Illustrative example
- Suppose that we have a regression problem that require callibration of one hyperparameter with MSE loss function.
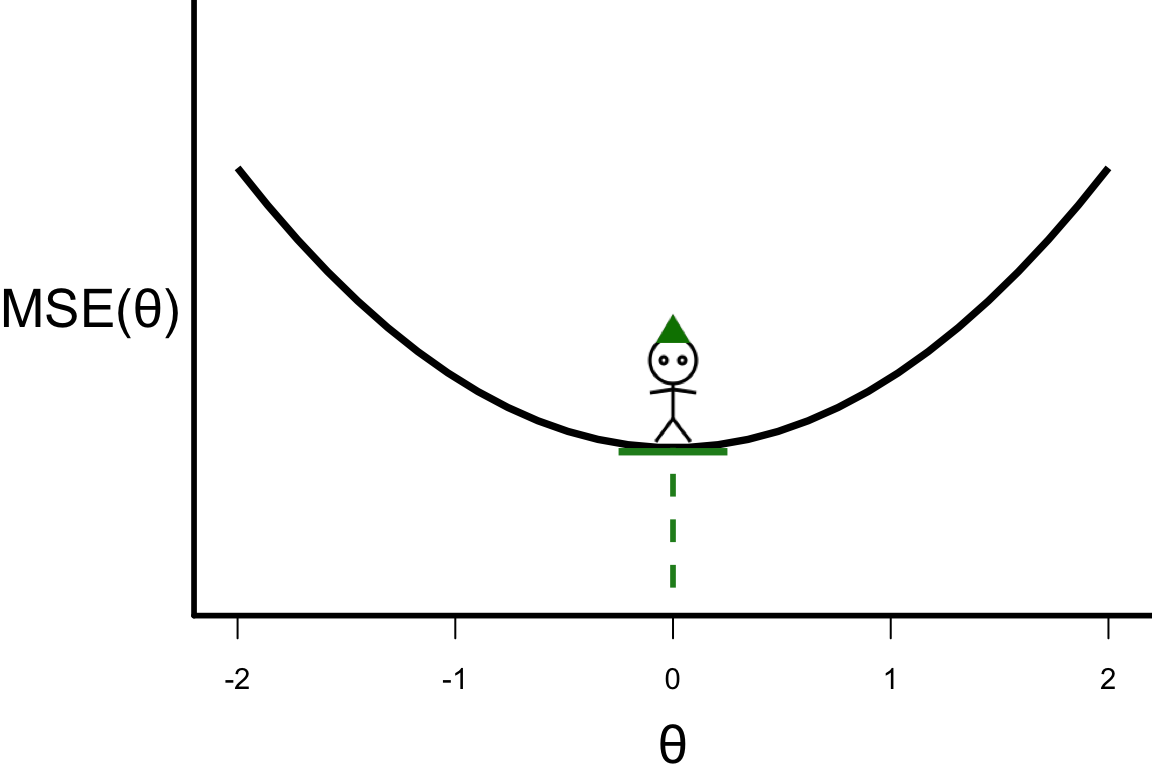
- Our goal is to find \theta that corresponds to the bottom of the curve.
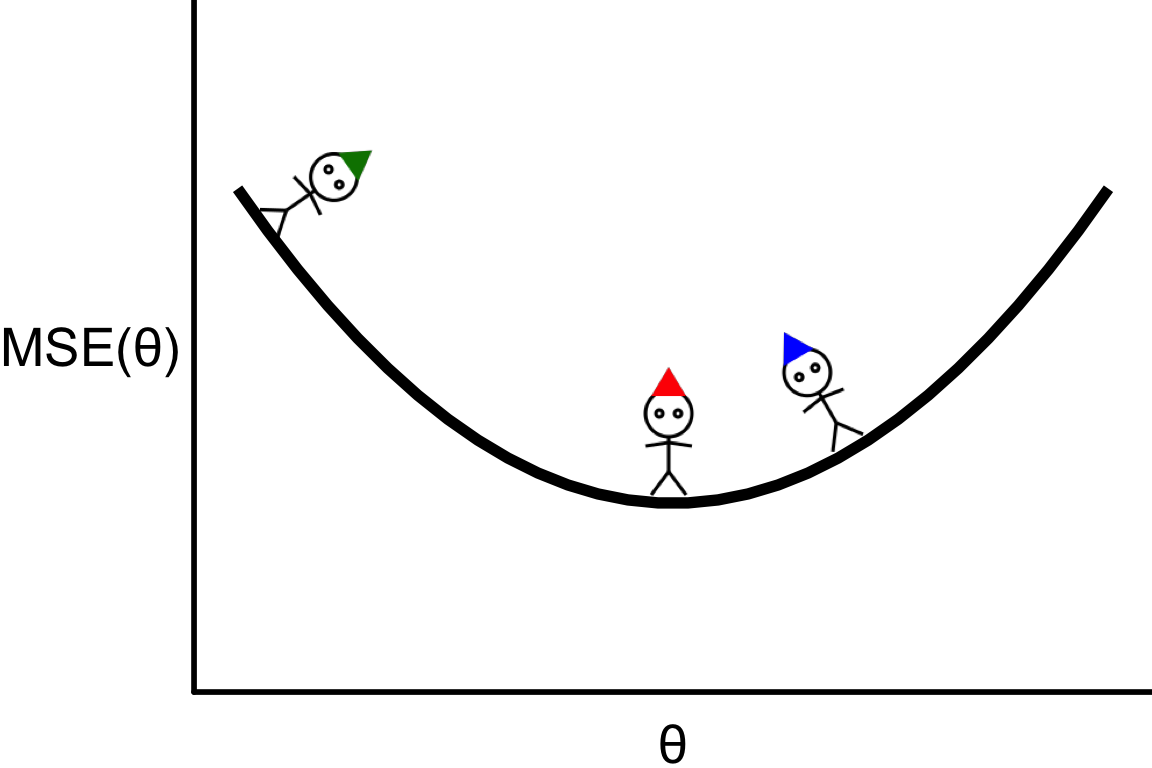
Finding the zero slope
- Suppose that we calculate \text{MSE}(\theta) for three values of \theta.
