Regularisation path for ridge regression
Code
library(broom) # for tidy
fit_ridge %>%
tidy(return_zeros = TRUE) %>%
filter(term != "(Intercept)") %>%
ggplot(aes(lambda, estimate)) +
geom_line(data = ~rename(., term2 = term),
aes(group = term2),
color = "grey") +
geom_hline(yintercept = 0, linetype = "dashed") +
geom_line(color = "royalblue2") +
facet_wrap(~term, nrow = 4) +
labs(x = latex2exp::TeX("\\lambda"),
y = "Standardised coefficients") +
scale_x_log10()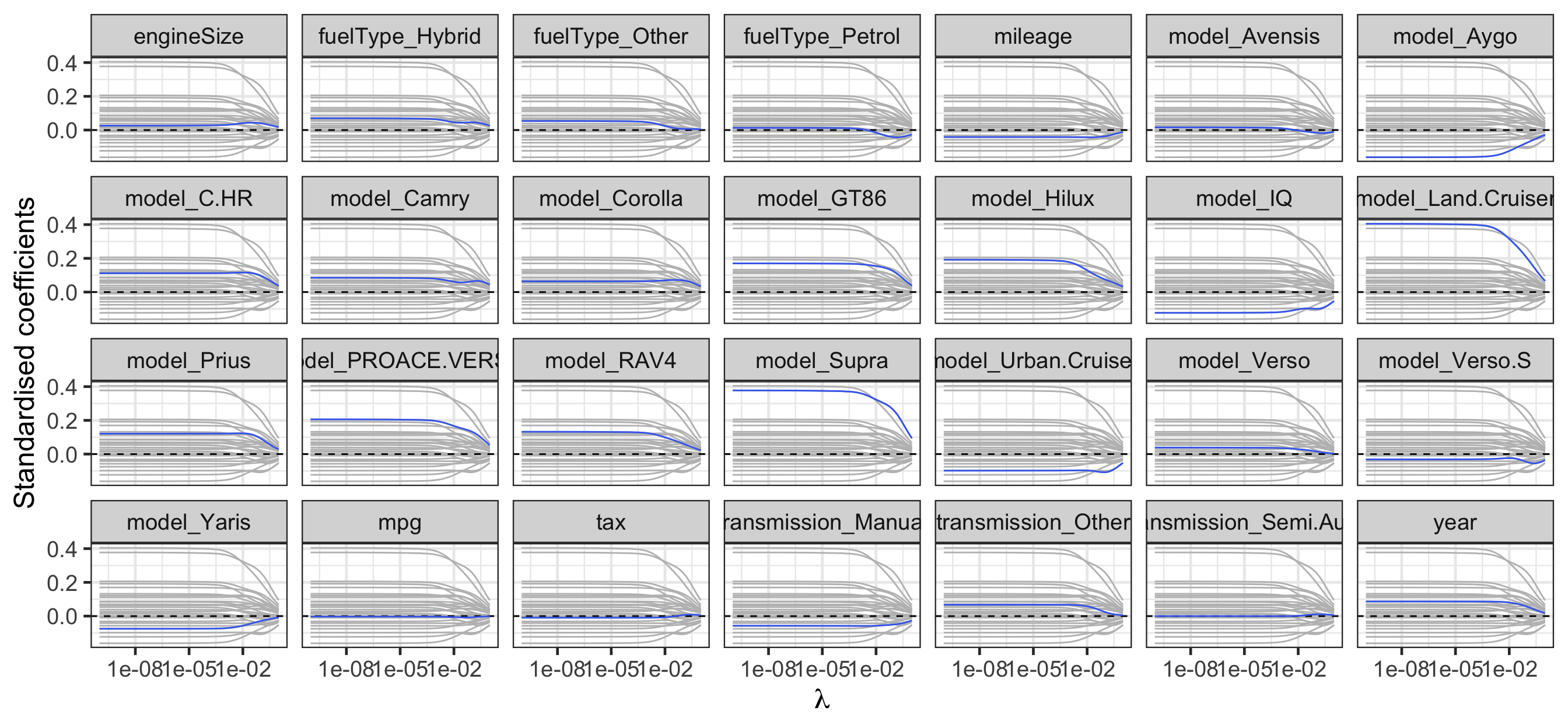
Selecting the tuning parameter for ridge regression
Code
toyota_tuning_ridge_min <- toyota_tuning_ridge %>%
group_by(.metric) %>%
filter(mean == min(mean))
toyota_tuning_ridge %>%
