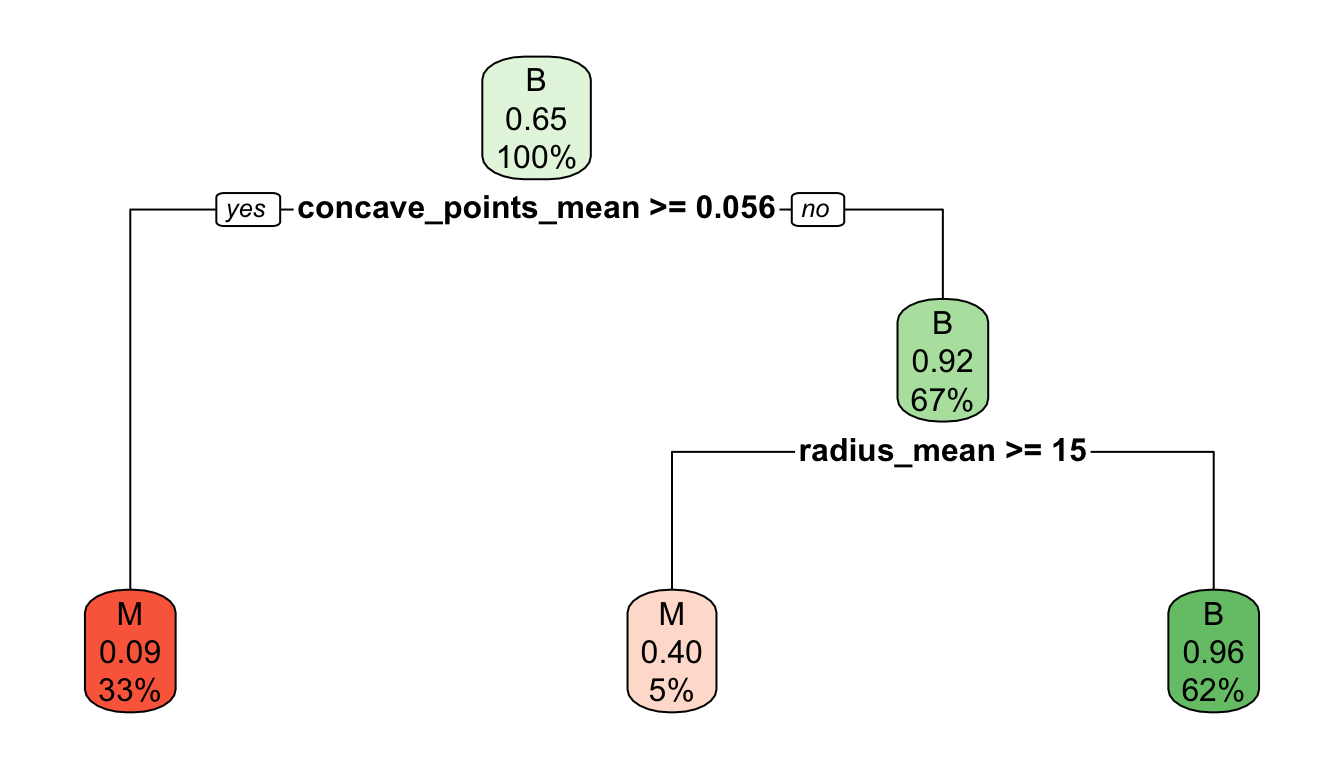
Classification tree
- In a classification tree we use a recursive two-way partition (or branches) of predictors.
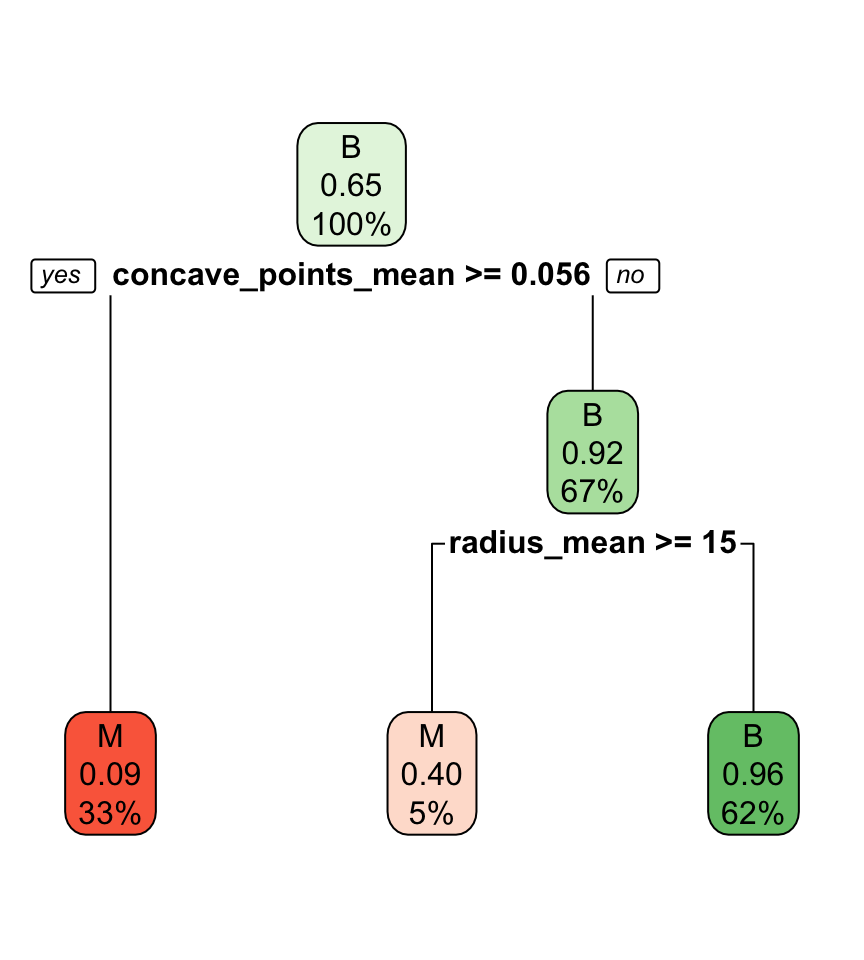
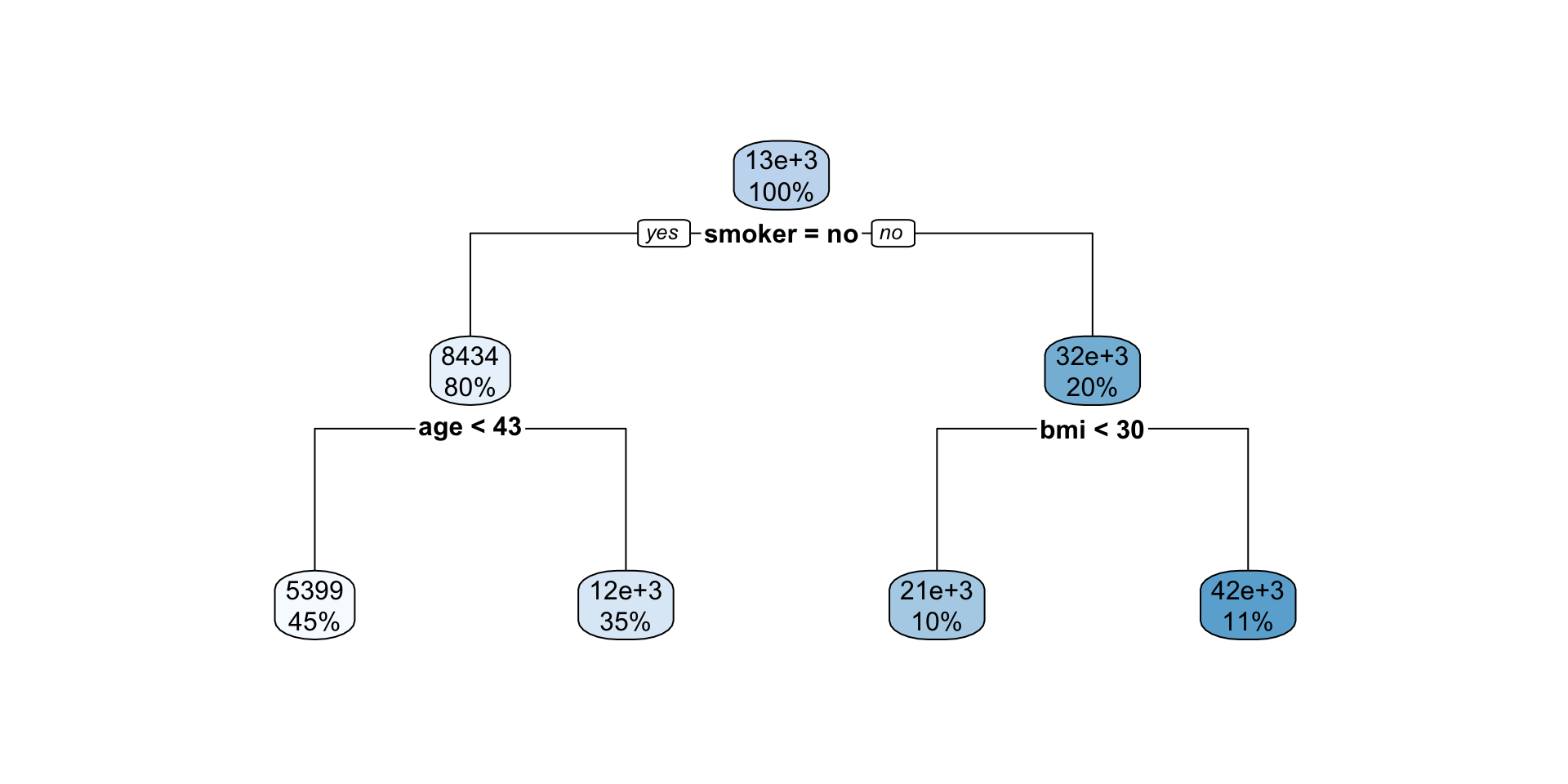
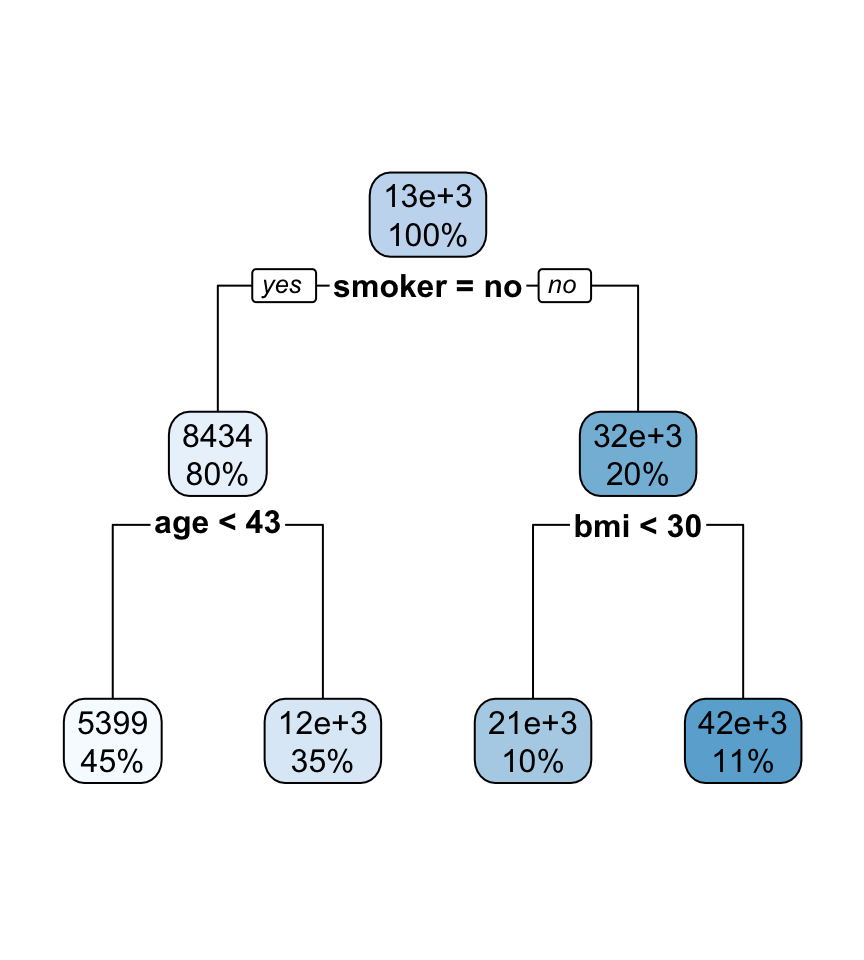
Interpreting classification tree plot
- The rectangles are nodes that contain:
- class identifier,
- proportion of the reference class, and
- percentage of observations in node.