- For this function, the optimal \theta is where the individual with the red hat is.
- This is also where the slope (or derivative) is zero: \frac{\partial \text{MSE}(\theta)}{\partial \theta} = 0.
Searching for the optimal value
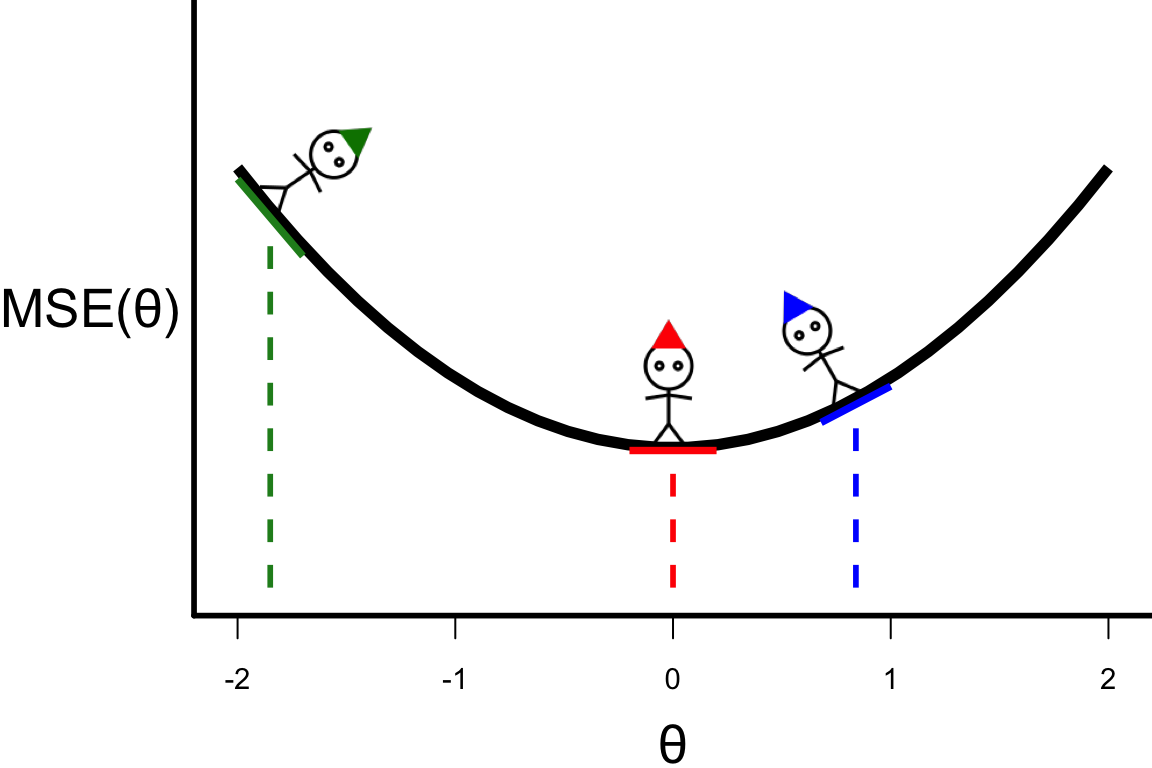
- To search for the optimal value of \theta, we choose some starting points.
- We can calculate the slope at the starting points giving us a guide where to search next: \theta^{[s+1]} = \theta^{[s]} - r \left.\frac{\partial\text{MSE}(\theta)}{\partial\theta}\right\vert_{\theta=\theta^{[s]}}, where r > 0 is the length of the step.
Illustrative example: Step 0
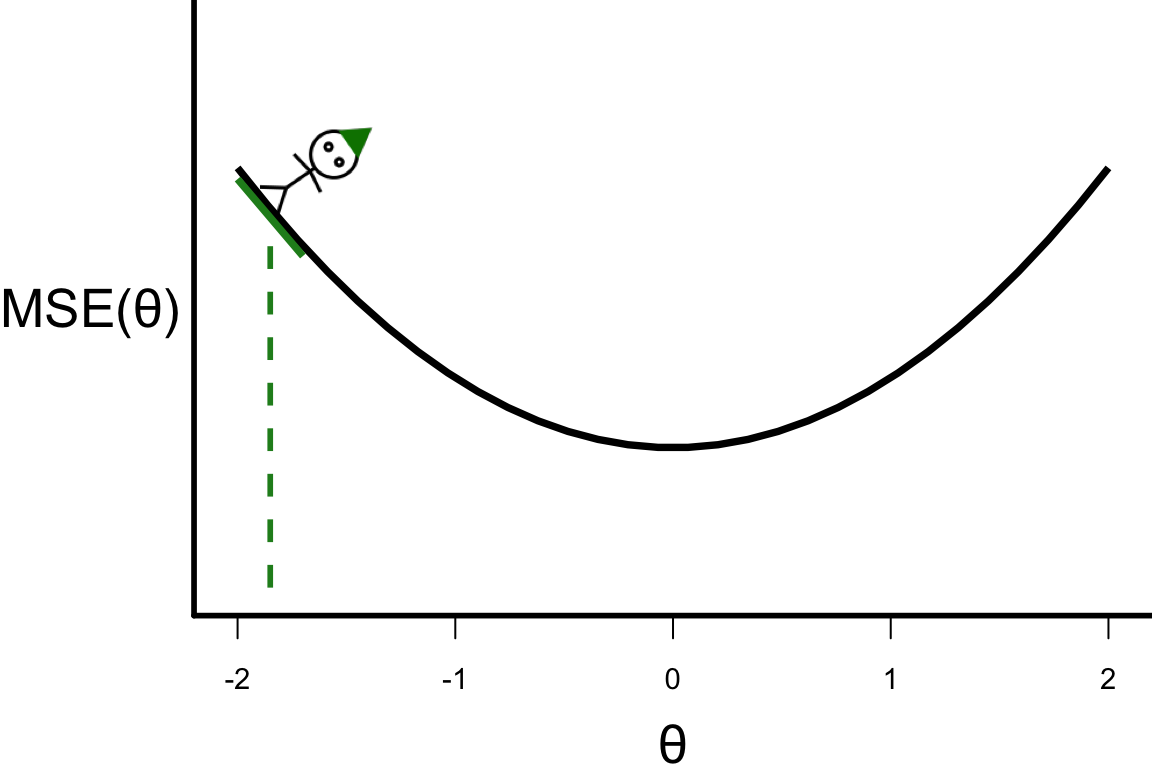
\theta^{[s+1]} = \theta^{[s]} - r \left.\frac{\partial\text{MSE}(\theta)}{\partial\theta}\right\vert_{\theta=\theta^{[s]}}
- Suppose
- \frac{\partial\text{MSE}(\theta)}{\partial\theta} = 4\theta,
- r = 0.1, and
- the starting point \theta^{[0]} = -1.8.
