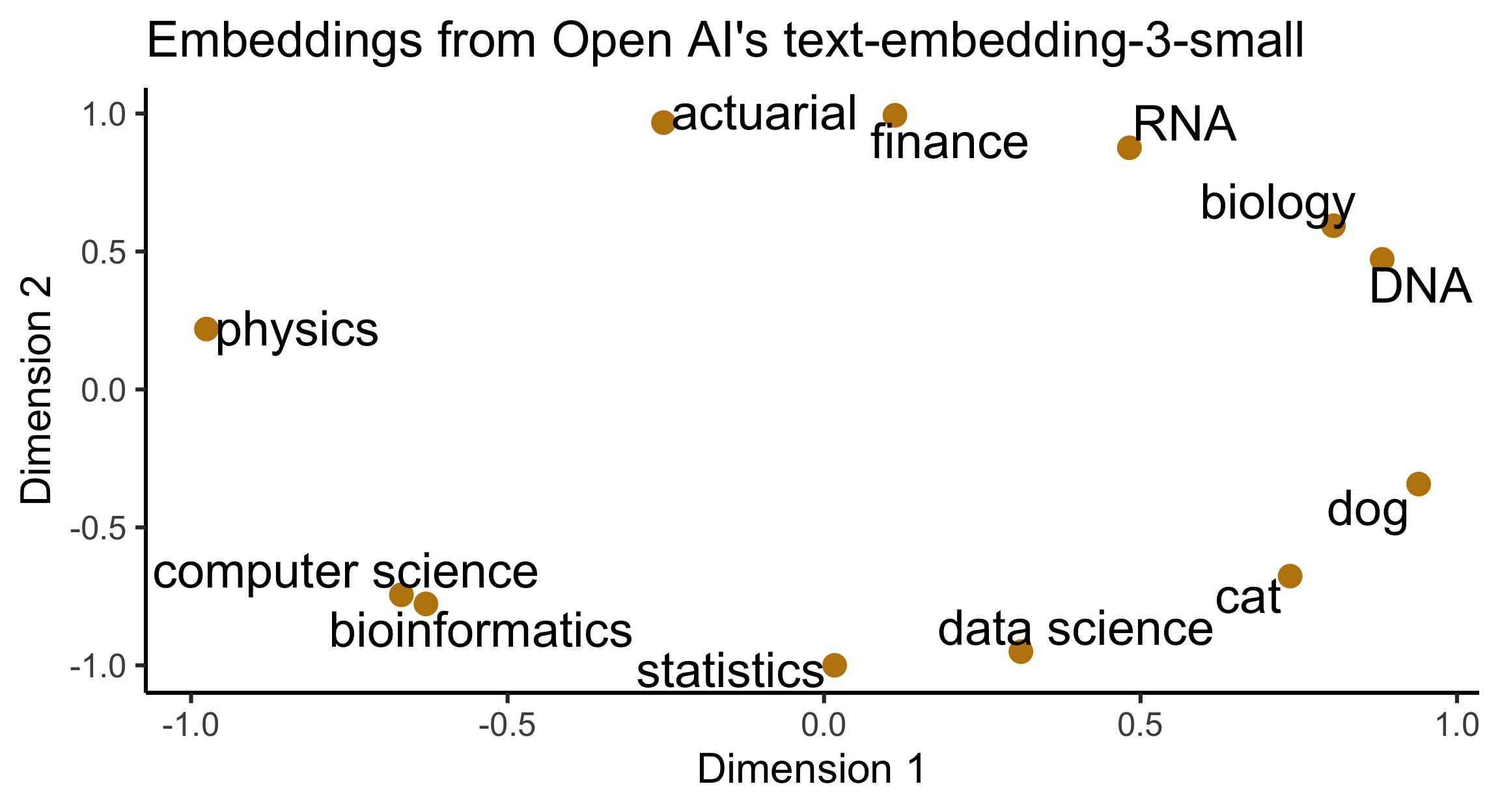
- Text embedding models are often based on artificial neural networks.
Feed forward neural network
- Feed forward neural networks, also called deep neural networks, add more hidden layers.
- The output depends on the parameters, \boldsymbol{\theta} = (\underbrace{\boldsymbol{b}^\top}_{\text{biases}},\underbrace{\boldsymbol{w}^\top}_{\text{weights}})^\top.
- The number of parameters increases exponentially with more layers, but you gain flexibility in modelling.
- These parameters are calibrated (or trained) by:
- Defining an objective (or loss) function (like the mean square error), and
- Finding parameters \boldsymbol{\theta} that optimise this objective function (using techniques like stochastic gradient descent and backpropagation).
Transformer model
- Popular LLM are variants of a pre-trained transformer model.