- The bottom rectangles are terminal nodes (or leaves).
- The bold text shows the splitting rules (branches).
- Colors indicate class, with a darker color indicating lower impurity.
Classifying new observations
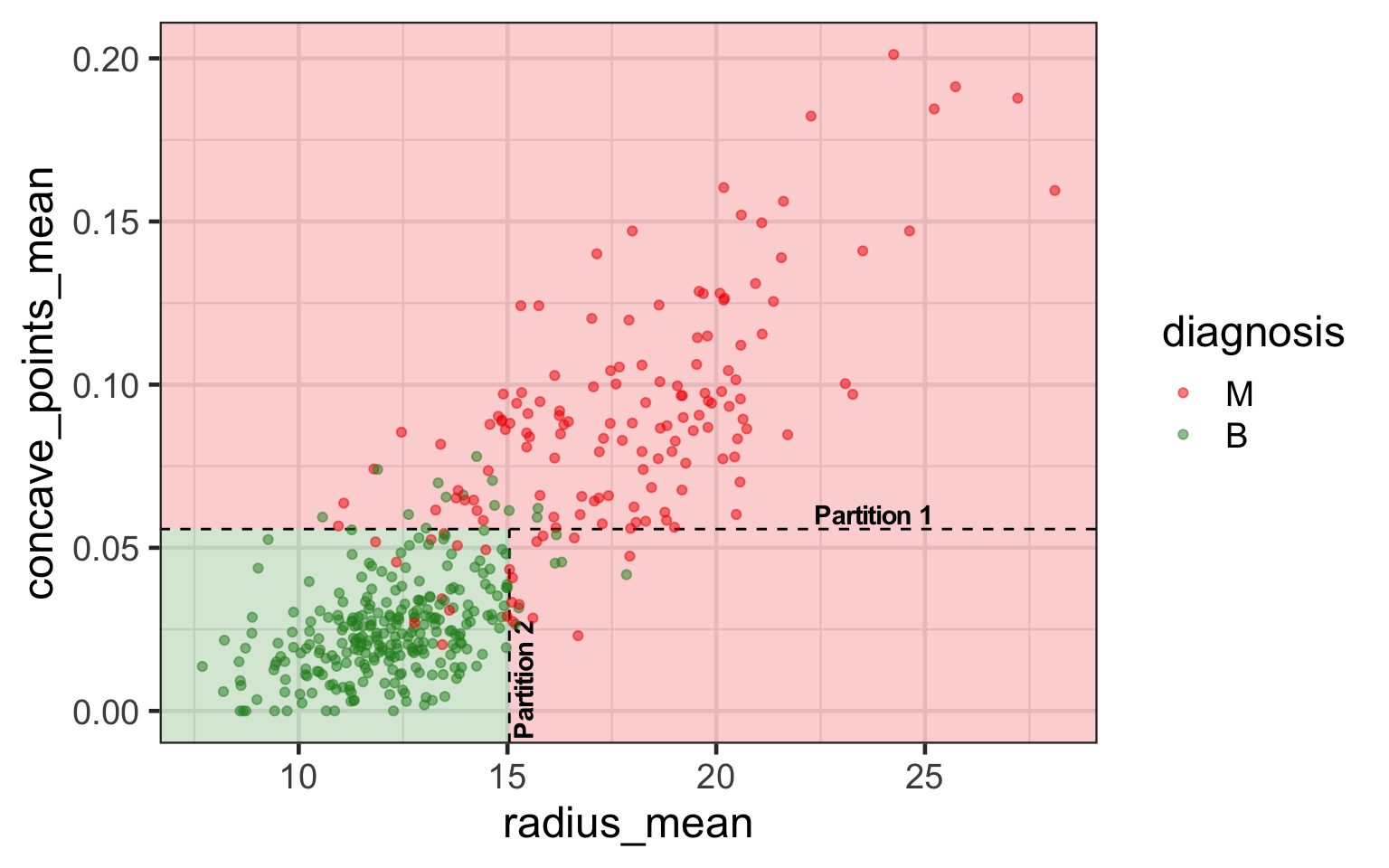
Partition notation
- Suppose s is the value to split in variable j.
- Then we have two sets (or nodes):
- \color{#C8008F}{\mathcal{A}_L} = \{\{y_i, \boldsymbol{x}_i\}:x_{ij}<s\} and
- \color{#027EB6}{\mathcal{A}_R} = \{\{y_i, \boldsymbol{x}_i\}:x_{ij}\geq s\}.
- Different choices of j and s encode different partitions.
- Suppose p_{k\mathcal{A}} is the proportion of observations in class k in a set \mathcal{A}.
| \mathcal{A}_L | \mathcal{A}_R | |
|---|---|---|
| p_{M} | 10.2% (30) | 92.4% (121) |
| p_{B} | 89.8% (265) | 7.6% (10) |
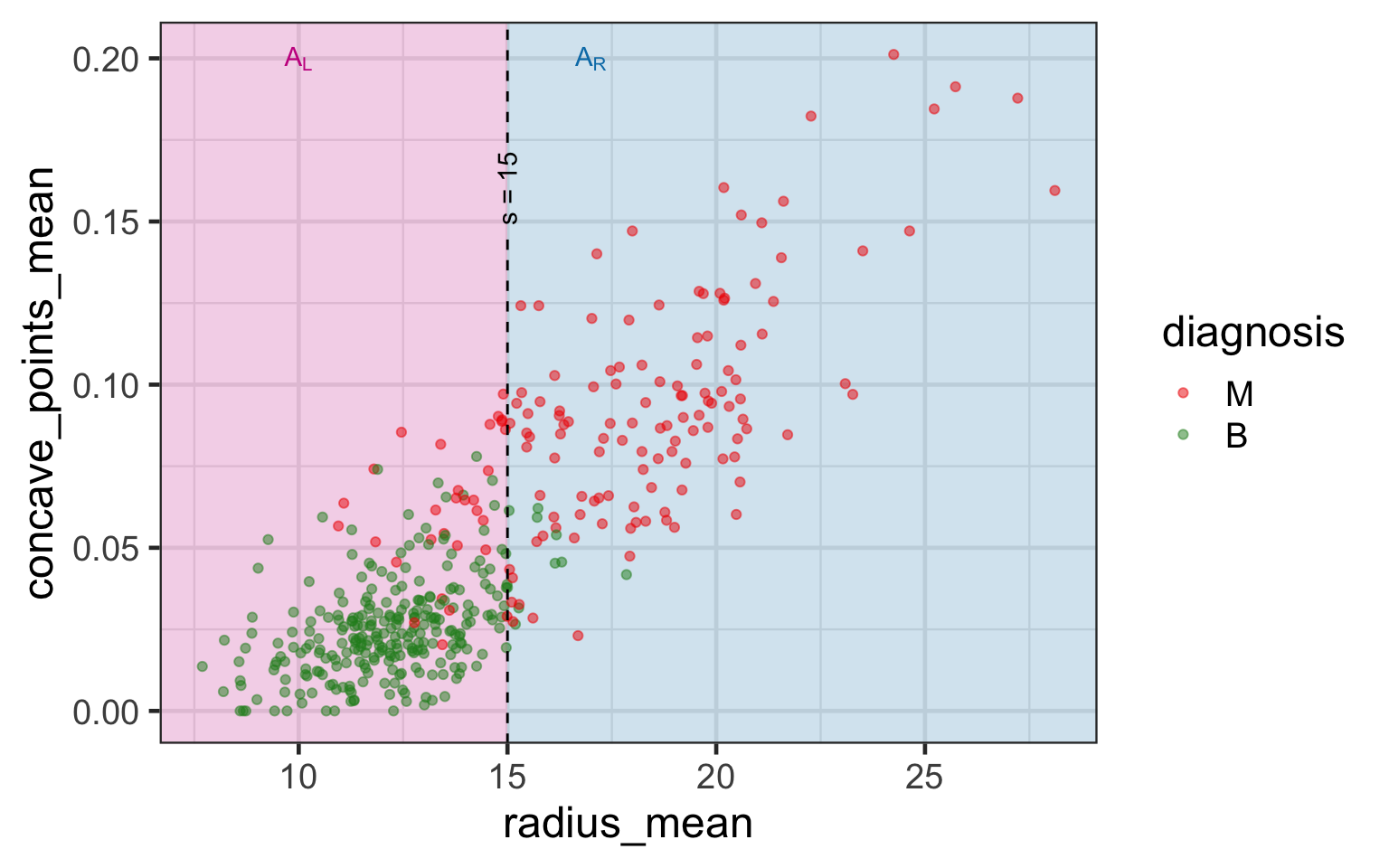