ggplot(aes(lambda, mean)) +
geom_errorbar(aes(ymin = mean - se,
ymax = mean + se)) +
geom_line() +
geom_point(data = toyota_tuning_ridge_min,
color = 'red') +
facet_wrap(~.metric, scales = "free") +
scale_x_log10(name = latex2exp::TeX("\\lambda"))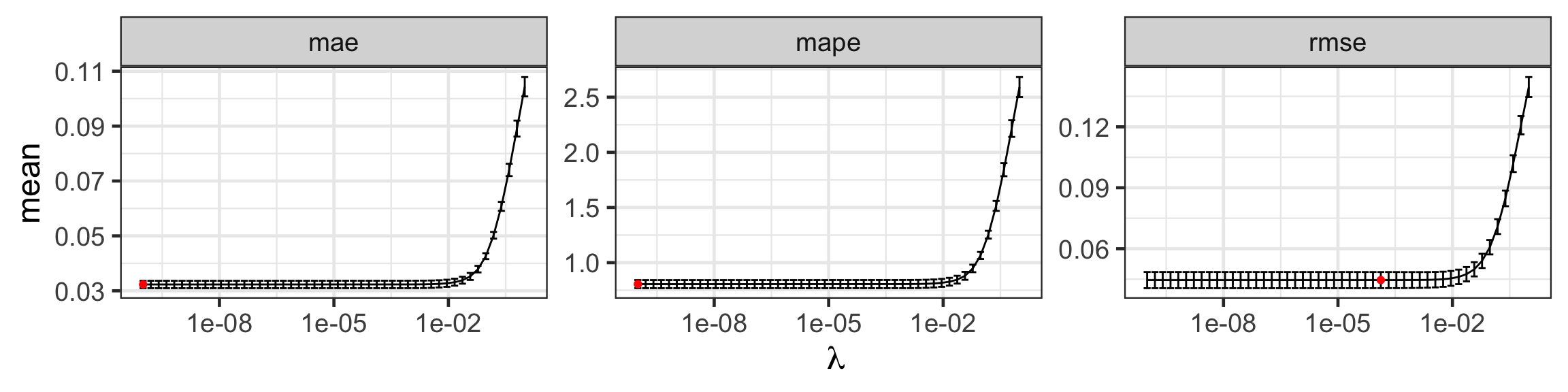
| Metric | \(\lambda\) | Mean | Std. Error |
|---|---|---|---|
| rmse | 0.0001326 | 0.0445490 | 0.0039625 |
| mae | 0.0000000 | 0.0322999 | 0.0013496 |
| mape | 0.0000000 | 0.8054924 | 0.0367295 |
Regularisation path for lasso
Code
library(broom) # for tidy
est_lasso <- fit_lasso %>%
tidy(return_zeros = TRUE)
est_lasso %>%
filter(term != "(Intercept)") %>%
mutate(zero = estimate == 0) %>%
