Univariate Normal (Gaussian) distribution
f(x) = \frac{1}{\sqrt{2 \pi} \sigma} \text{exp}~ \left( - \frac{1}{2 \sigma^2} (x - \mu)^2 \right).
Code
tibble(x = seq(-5, 7, length = 100)) %>%
mutate(f1 = dnorm(x, 2, 1),
f2 = dnorm(x, -1, 1),
f3 = dnorm(x, 3, 2)) %>%
pivot_longer(f1:f3, values_to = "f") %>%
ggplot(aes(x, f)) +
geom_line(aes(color = name), linewidth = 1.2) +
labs(y = "f(x)", color = "") +
scale_color_discrete(labels = c("N(2, 1)", "N(-1, 1)", "N(3, 4)"))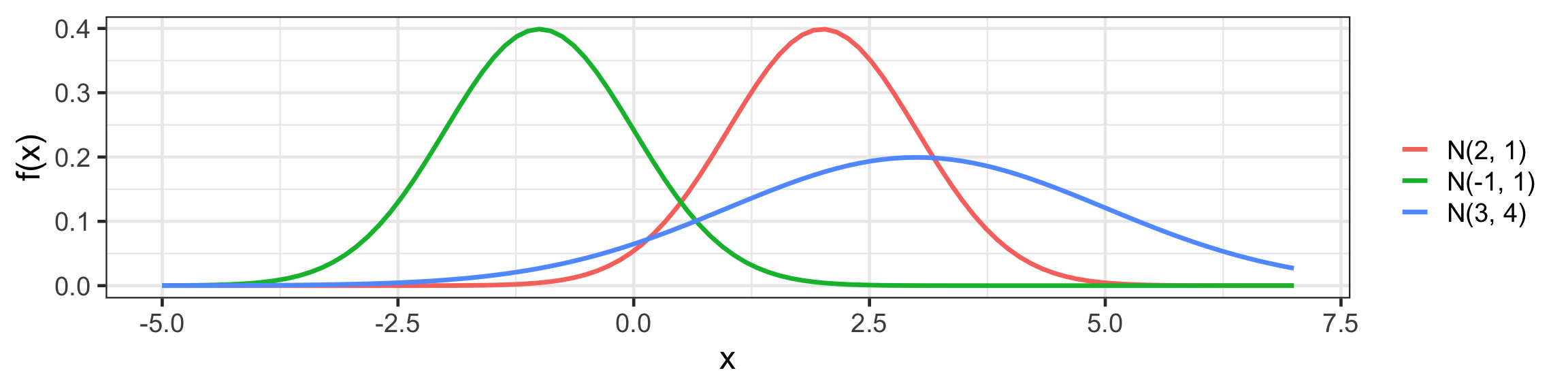
Multivariate Normal (Gaussian) distribution
f(\boldsymbol{x}) = \frac{1}{(2\pi)^{\frac{p}{2}}|\mathbf{\Sigma}|^{\frac{1}{2}}} \exp\left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^\top\mathbf{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right)
- \boldsymbol{\mu} is a p-vector of means, and
- \mathbf{\Sigma} is a p\times p variance-covariance matrix.