- \theta^{[1]} = -1.8 - 0.1 \times 4 \times (-1.8) = -1.08.
Illustrative example: Step 1
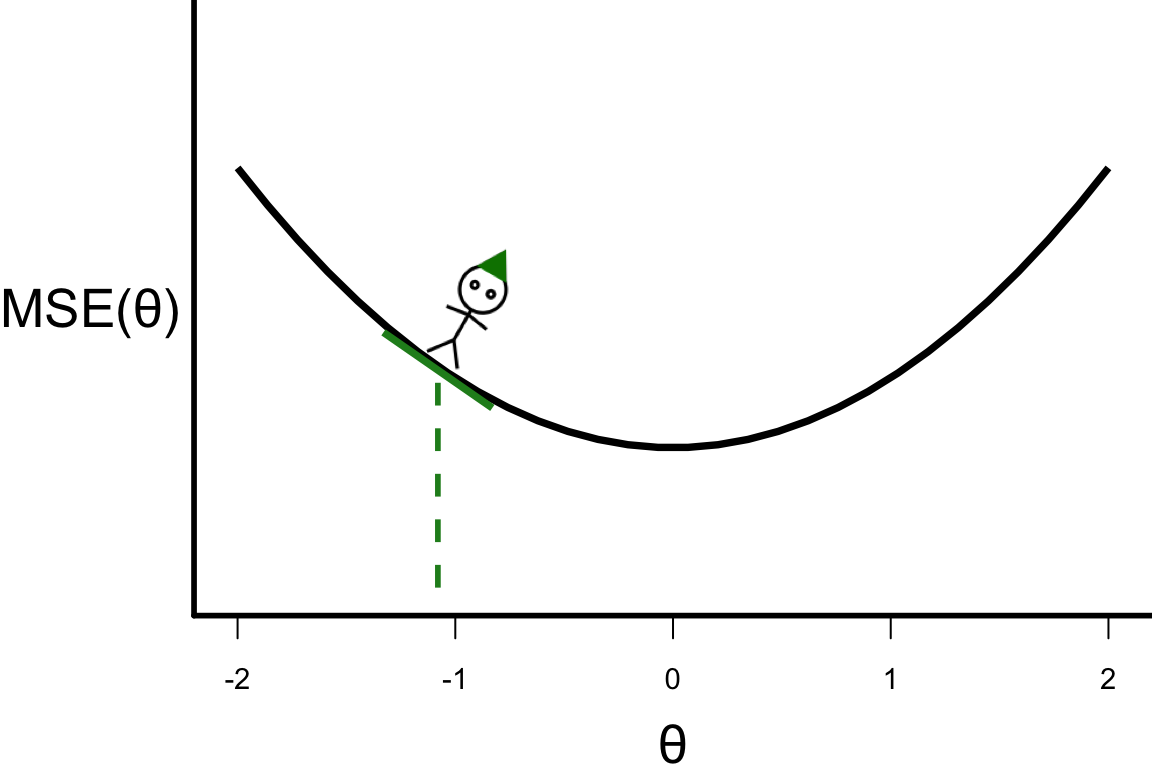
\theta^{[s+1]} = \theta^{[s]} - r \left.\frac{\partial\text{MSE}(\theta)}{\partial\theta}\right\vert_{\theta=\theta^{[s]}}
- \theta^{[1]} = -1.08
- \theta^{[2]} = -1.08 - 0.1 \times 4 \times (-1.08) = -0.648.