Search for the optimal partition
- The goal is to find j and s such that it minimises the overall impurity: \{j^*, s^*\} = \underset{j\in \{1, \dots, p\}, s \in \mathbb{R}}{\text{argmin}}~\text{Overall impurity}(\mathcal{A}_L, \mathcal{A}_R).
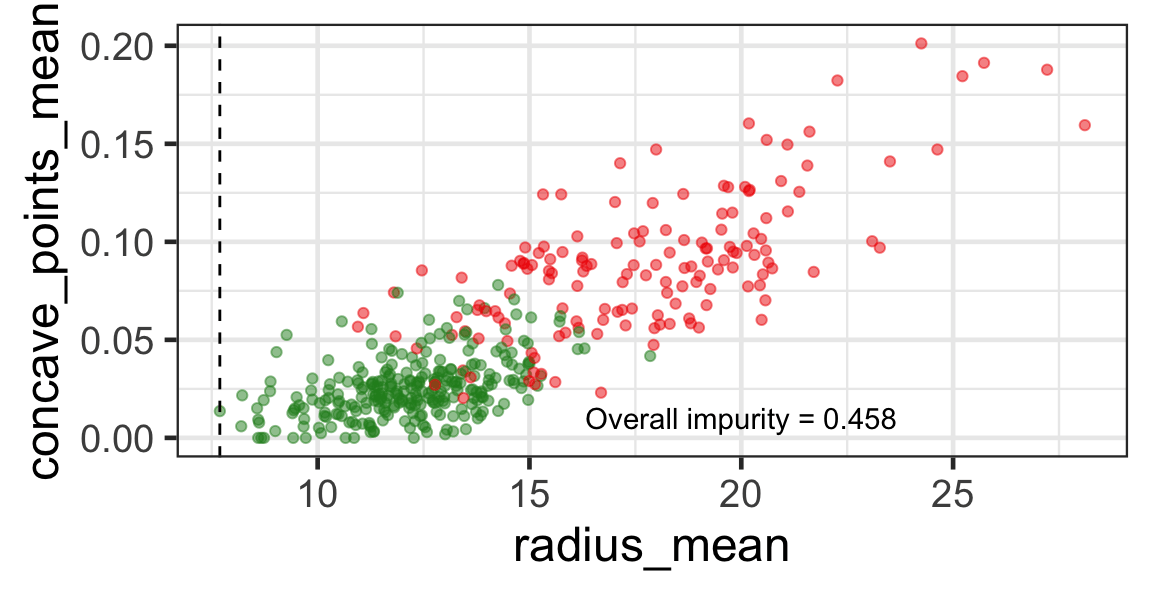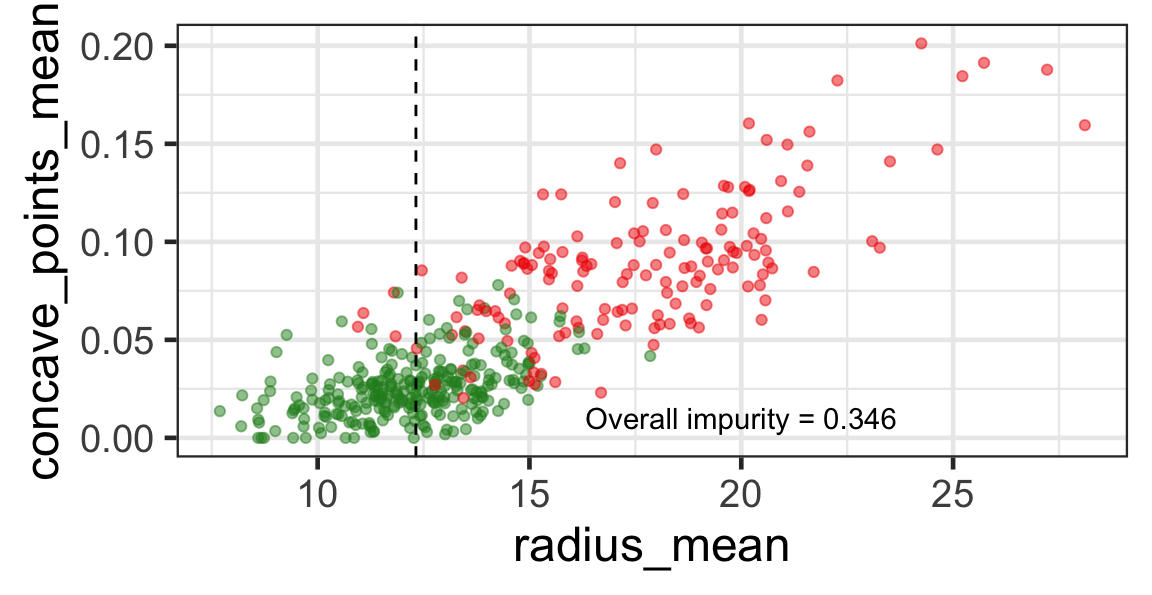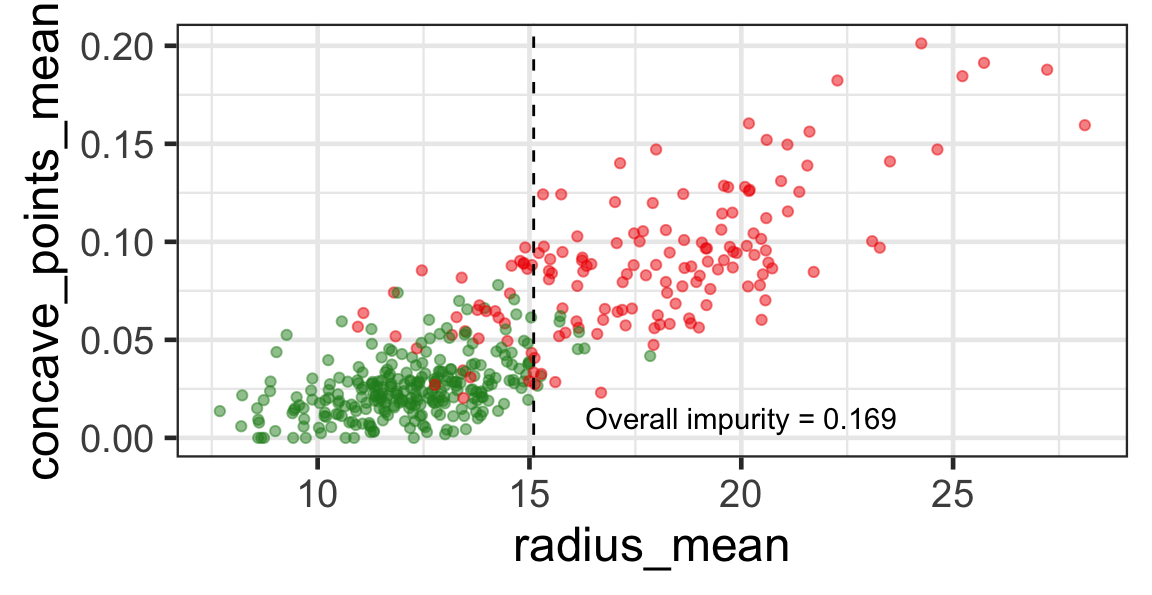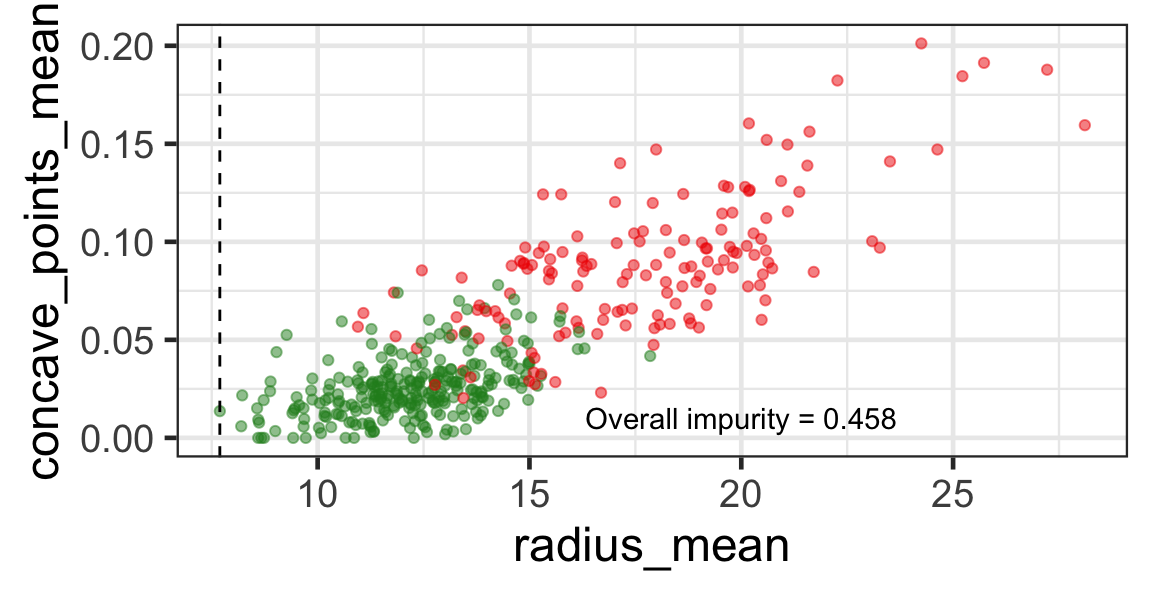
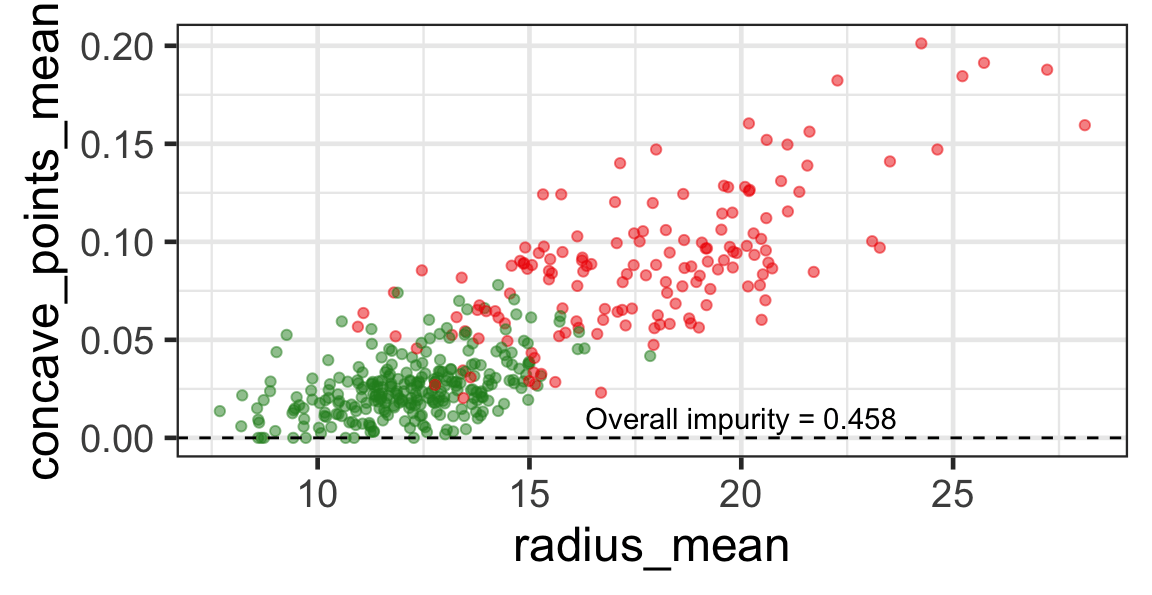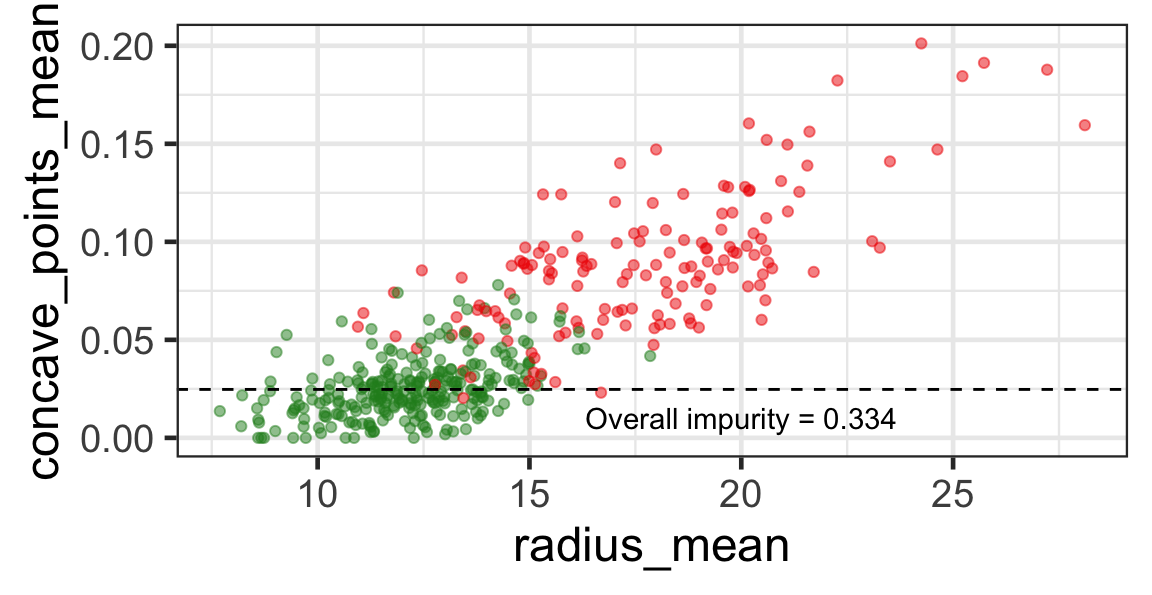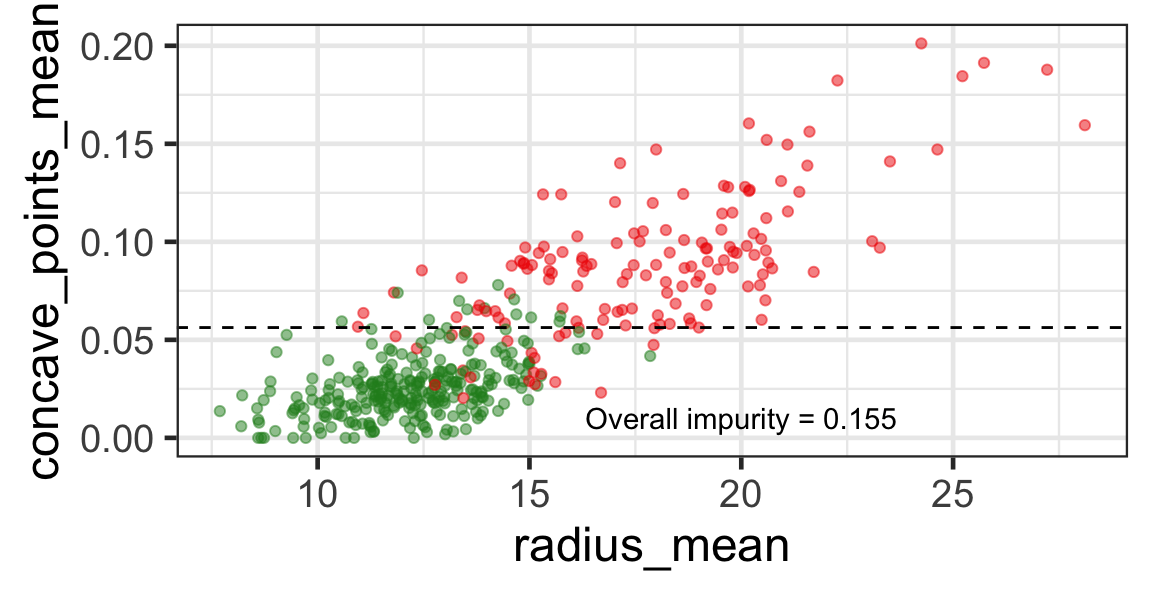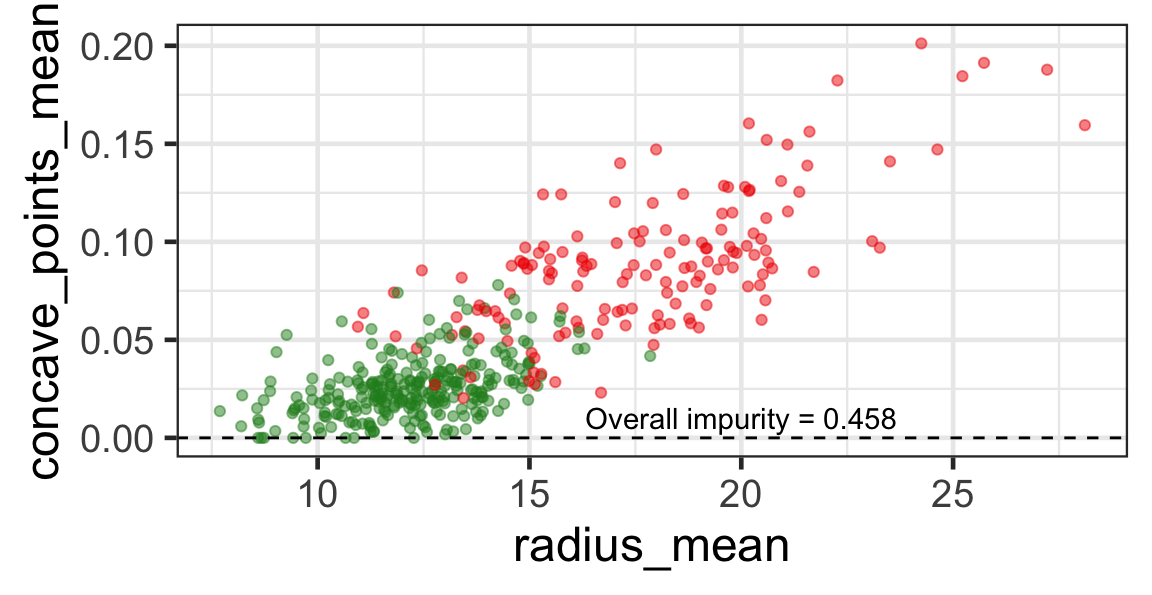
Selected partition


- Selected predictor: j^* = \texttt{concave\_points\_mean}
- Selected threshold: s^* = 0.056
Search for the next optimal partition
- We find the next j and s such that it minimises the overall impurity for the partitioned subset.