ggplot(aes(lambda, estimate)) +
geom_line(data = ~rename(., term2 = term),
aes(group = term2),
color = "grey") +
geom_hline(yintercept = 0, linetype = "dashed") +
geom_line(aes(color = zero, group = term)) +
facet_wrap(~term, nrow = 4) +
labs(x = latex2exp::TeX("\\lambda"),
y = "Standardised coefficients") +
guides(color = "none") +
scale_x_log10()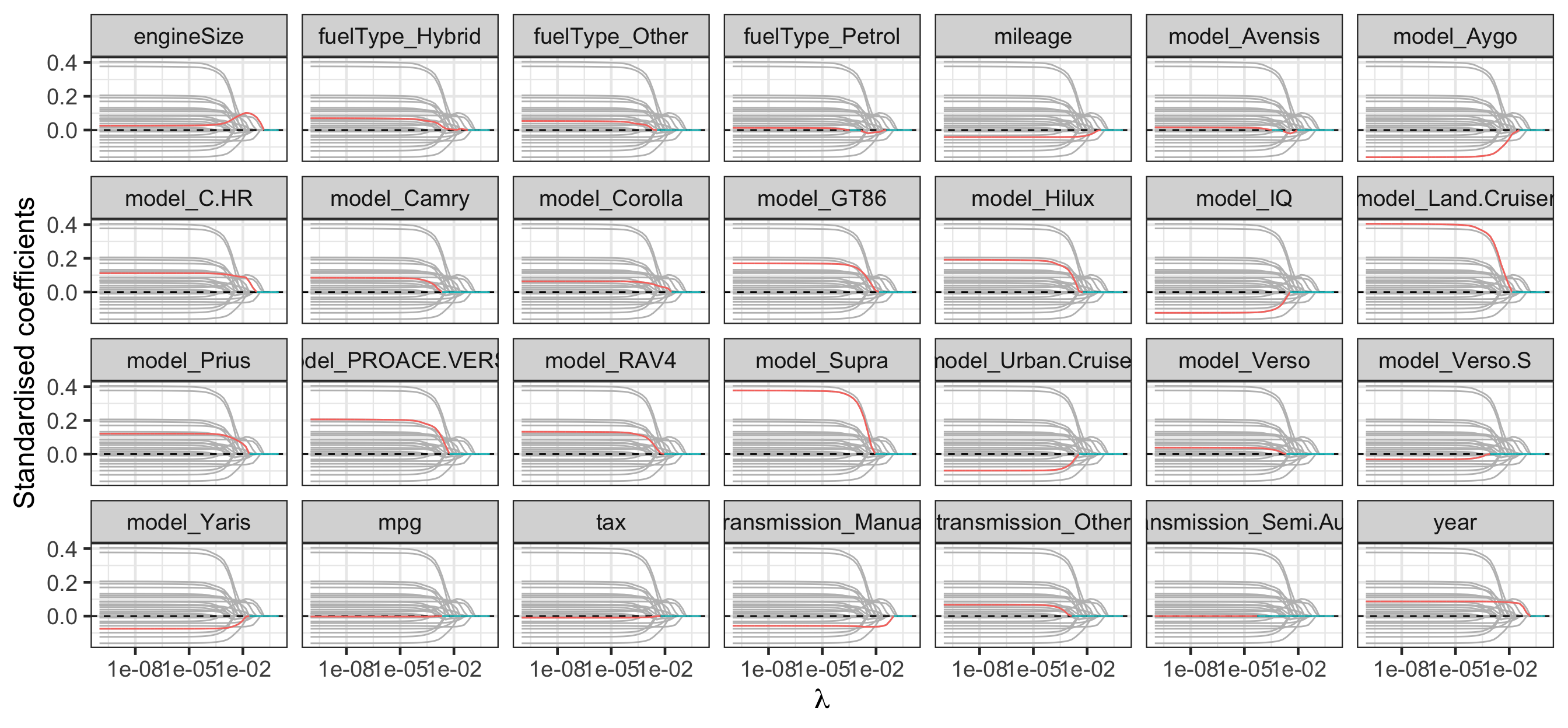
Selecting the tuning parameter \(\lambda\) for lasso
Code
toyota_tuning_lasso <- cv_glmnet_to_toyota(alpha = 1)
toyota_tuning_lasso_min <- toyota_tuning_lasso %>%
group_by(.metric) %>%
filter(mean == min(mean))
toyota_tuning_lasso %>%
ggplot(aes(lambda, mean)) +