Illustrative example: Step 2
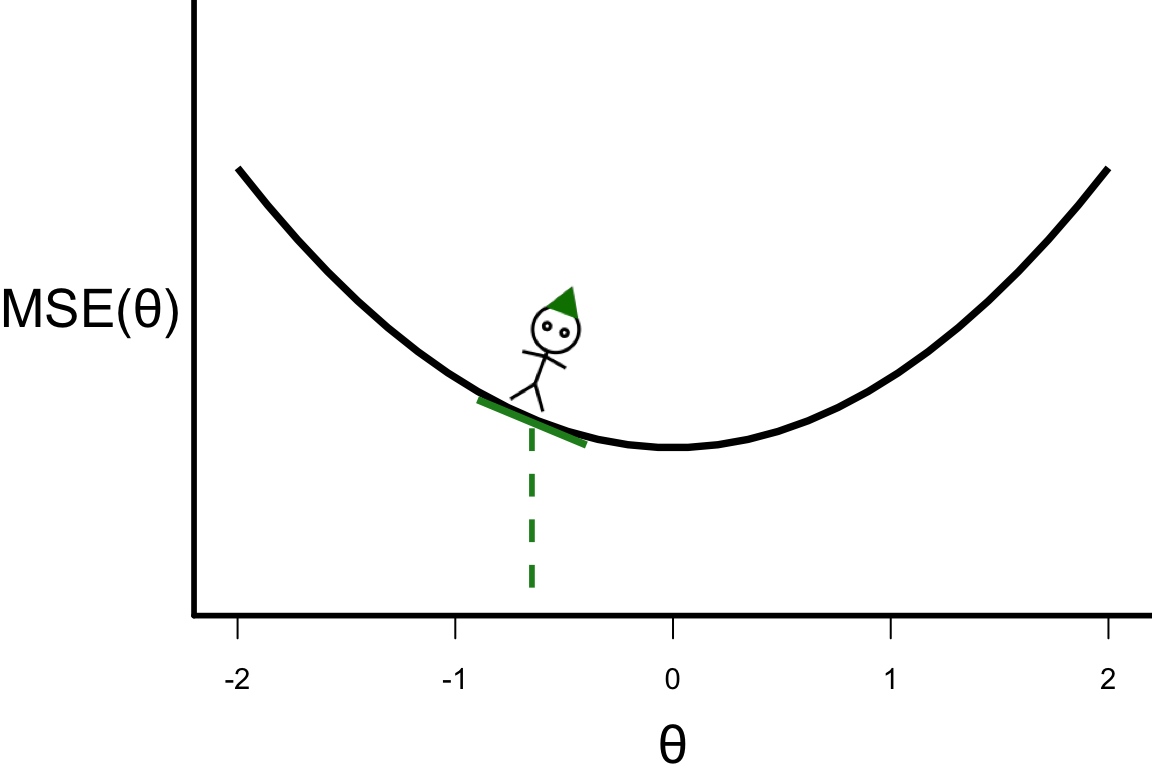
\theta^{[s+1]} = \theta^{[s]} - r \left.\frac{\partial\text{MSE}(\theta)}{\partial\theta}\right\vert_{\theta=\theta^{[s]}}
- \theta^{[2]} = -0.648
- \theta^{[3]} = -0.648 - 0.1 \times 4 \times (-0.648) = -0.3888.
Illustrative example: Step 3
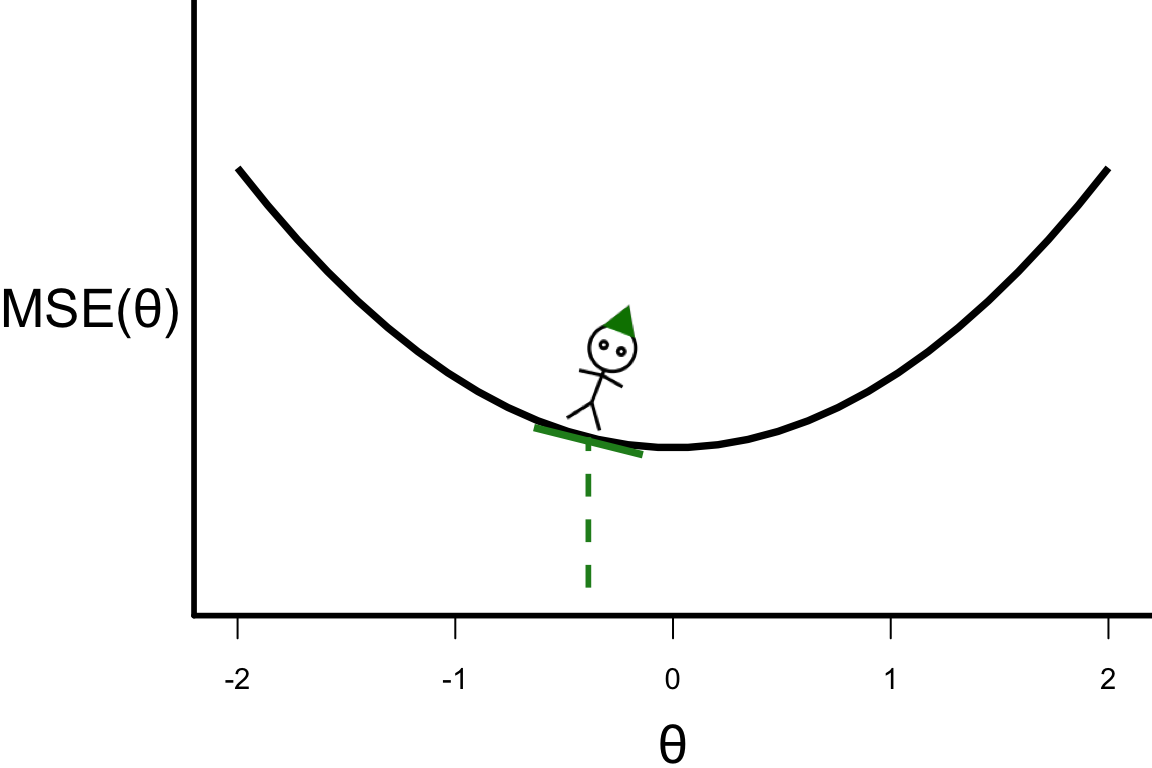
\theta^{[s+1]} = \theta^{[s]} - r \left.\frac{\partial\text{MSE}(\theta)}{\partial\theta}\right\vert_{\theta=\theta^{[s]}}
- \theta^{[3]} = -0.3888
- \theta^{[4]} = -0.3888 - 0.1 \times 4 \times (-0.3888) = -0.23328
Illustrative example: Step 4
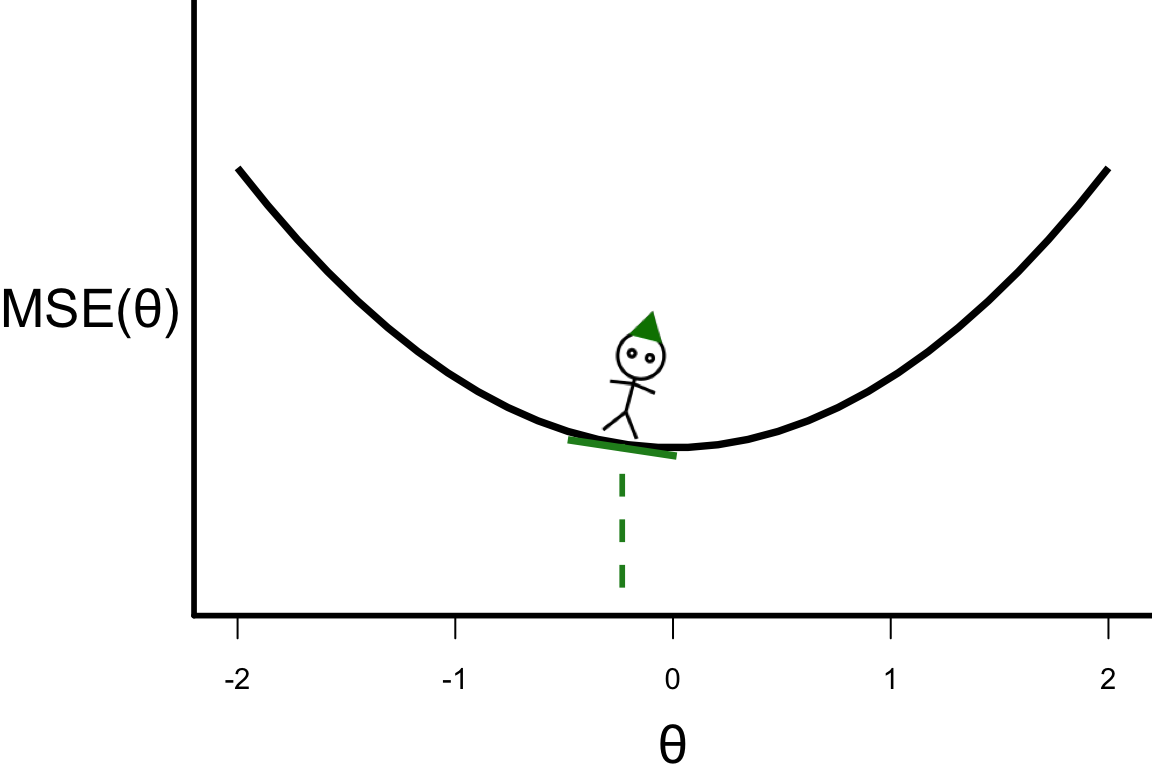
\theta^{[s+1]} = \theta^{[s]} - r \left.\frac{\partial\text{MSE}(\theta)}{\partial\theta}\right\vert_{\theta=\theta^{[s]}}
- \theta^{[4]} = -0.23328
- \theta^{[5]} = -0.23328 - 0.1 \times 4 \times (-0.23328) = -0.139968
\cdots
Illustrative example: Step 20
\theta^{[s+1]} = \theta^{[s]} - r \left.\frac{\partial\text{MSE}(\theta)}{\partial\theta}\right\vert_{\theta=\theta^{[s]}}