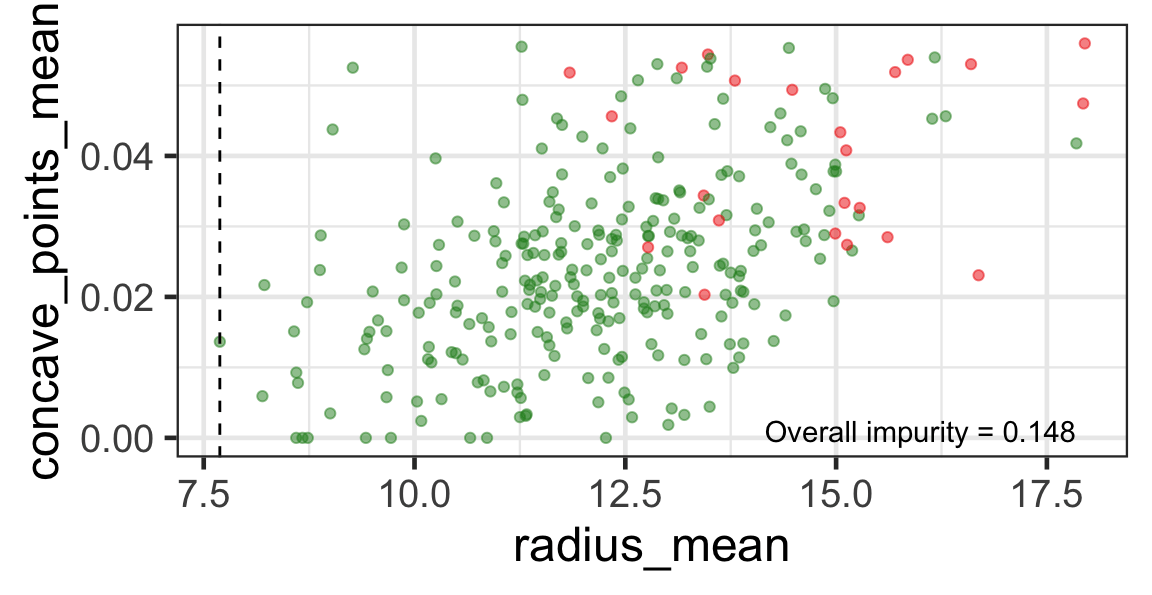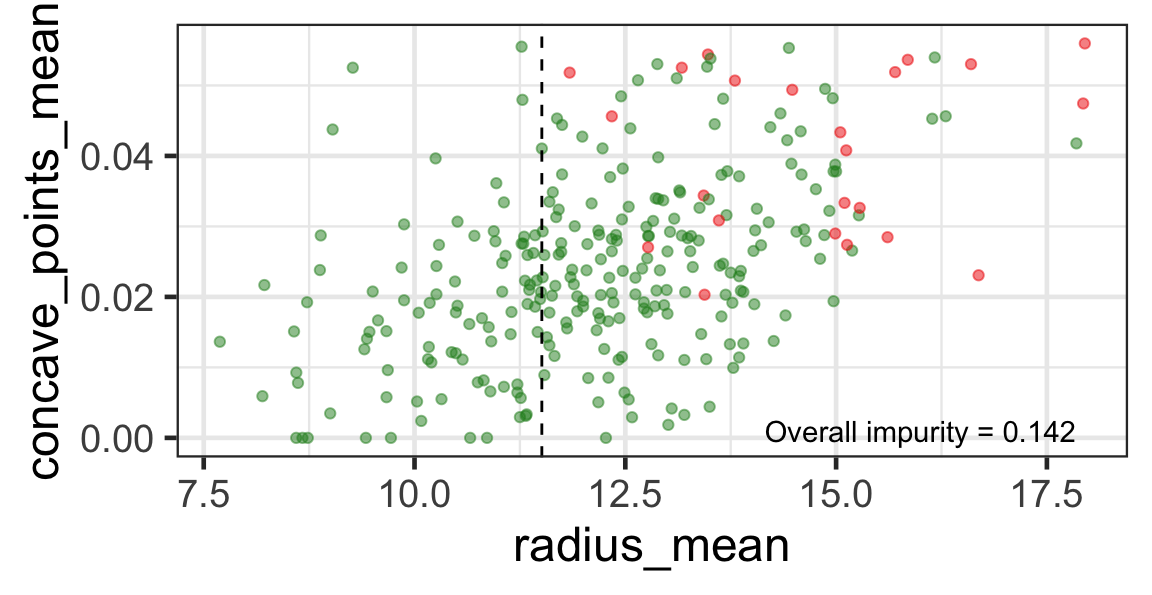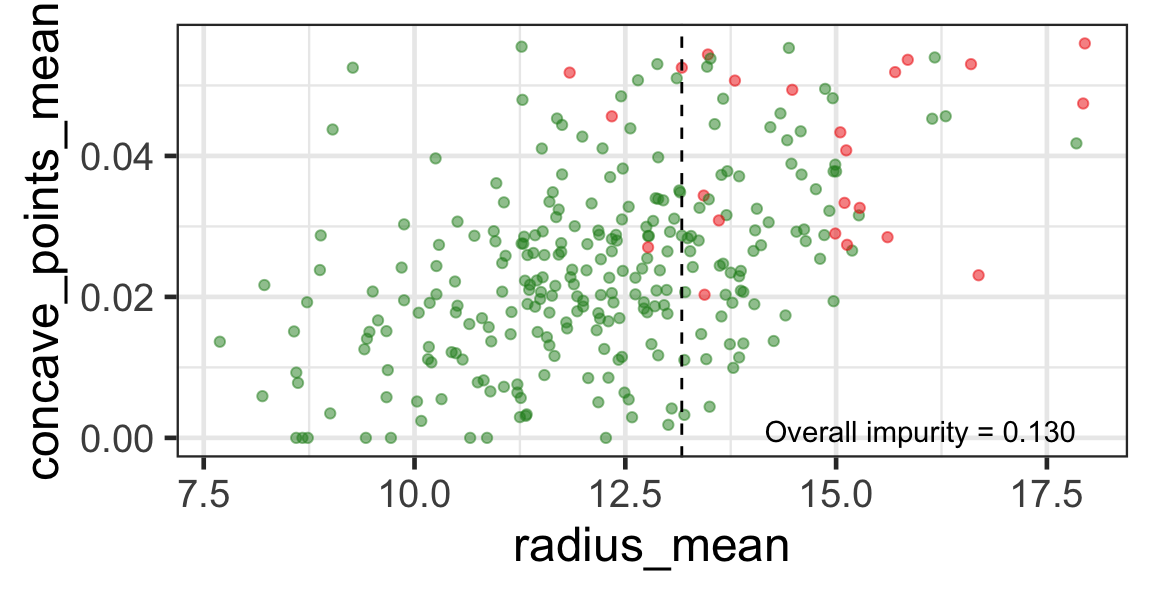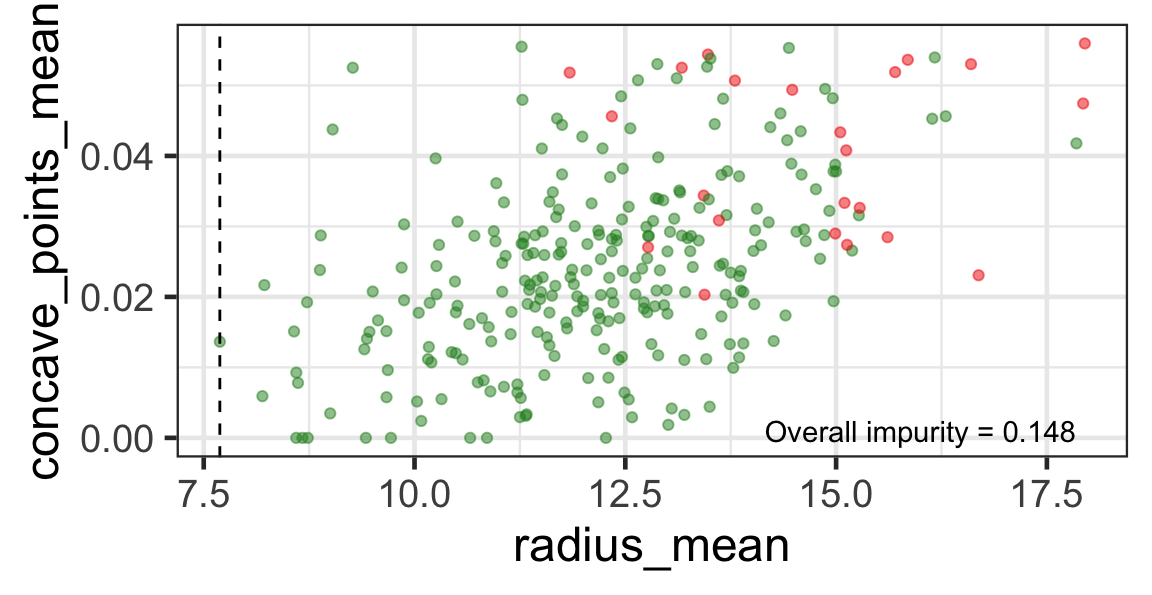
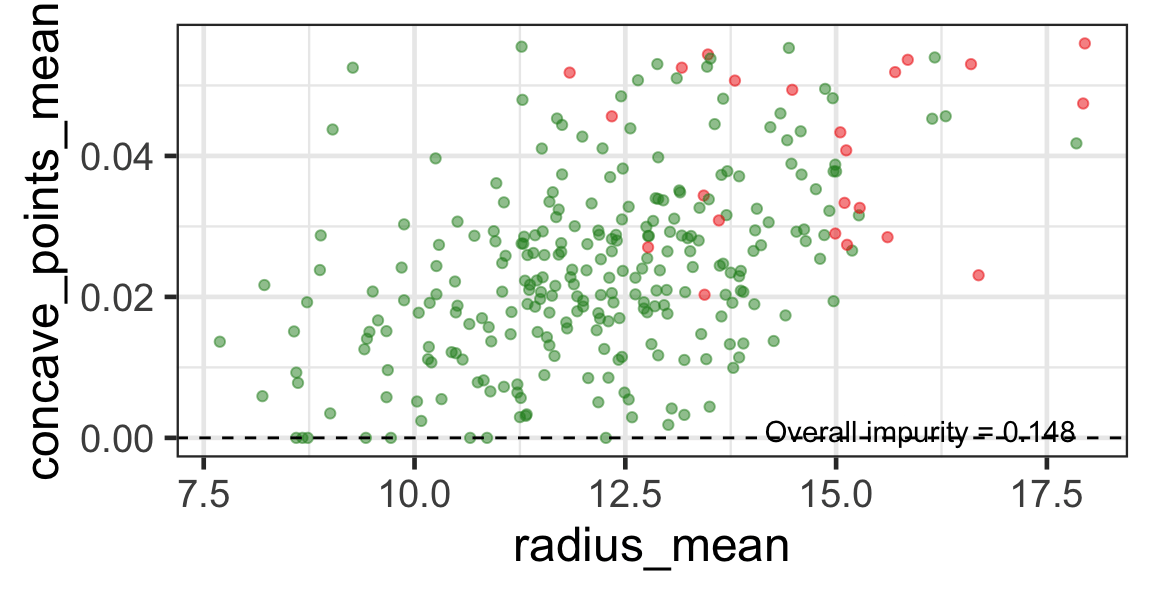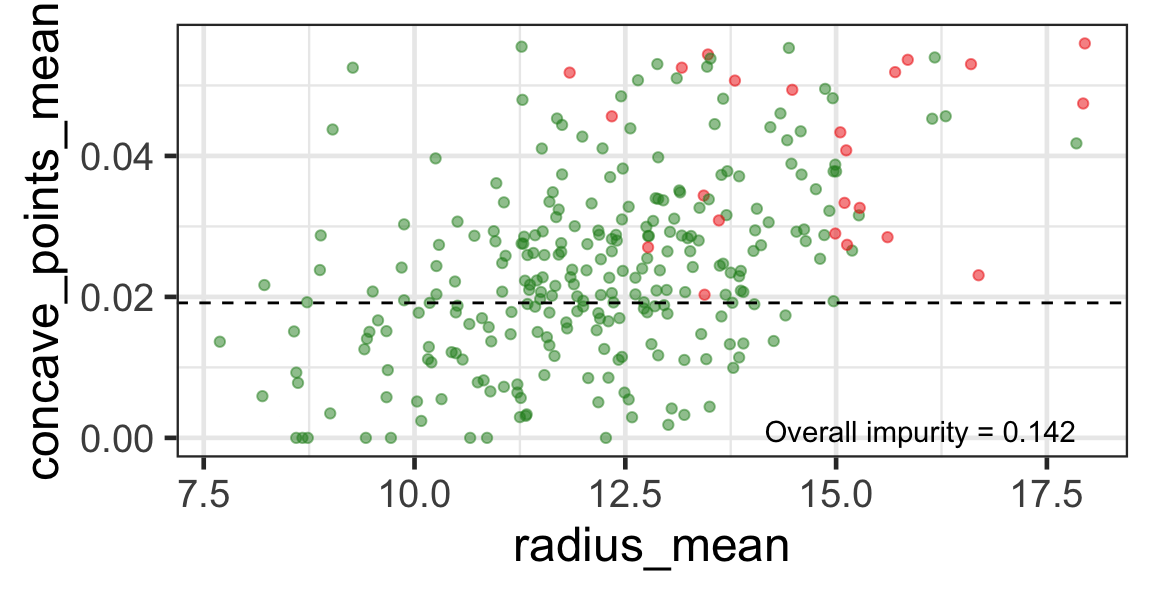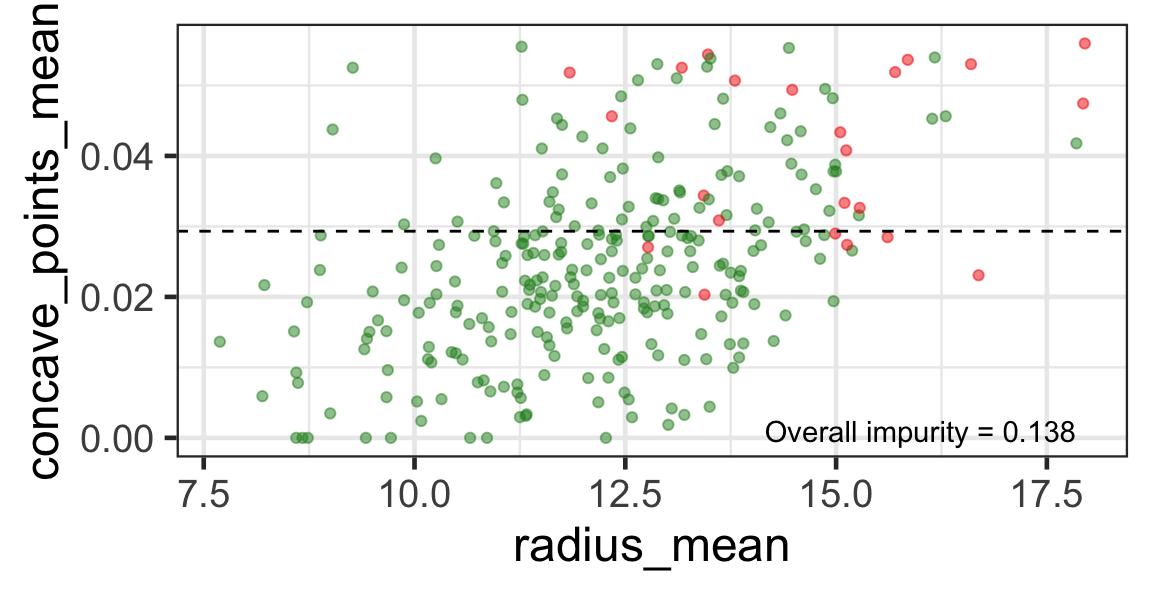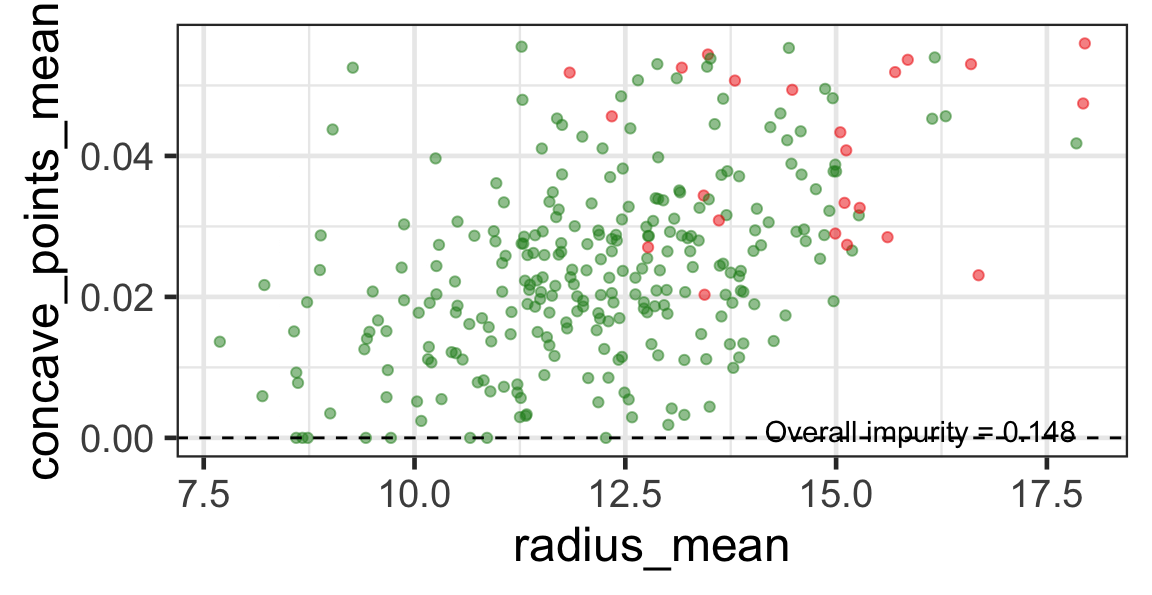
- We repeat again for the next subset and so on …
until we reach the stopping rule.
Changing the stopping rules in rpart
Tuning parameters: results
Code
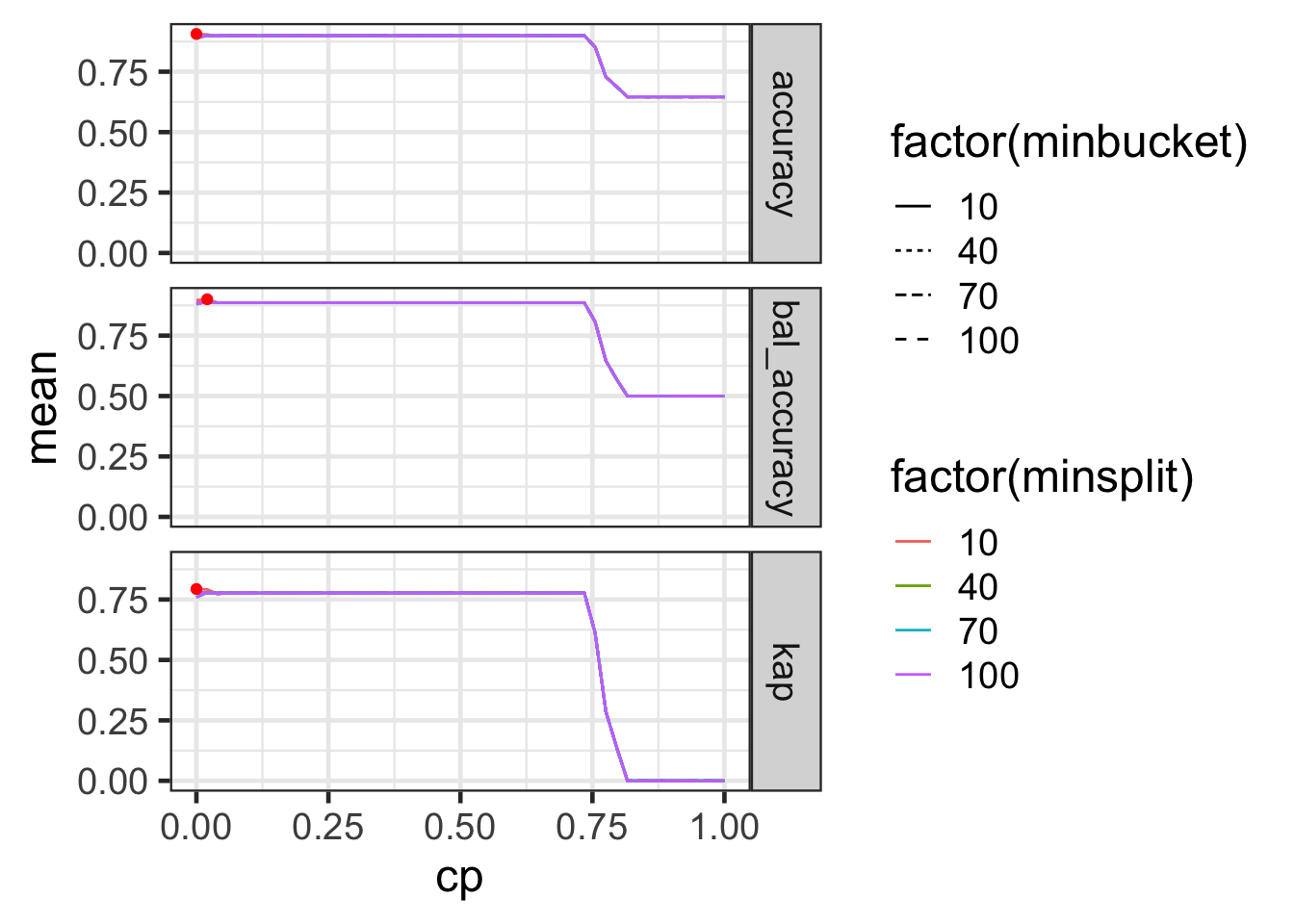
| minbucket | minsplit | cp | .metric | mean | sd |
|---|---|---|---|---|---|
| 10 | 10 | 0.0000000 | accuracy | 0.9061286 | 0.0274646 |
| 10 | 10 | 0.0000000 | kap | 0.7935643 | 0.0583496 |
| 10 | 10 | 0.0204082 | bal_accuracy | 0.9004277 | 0.0417005 |
minbucketandminsplitdoesn’t seem to make much difference (for the range searched at least).cp = 0seems sufficient in this case.
Fitting and visualising the model
duration is omitted as a predictor in the model as it is computed based on the response.
