Landscape of Large Language Models
Introduction to Large Language Models for Statisticians
15th October 2024
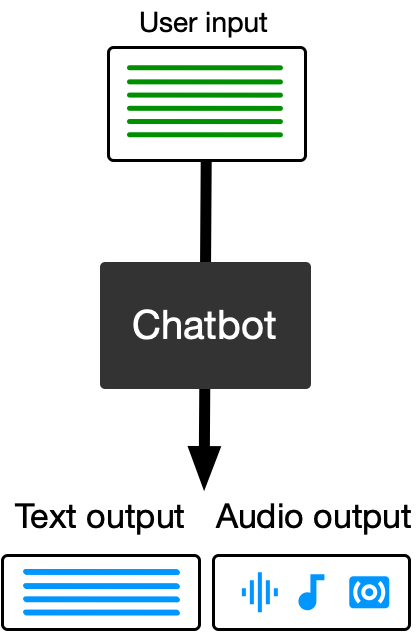
ChatGPT
- ChatGPT was released to public on 30th November 2022.
- ChatGPT gained a staggering 100 million active users in 2 months1.
![]()
ChatGPT Heralds an Intellectual Revolution
25 February 2023
Generative artificial intelligence presents a philosophical and practical challenge on a scale not experienced since the start of the Enlightenment.
A new technology bids to transform the human cognitive process as it has not been shaken up since the invention of printing. The technology that printed the Gutenberg Bible in 1455 made abstract human thought communicable generally and rapidly. But new technology today reverses that process. Whereas the printing press caused a profusion of modern human thought, the new technology achieves its distillation and elaboration. In the process, it creates a gap between human knowledge and human understanding. If we are to navigate this transformation successfully, new concepts of human thought and interaction with machines will need to be developed. This is the essential challenge of the Age of Artificial Intelligence.
…
Mr. Kissinger served as secretary of state, 1973-77, and White House national security adviser, 1969-75. Mr. Schmidt was CEO of Google, 2001-11 and executive chairman of Google and its successor, Alphabet Inc., 2011-17. Mr. Huttenlocher is dean of the Schwarzman College of Computing at the Massachusetts Institute of Technology. They are authors of “The Age of AI: And Our Human Future.” The authors thank Eleanor Runde for her research.
Related concepts
- Overlapping but different focuses often using related methods.
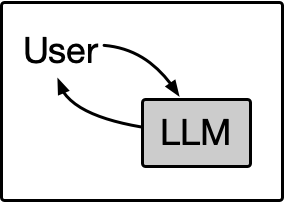
chat with user
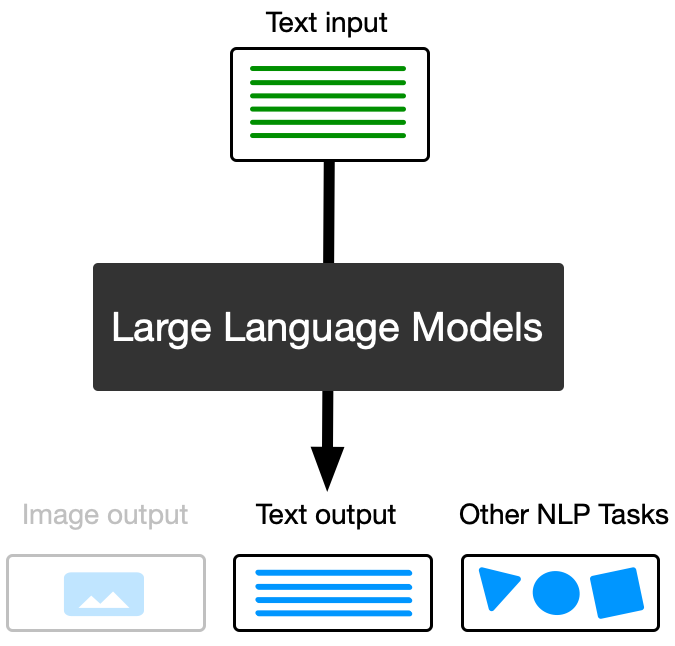
multiple purposes
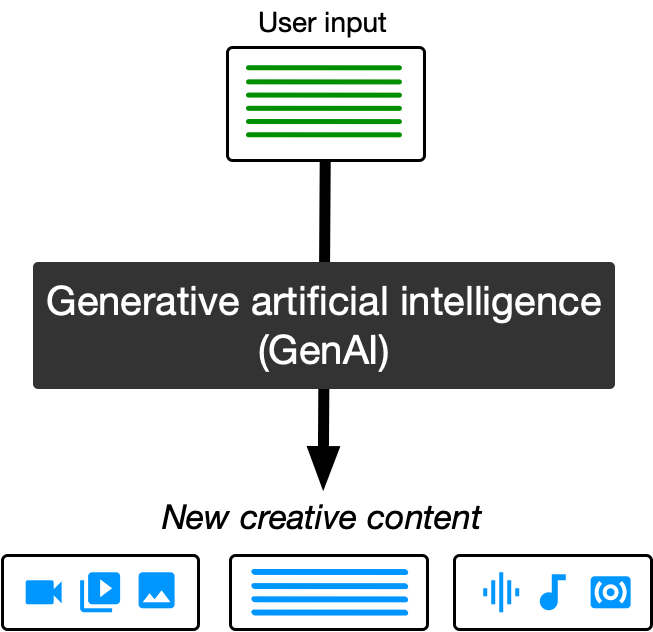
new creative content
- Note: not all LLMs power chatbots and genAI but most do.
- We’ll look at the architecture of LLM later in the workshop.
Using a LLM
Vendor API

![]()


![]()





 …
…
- Requires internet access
- Requires account with vendor
- Ongoing payment for usage
Local LLM
GPT4All LM Studio Jan llama.cpp llamafile Ollama NextChat …
- No internet access required
- No account required
- Several GB of hard disk space required
- At least 16GB RAM required for 7b parameter LLMs
chatgpt-4o-latestgpt-4ogpt-4o-minigpt-3.5-turbodall-e-3text-embedding-ada-002tts-1-hdwhisper-1- …
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'![]() Ollama
Ollama
 Ollama
Ollamallama3.2:1bllama3.2:3bllama3.1:8bllama3.1:70bllama3.1:405bgemma2:2bgemma2:9bgemma2:27bllava:7b- …
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2:1b",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
- Pricing: FREE.
- The model name has a suffix with the number of parameters, e.g.
llama3.1:8bhas about 8 billion parameters. - Larger number of parameters requires larger RAM (~16GB RAM required for 7b).
🤔 Pondering
(for later)
How do LLMs complement or hinder statistical thinking?
What role should LLMs play in decision-making processes and research?
How will LLMs impact the training and development of future statisticians and data scientists?
What are the use cases of LLM for you (if any)?
![]()