- \theta^{[20]} = -0.00006581085
- What if there are more than one parameter?
Limitations of gradient descent
- In practice, the loss function generally involves valuation for each observation, e.g. for MSE: \nabla \text{MSE}(\boldsymbol{\theta}) = \frac{1}{n}\sum_{i=1}^n\nabla\left(y_i - f(\boldsymbol{x}_i~|~\boldsymbol{\theta})\right)^2.
- This can be computationally expensive if n is large.
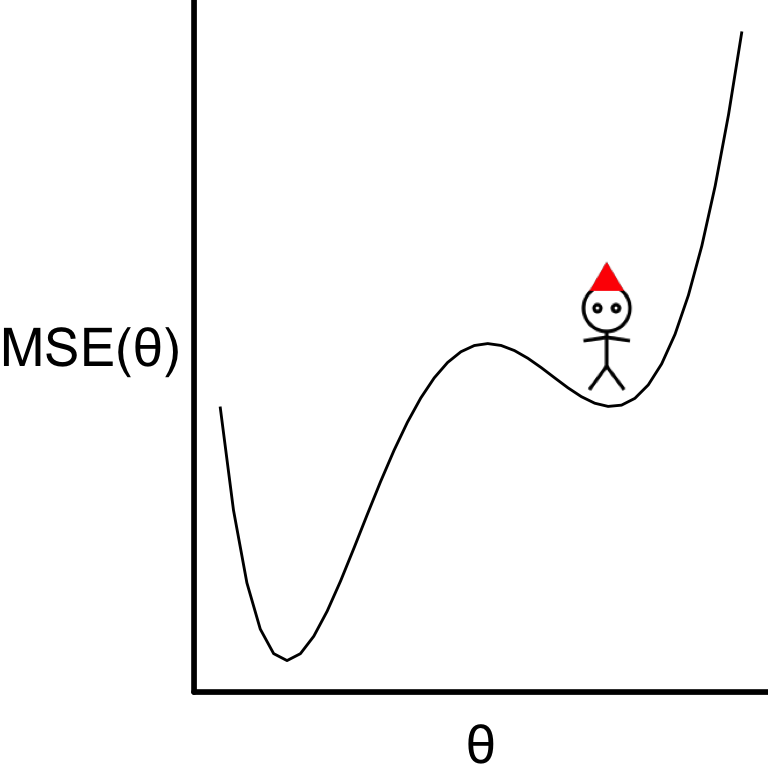
- Gradient descent optimisation can get stuck in local optima.
Fashion MNIST data
scroll
- The fashion MNIST data by Zalando SE contains 28 \times 28 pixel images of fashion items labelled as:
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |

- So this is a multi-class classification problem with m = 10 classes (or levels).
- The training data contains 60,000 observations with 784 variables (
pixel1, …,pixel784) and 1 response variable (label) labelled from 0-9. - The testing data contains 10,000 observations (note: this testing data also contains
label!).