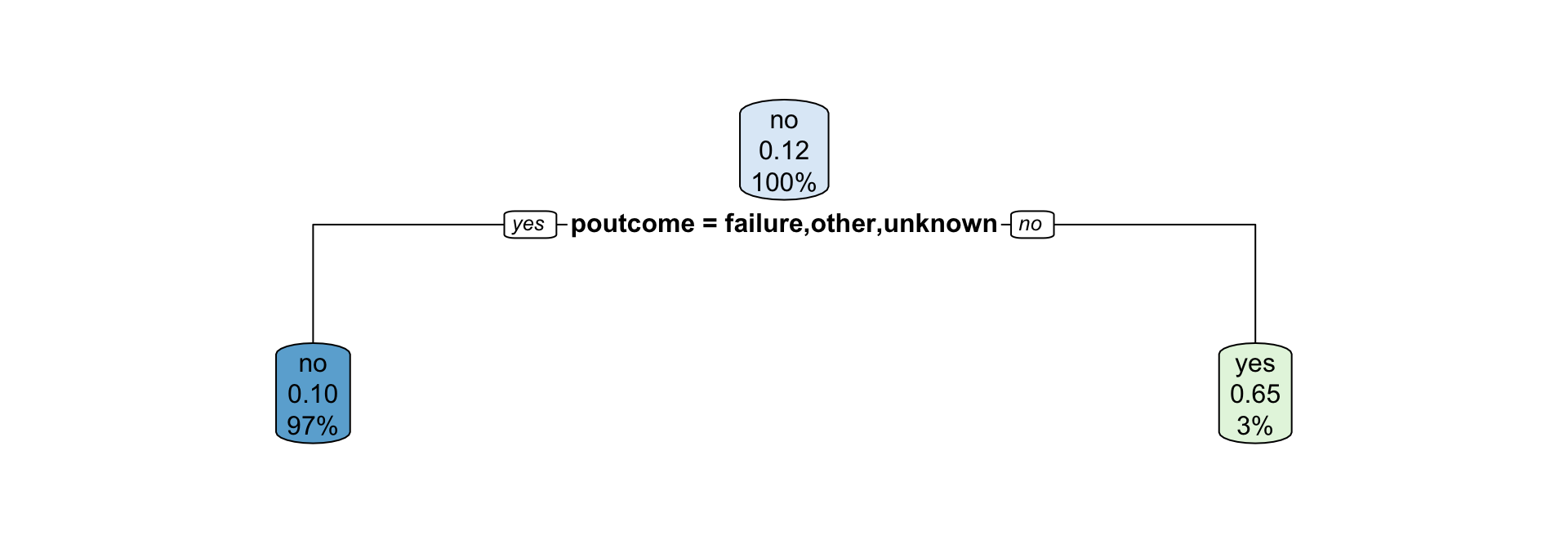
- How are partitions determined for categorical variables?
Partitions for categorical variables
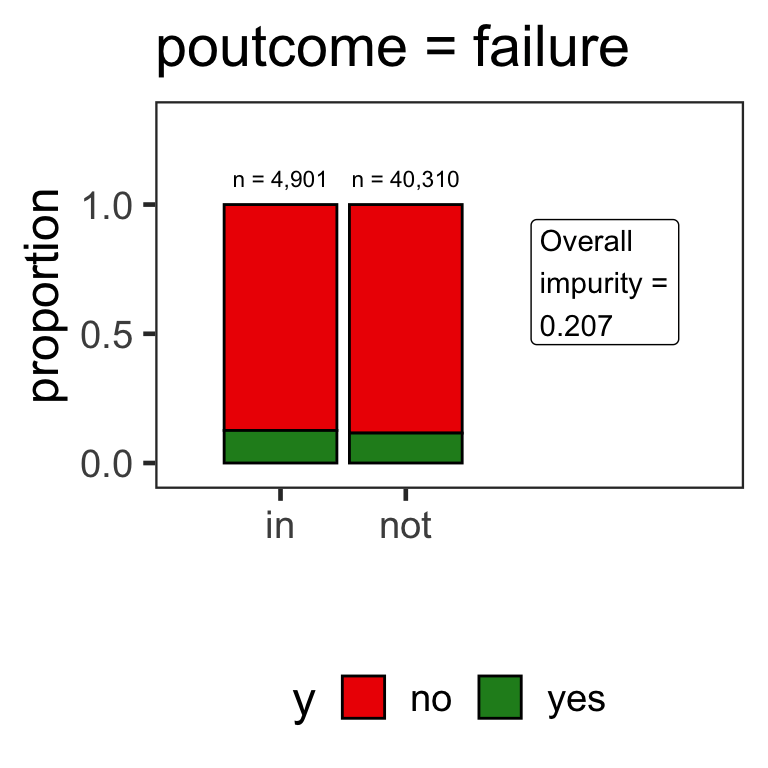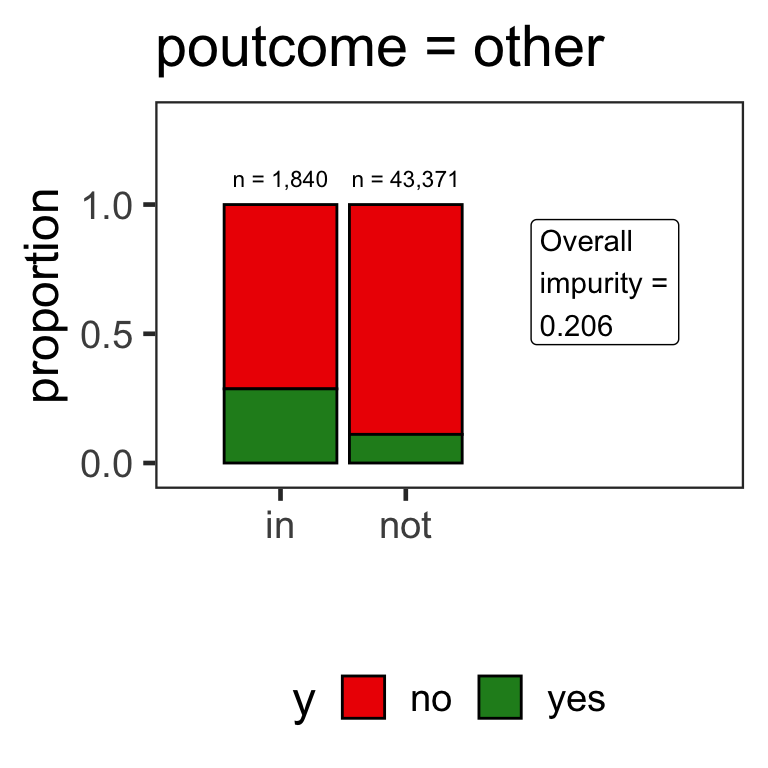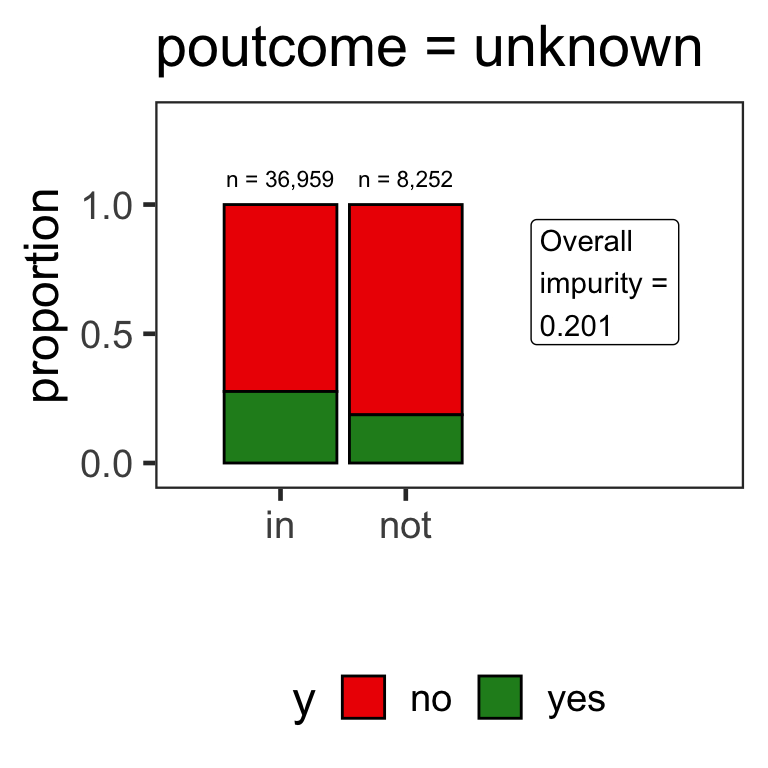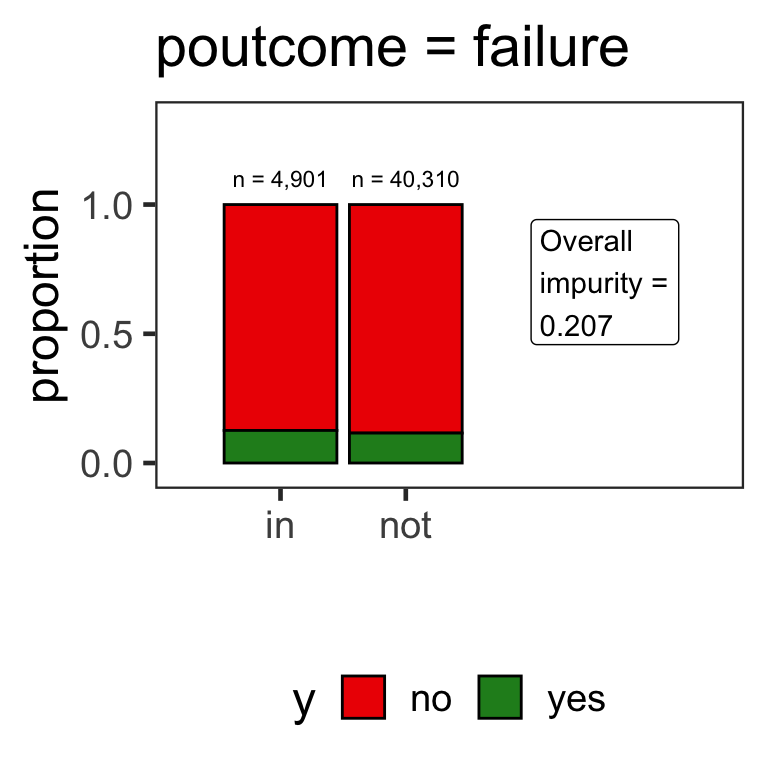
- When the variable is a categorical variable, the partition of observations is based on whether it belongs to a particular class or not.
- E.g., there are 4 classes for
poutcomeand so 4 overall impurities are calculated, one for each class vs other.
Fitting regression tree with R
Interpreting regression tree plot
- The nodes contain:
- average of the response, and
- percentage of observations in node.
- The bold text shows the splitting rules (branches).
- Colors indicate class, with a darker color indicating lower impurity.
- The prediction is the average of the response in the terminal node.
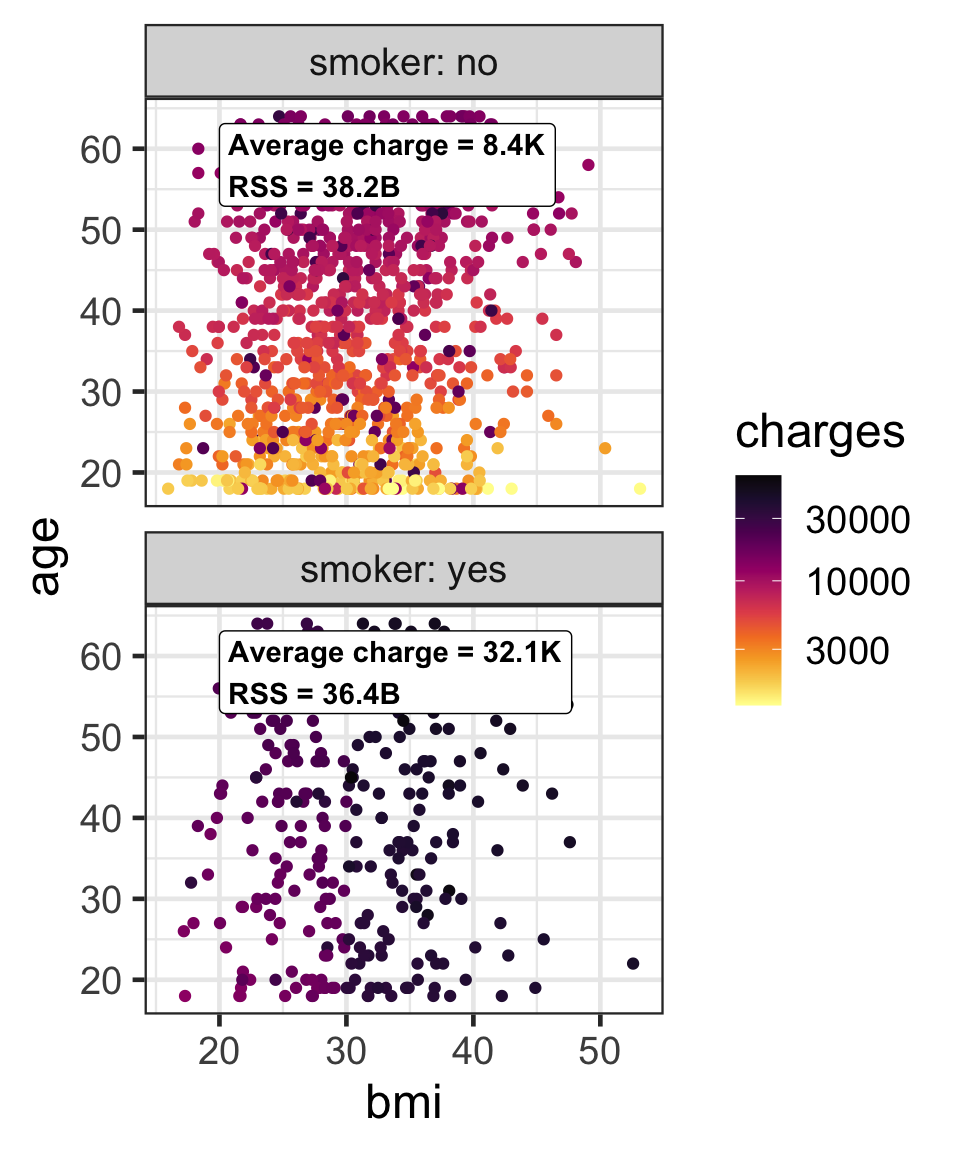
Partition based on a binary predictor
- For a binary variable, \mathcal{A}_L and \mathcal{A}_R is based on its class.