geom_errorbar(aes(ymin = mean - se,
ymax = mean + se)) +
geom_line() +
geom_point(data = toyota_tuning_lasso_min,
color = 'red') +
facet_wrap(~.metric, scales = "free") +
scale_x_log10(name = latex2exp::TeX("\\lambda")) 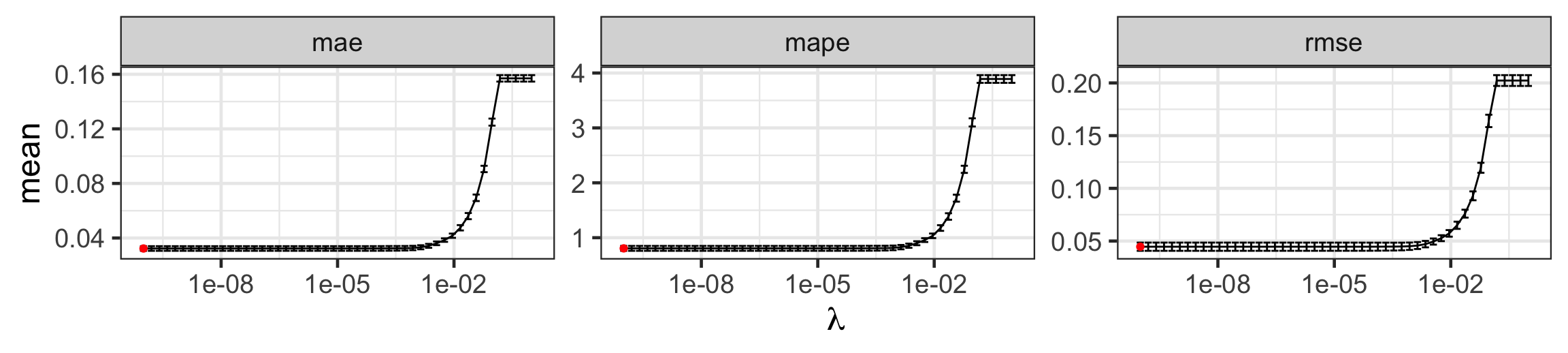
| Metric | \(\lambda\) | Mean | Std. Error |
|---|---|---|---|
| mae | 0 | 0.0323048 | 0.0017061 |
| mape | 0 | 0.8057043 | 0.0447169 |
| rmse | 0 | 0.0446230 | 0.0039084 |
Regularisation path for group lasso
Code
est_glasso <- fit_glasso %>%
broom:::tidy.glmnet(return_zeros = TRUE)
est_glasso %>%
mutate(zero = estimate == 0) %>%
filter(term != "(Intercept)") %>%
ggplot(aes(lambda, estimate)) +
geom_line(data = ~rename(., term2 = term),