Code
expand_grid(x1 = seq(-5, 5, length = 100),
x2 = seq(-5, 5, length = 100)) %>%
rowwise() %>%
mutate(f1 = mvtnorm::dmvnorm(c(x1, x2), mean = c(2, 1), sigma = matrix(c(1, 0.5, 0.5, 1), 2, 2)),
f2 = mvtnorm::dmvnorm(c(x1, x2), mean = c(1, 2), sigma = matrix(c(1, 0, 0, 1), 2, 2)),,
f3 = mvtnorm::dmvnorm(c(x1, x2), mean = c(-1, 1), sigma = matrix(c(2, 0.5, 0.5, 1), 2, 2)),) %>%
pivot_longer(f1:f3, values_to = "f") %>%
ggplot(aes(x1, x2, z = f)) +
geom_contour(aes(color = name), linewidth = 1.2) +
labs(color = "") +
guides(color = "none")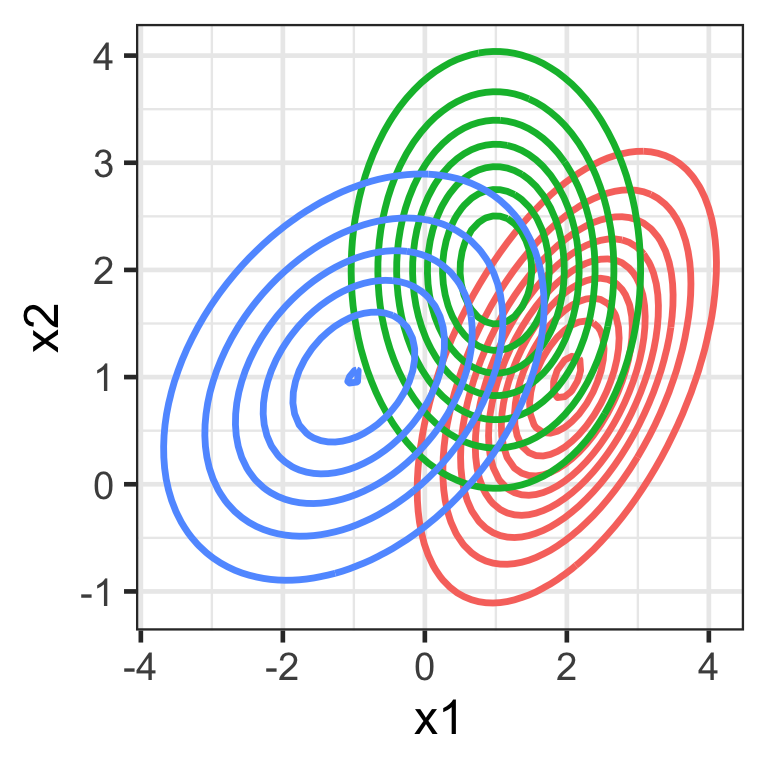
Takeaways
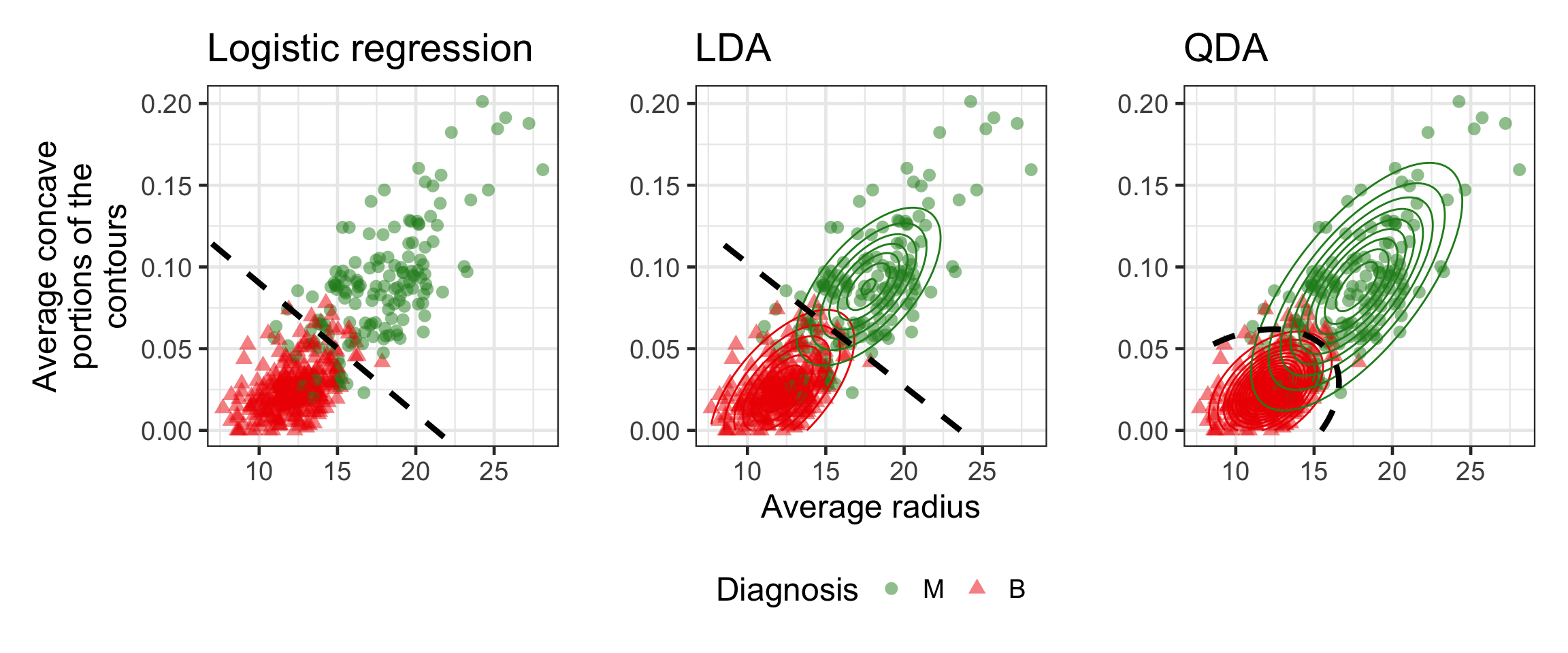
Logistic regression
- Goal: directly estimate P(Y \lvert X)
- Assumptions: no assumptions on predictor space
Discriminant analysis
- Goal: estimate P(X \lvert Y) to then deduce P(Y \lvert X)
- Assumptions: predictors are normally distributed