Model diagnostic
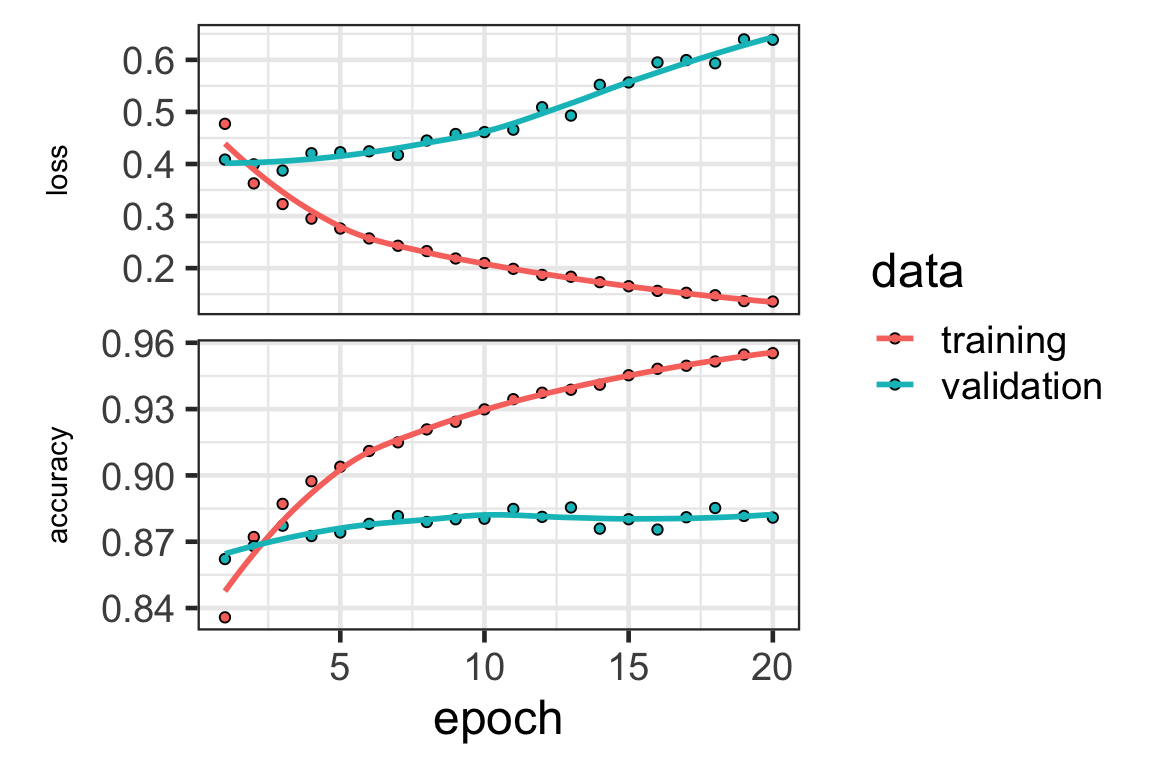
- We can plot the loss (and other metrics specified) of the neural network using the
plotfunction on the training history.
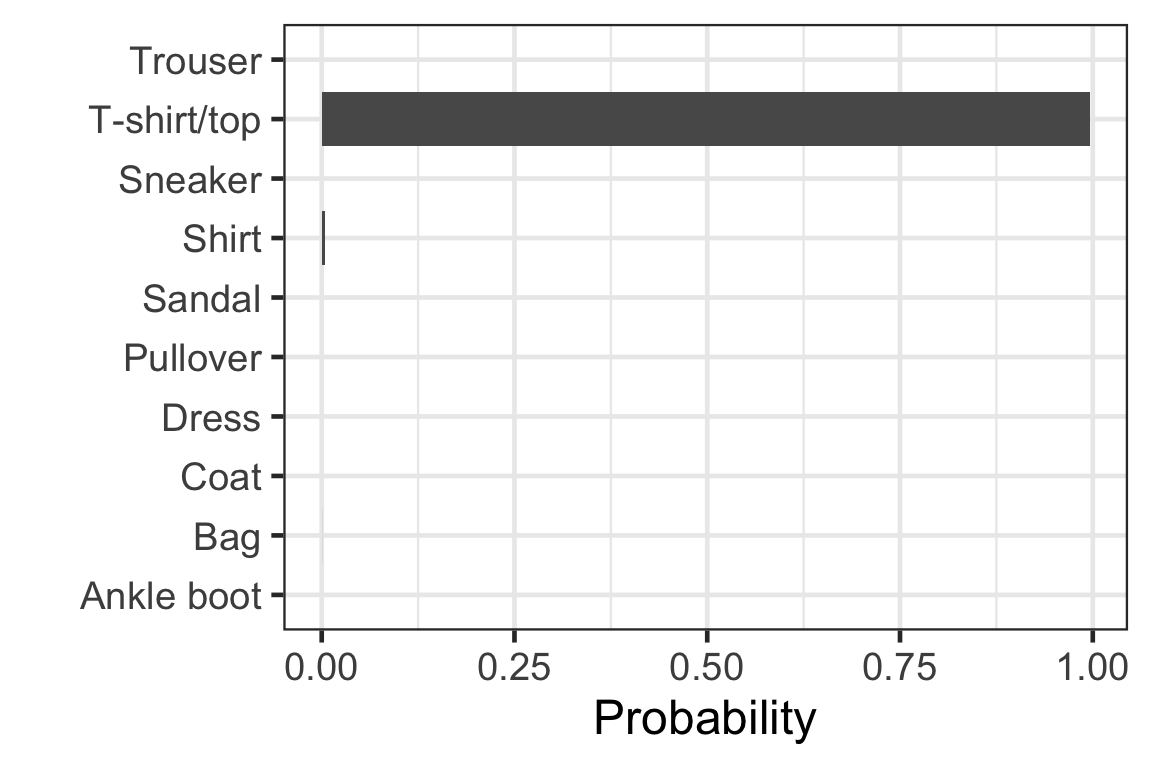
Visually checking the prediction: observation 1

Visually checking the prediction: observation 2