aes(group = term2),
color = "grey") +
geom_hline(yintercept = 0, linetype = "dashed") +
geom_line(aes(color = zero, group = term)) +
facet_wrap(~term, nrow = 4) +
labs(x = latex2exp::TeX("\\lambda"),
y = "Standardised coefficients") +
scale_x_log10() +
guides(color = "none")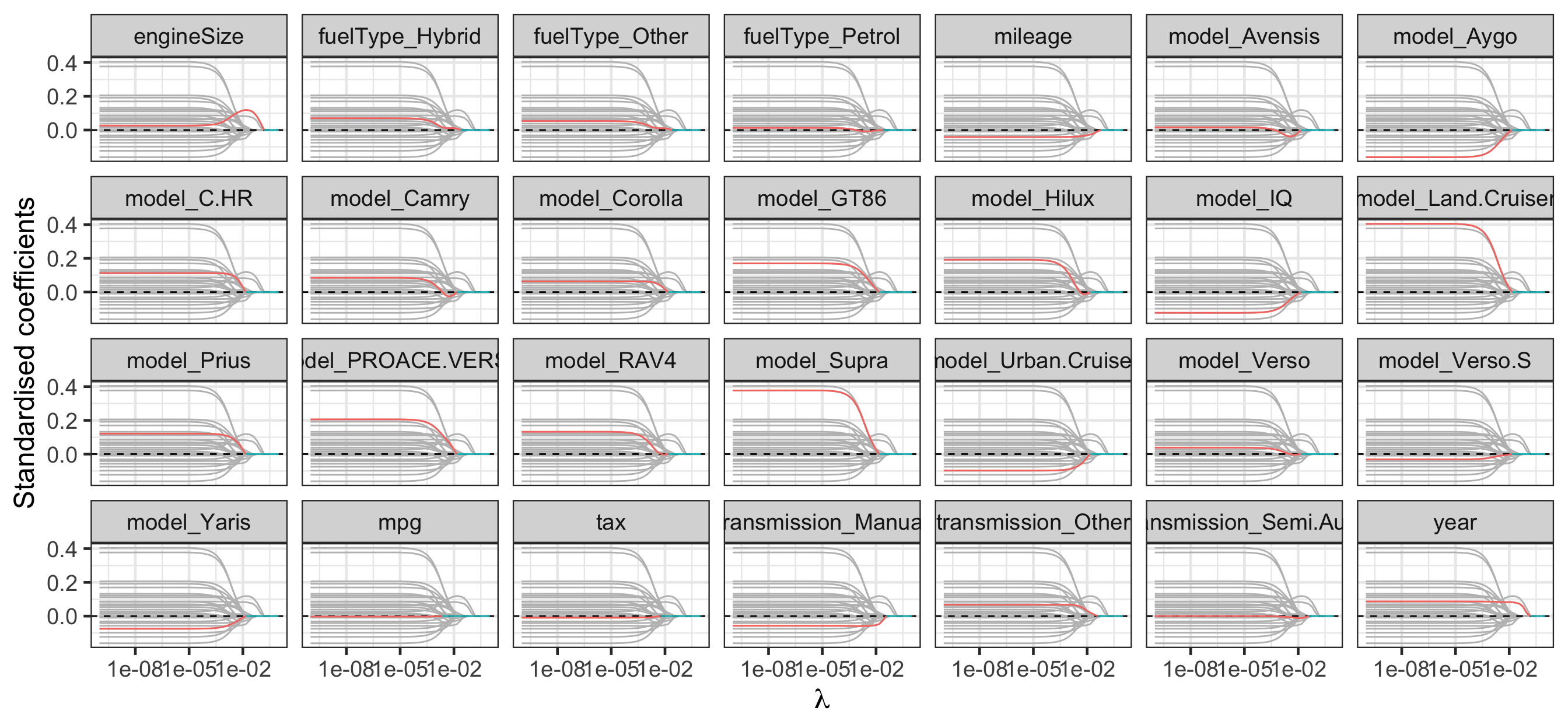
Regularisation path: lasso vs group lasso
scroll
Code
bind_rows(mutate(est_lasso, type = "lasso"),
mutate(est_glasso, type = "glasso")) %>%
mutate(type = fct_inorder(type),
zero = estimate == 0) %>%
filter(str_detect(term, "^(model_|transmission_)")) %>%
ggplot(aes(lambda, estimate)) +
geom_hline(yintercept = 0, linetype = "dashed") +