- The original transformer model1 consist of:
- Input embeddings of current and previous positions
- Positional embeddings
- A stack of transformer blocks (N=6) with each containing:
- An attention layer with multiple attention heads
- Normalisation layers
- Feed forward neural network with 3 hidden layers:
Linear, ReLU, then Linear
- Un-embedding layer (Softmax)
![]()
Positional embeddings
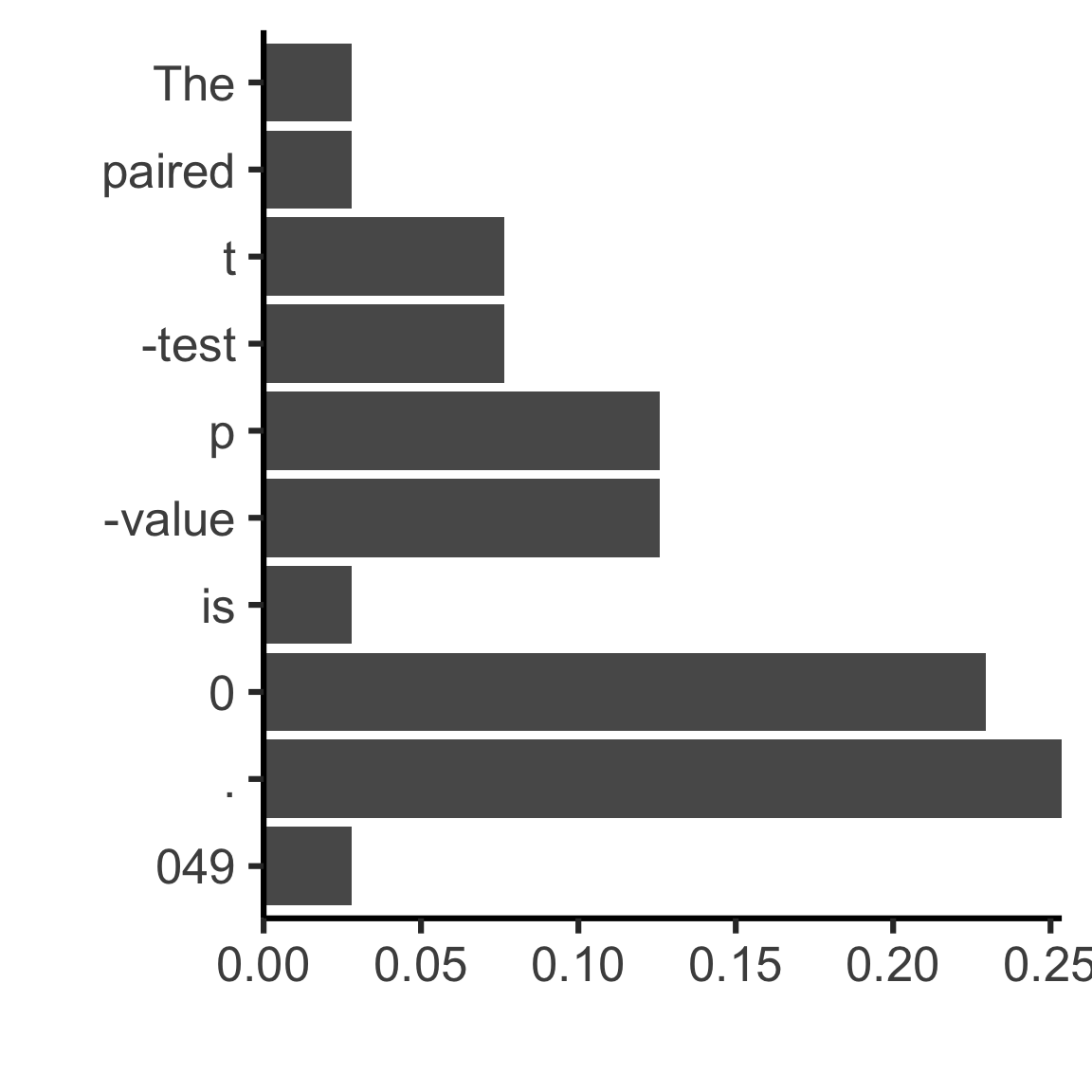
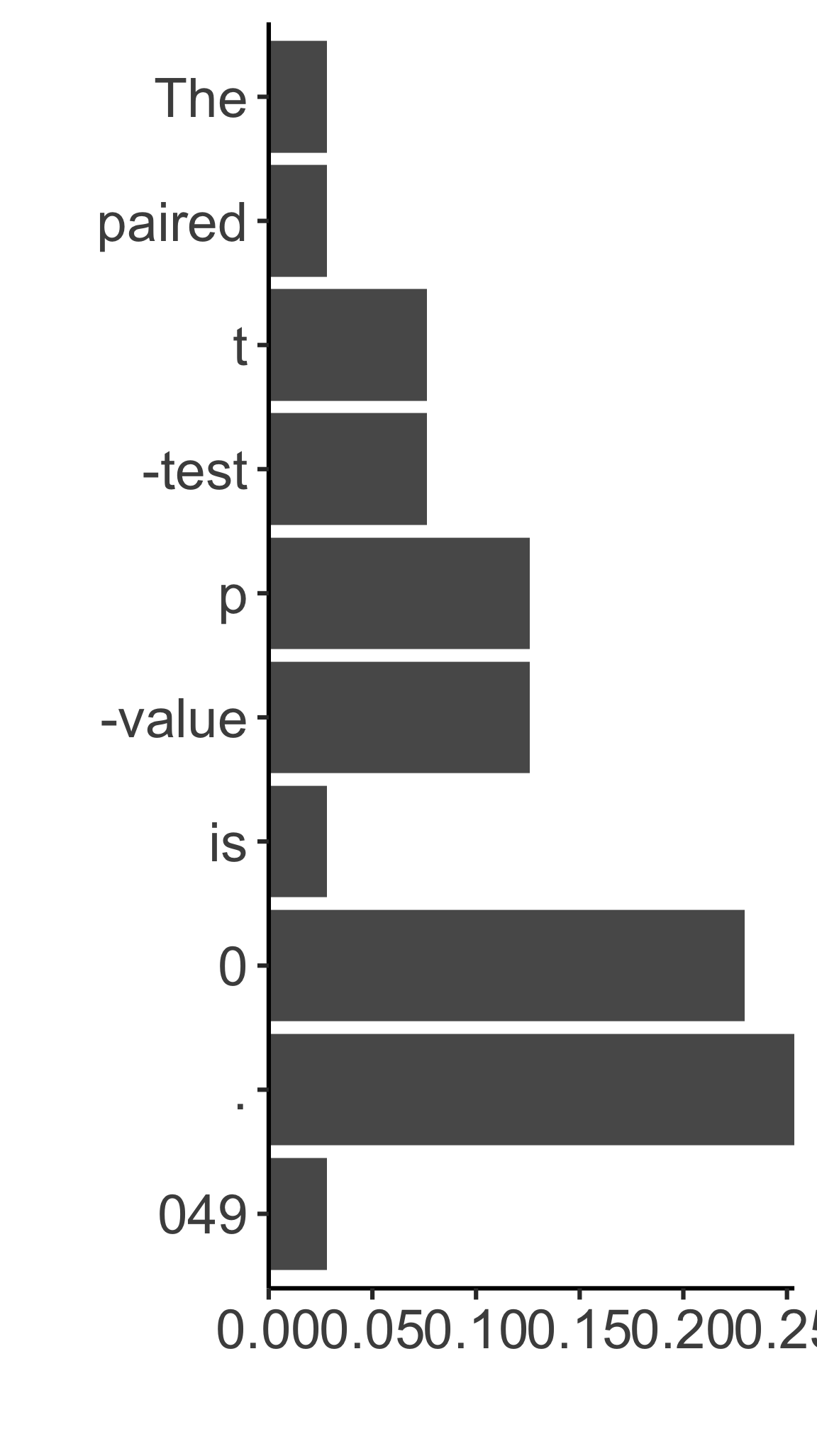
Input The paired t-test p-value is 0.049, so it is statistically significant
Token The paired t -test p -value is 0 . 049 , so it is statistically signicant
- Context length: below 10 (typically much larger, e.g. 4096 for
llama3.1:8b)
The paired t -test p -value is 0 . 049
- Transformer blocks are blind to position of token, so incorporate information about relative or absolute positions of tokens for the subsequent steps.
- Position embedding in the original transformer is represented by unique frequencies and offsets of the wave:

Attention Head: Relevance scoring
- Embedding matrix is multiplied with each of the projection matrices
\times
The query vector of the current position:
=