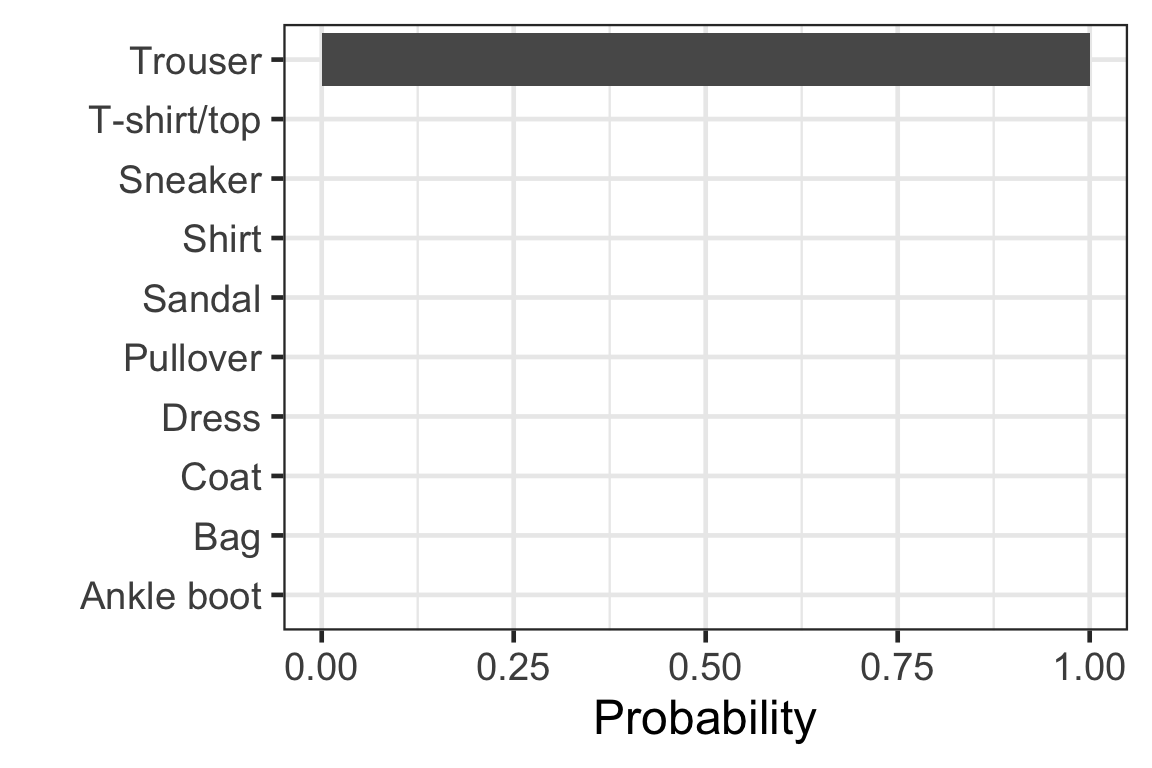
Visually checking the prediction: observation 3

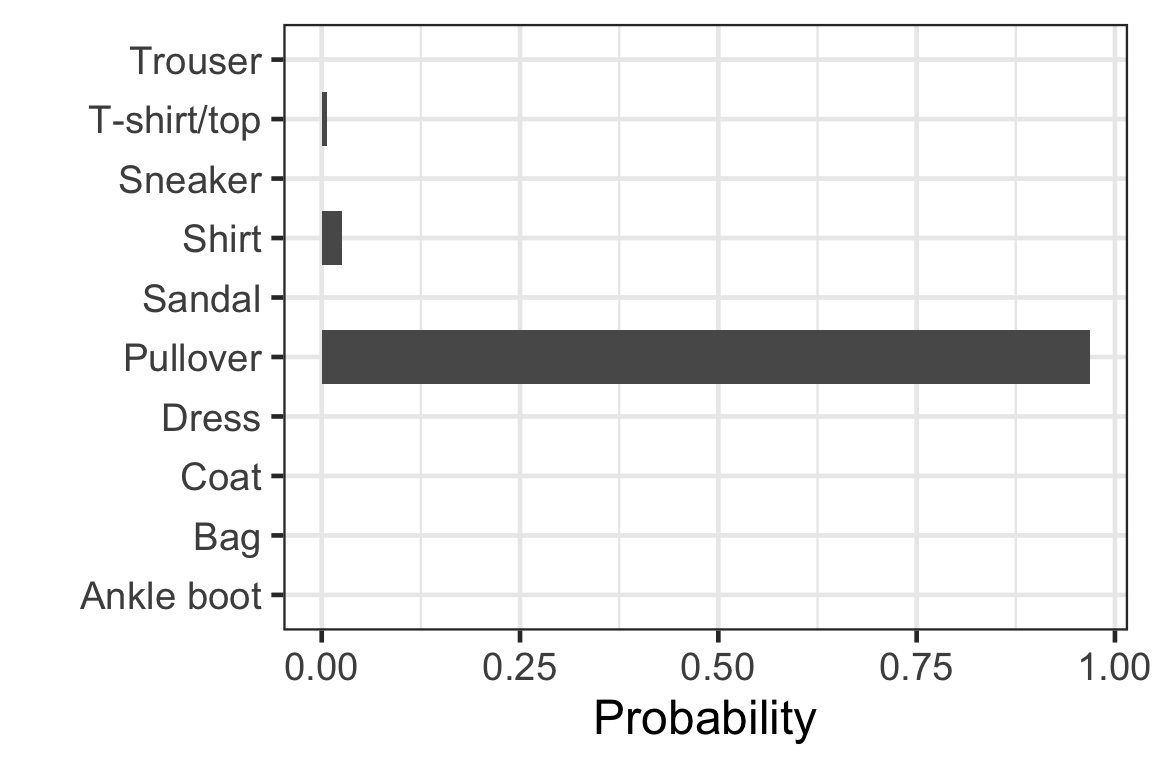
Visually checking the prediction: observation 4

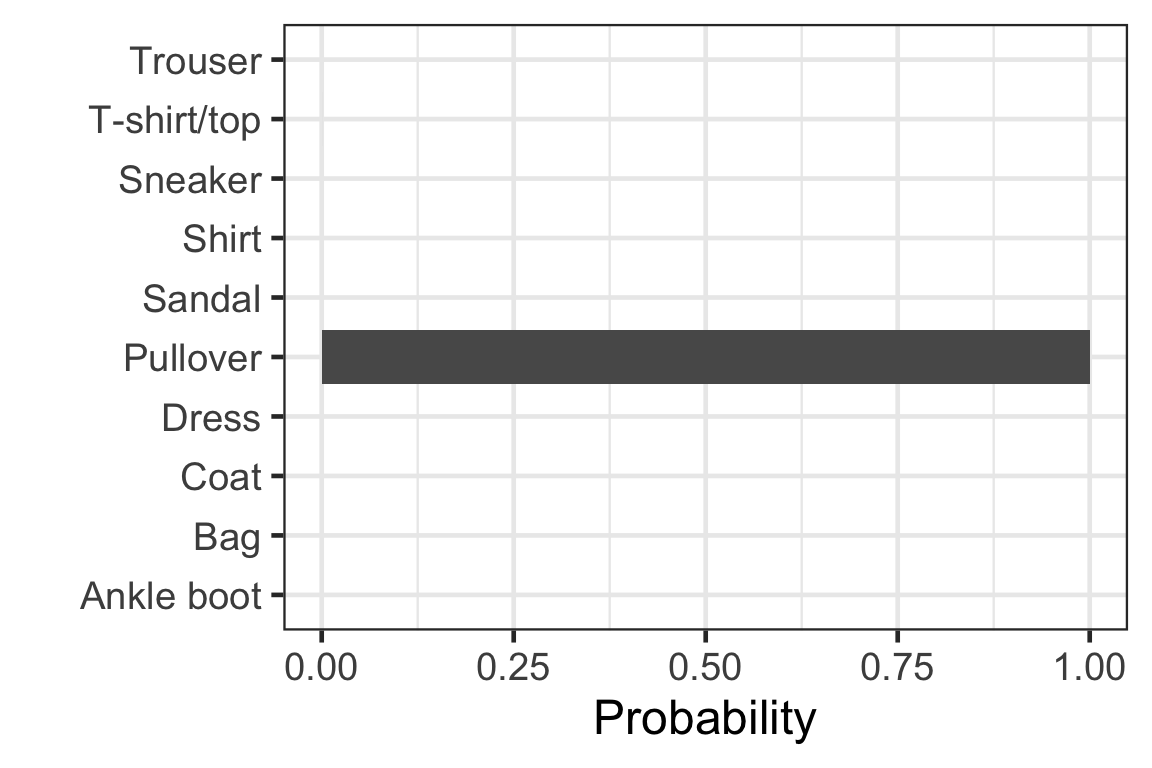
Visually checking the prediction: observation 5

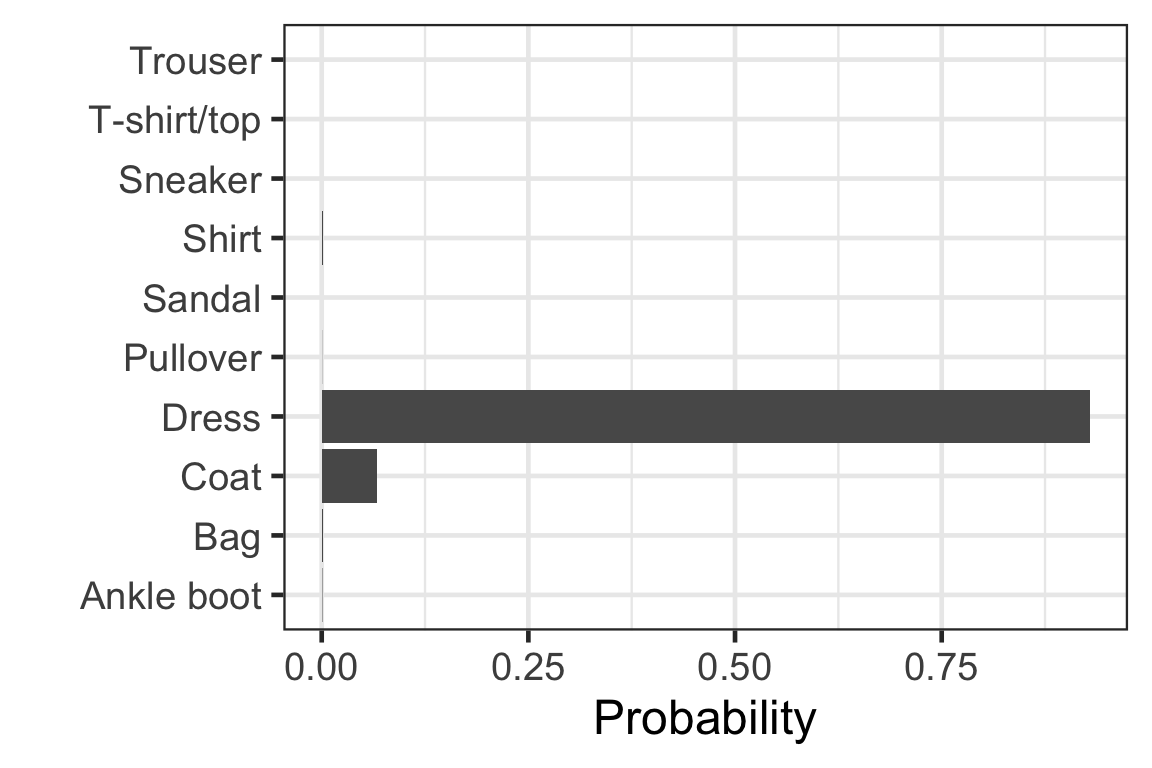
Takeaways
- To build a feed-forward neural network, we need the key components:
- Input data,
- A pre-defined network architecture,
- A feedback mechanism (e.g. loss function) to enable the network to learn, and
- Model training.
- Deep neural networks are faster to calibrate than wide neural networks via stochastic gradient descent and backpropogation algorithms.