geom_line(aes(group = interaction(term, type), color = type)) +
facet_wrap(~term) +
labs(x = latex2exp::TeX("\\lambda"),
y = "Standardised coefficients") +
scale_x_log10() +
scale_color_manual("", values = c("royalblue2", "violetred2"))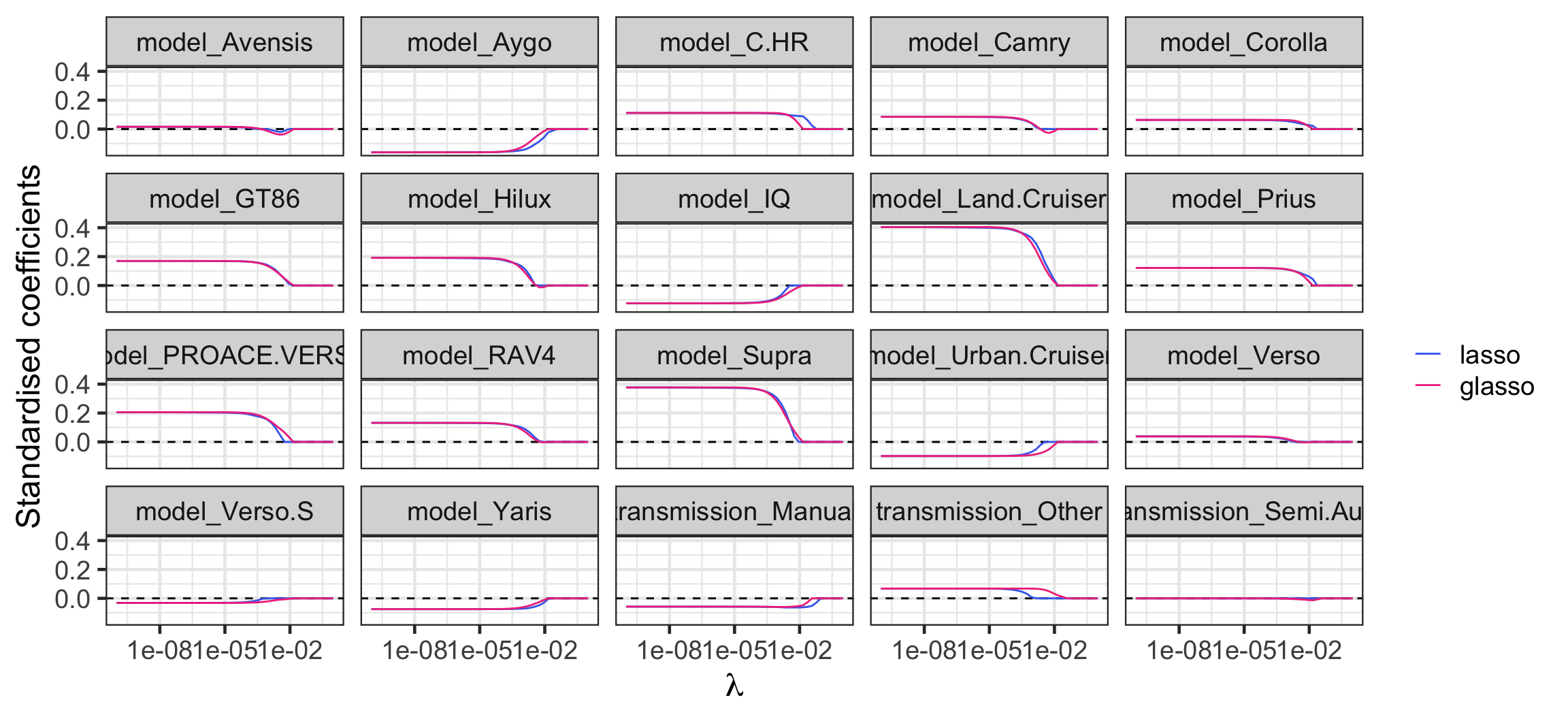
Visualising the constraints
Lasso
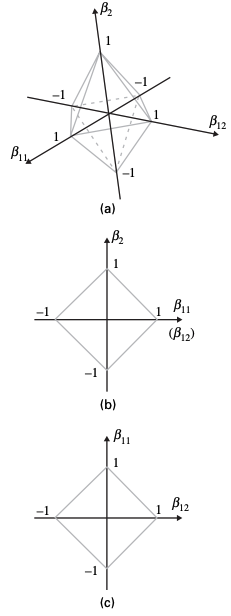
Group lasso
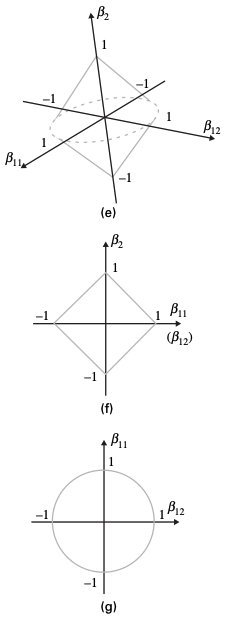
Ridge regression
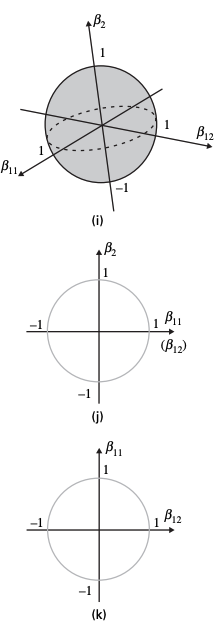
Takeaways
- Shrinkage methods are a powerful variable selection approach for regression by shrinking the coefficients predictors towards zero.
- You can use cross-validation to calibrate these methods for prediction.