- Then find the average responses, \bar{y}_L and \bar{y}_R, for \mathcal{A}_L and \mathcal{A}_R, respectively.
- We can use the residual sum of squares, e.g. \text{RSS}(\mathcal{A}_L) = \sum_{i \in \mathcal{A}_L}(y_i - \bar{y}_L)^2, to measure the impurity.
- The overall impurity is \text{RSS}(\mathcal{A}_L) + \text{RSS}(\mathcal{A}_R) = 74.6\text{B}.
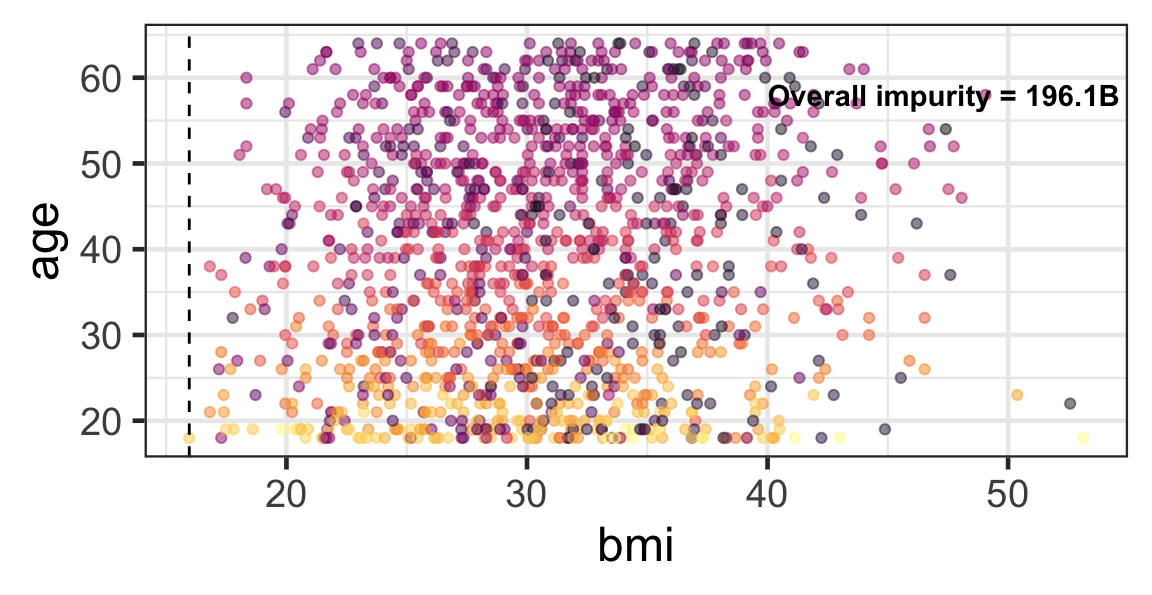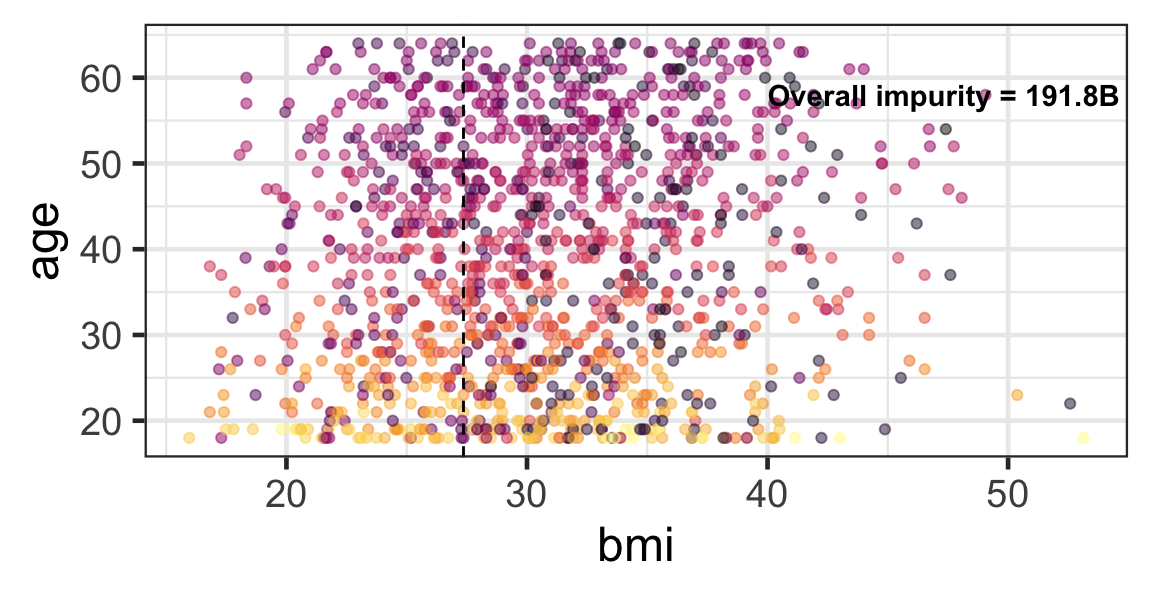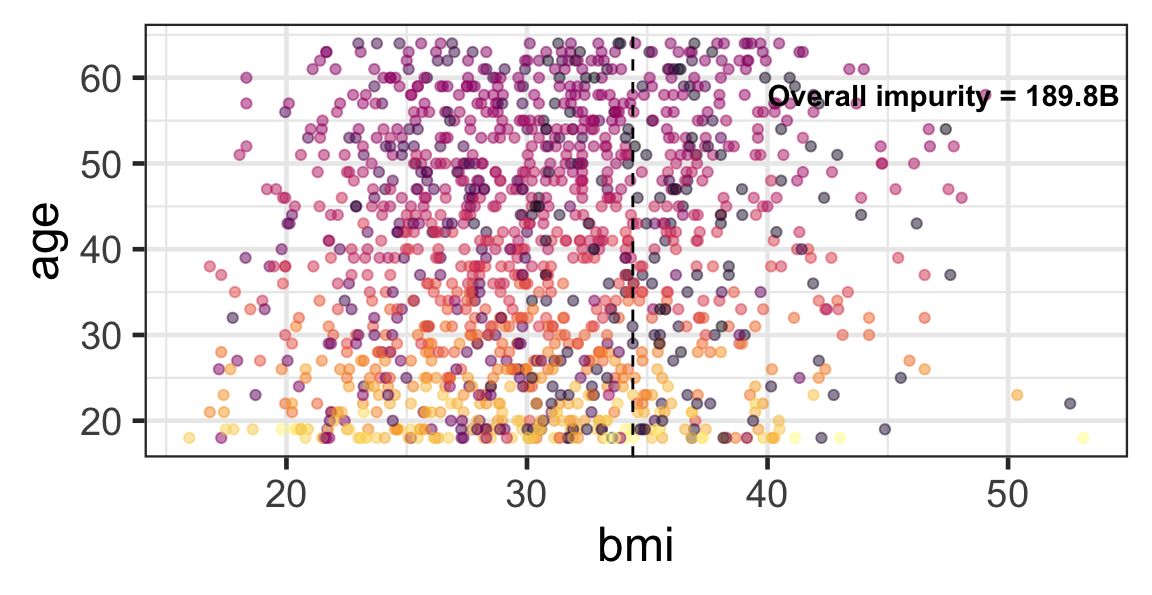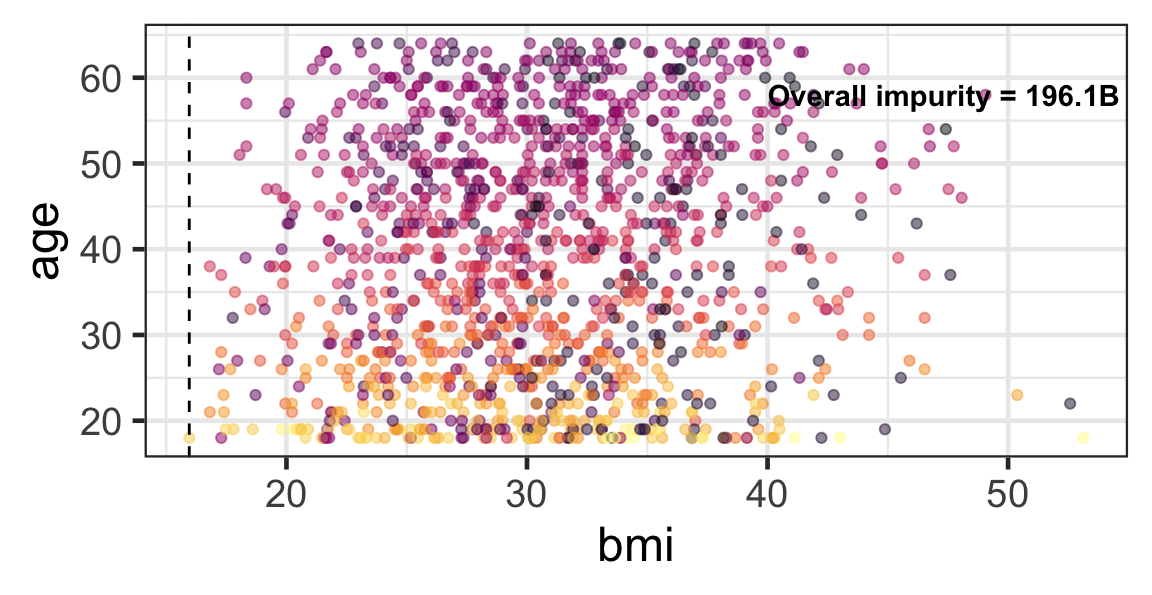
Partition based on a quantitative predictor
- Like for classification trees, a quantitative predictor is partitioned based on the split value.
- The overall impurity is based on a combined impurity measure for quantitative response (RSS here).