Result \rightarrow Softmax(Result)
Attention Head: Combining information
\times
=
Sum above and the new token embedding that incorporates relevant information from other tokens is:
Summary
Input:
All models are wrong, but some are
Updated input:
All models are wrong, but some are useful
Updated input:
All models are wrong, but some useful.
Tokenizer
Embedding layer
Transformer blocks
(artificial neural network)
Un-embedding layer
| Token | Token ID |
|---|---|
| All | 2594 |
| models | 7015 |
| are | 553 |
| wrong | 8201 |
| , | 11 |
| but | 889 |
Token
Numerical vectors
2594
7015
0553
8201
0011
0889
![]()
| Token ID | Probability |
|---|---|
| 1236 | 0.844 |
| 1991 | 0.004 |
| 12698 | 0.001 |
| ... | ... |
8316 = useful
13 = .
13 = .
XXXX = <|end|>
XXXX = <|end|>
Output: useful.
LLM
Other evaluations
- Human evaluation can involve:
- Accept/Reject of the response
- Scoring the quality of the response on various aspects (e.g. answer relevancy, correctness, hallucination, responsible metrics, and so on).
- Pick preferred response between two responses (reinforcement learning)
- LLM evaluating LLM1: e.g. Prometheus2 uses LLM to evaluate other LLMs
Demo #3
![]()