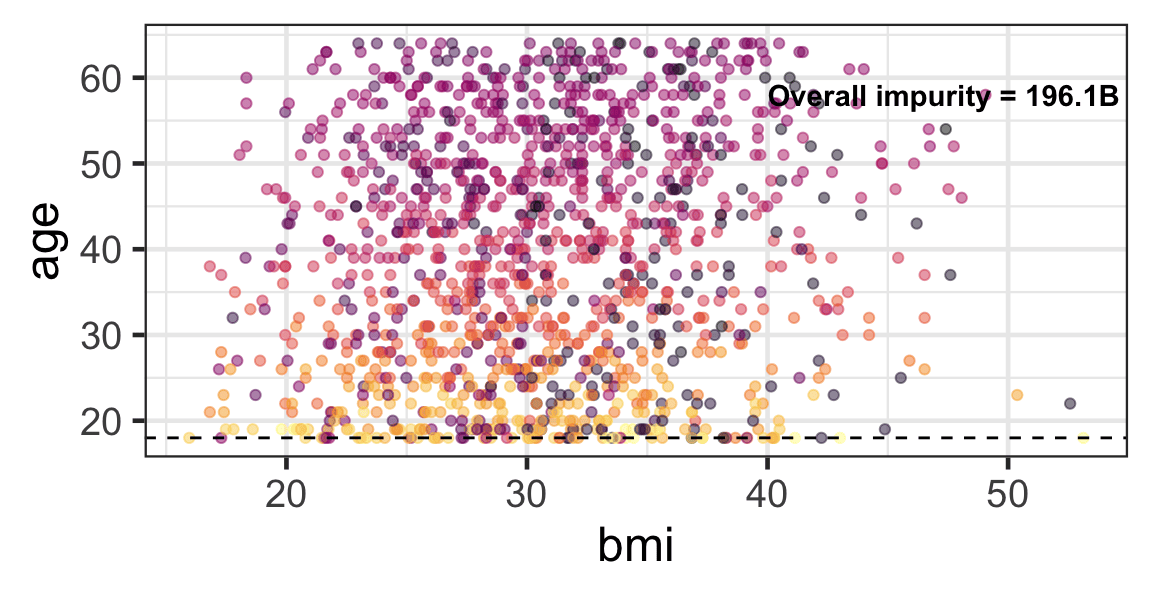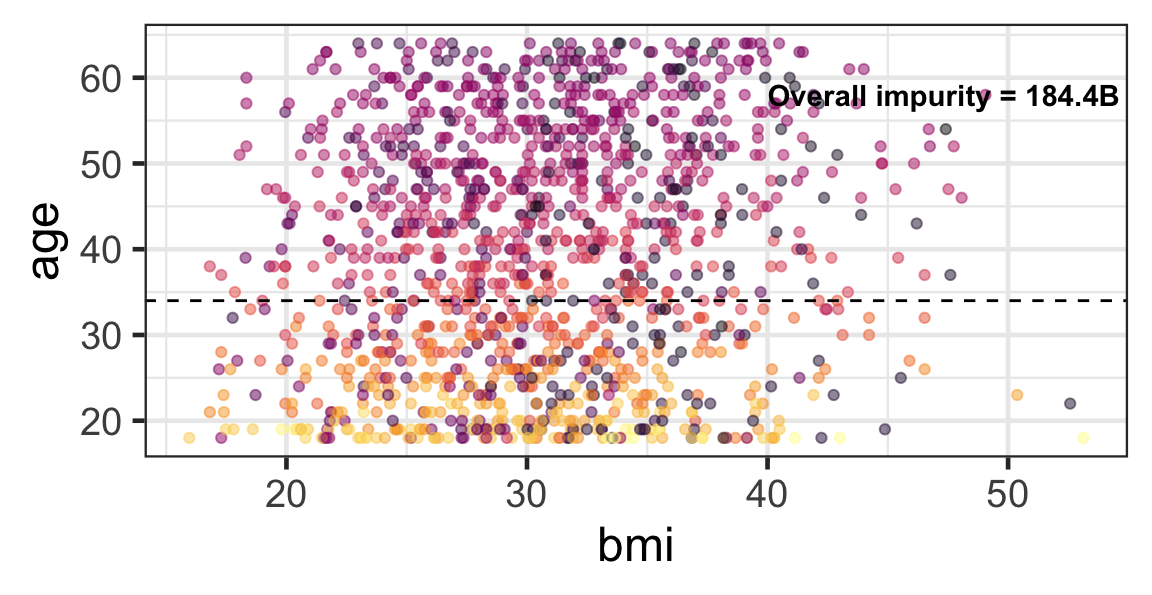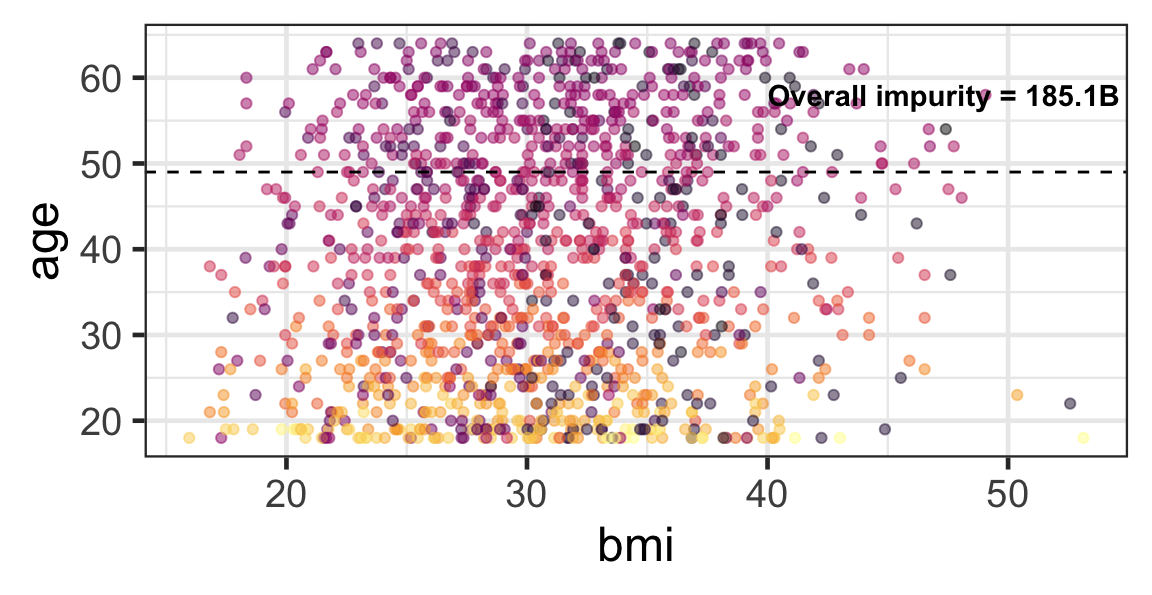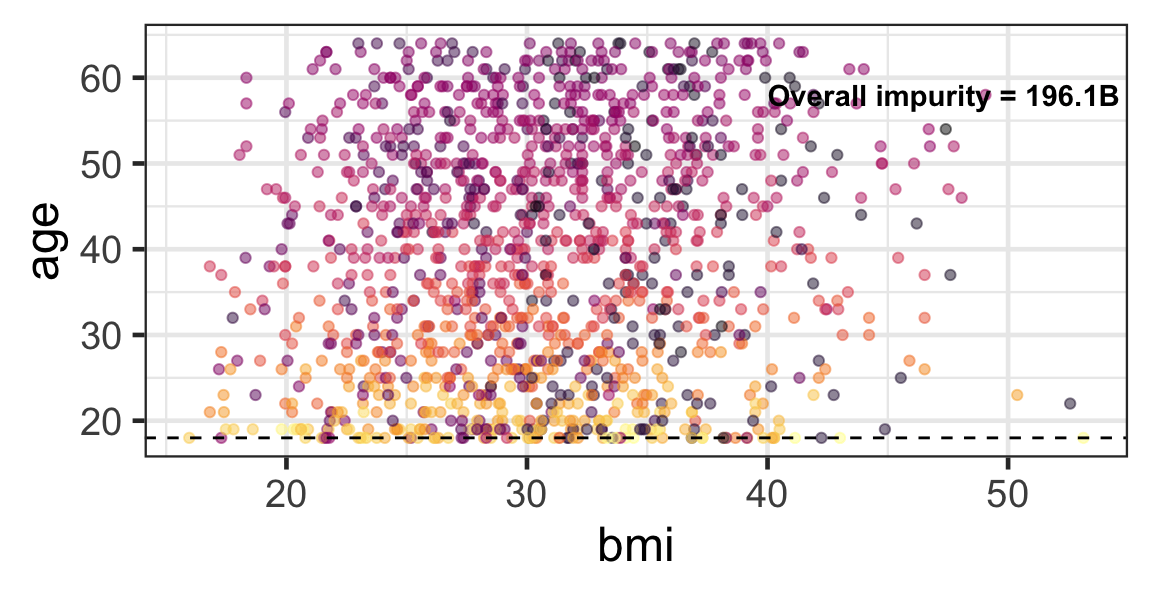
Pruning
- We can grow a tree, T_0, and then prune it to a shorter tree (T_1).
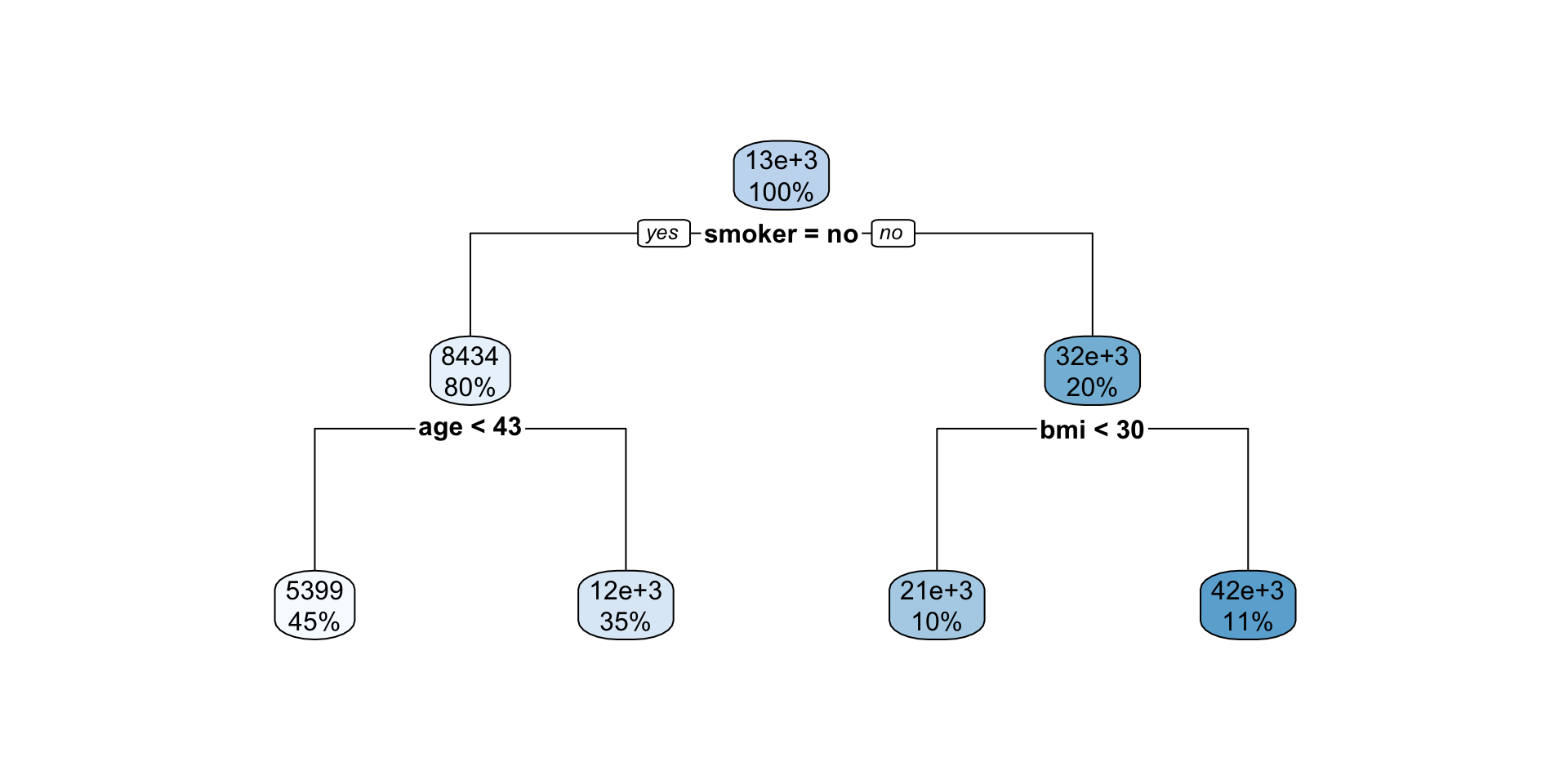
Pruning to optimal cp based on xerror
scroll
- We can select optimal
cpbased onxerror
# A tibble: 86 × 5
CP nsplit `rel error` xerror xstd
<dbl> <dbl> <dbl> <dbl> <dbl>
1 0.620 0 1 1.00 0.0519
2 0.144 1 0.380 0.382 0.0190
3 0.0637 2 0.236 0.239 0.0145
4 0.00967 3 0.173 0.178 0.0133
5 0.00784 4 0.163 0.172 0.0135
6 0.00712 5 0.155 0.165 0.0131
7 0.00537 6 0.148 0.157 0.0131
8 0.00196 7 0.143 0.153 0.0132
9 0.00190 8 0.141 0.156 0.0133
10 0.00173 9 0.139 0.154 0.0132
# ℹ 76 more rowsoptimal_cp <- T0$cptable %>%
as.data.frame() %>%
filter(xerror == min(xerror)) %>%
# if multiple optimal points, then select one
slice(1) %>%
pull(CP)
optimal_cp[1] 0.0009125473
Takeaway
- Tree-based models consist of one or more of nested conditions for the predictors that partition the data.
- Decision trees can be used for both regression and classification problems.
- Decision trees used for:
- classification problems is referred to as classification trees, and
- regression problems is referred to as regression trees.
