\(k\)-fold cross validation

- Partition samples into \(k\) (near) equal sized subsamples (referred to as folds).
- Fit the model on \(k − 1\) subsets, and compute a metric, e.g. RMSE, on the omitted subset.
- Repeat \(k\) times omitting a different subset each time.
Visualising with parallel coordinate plots
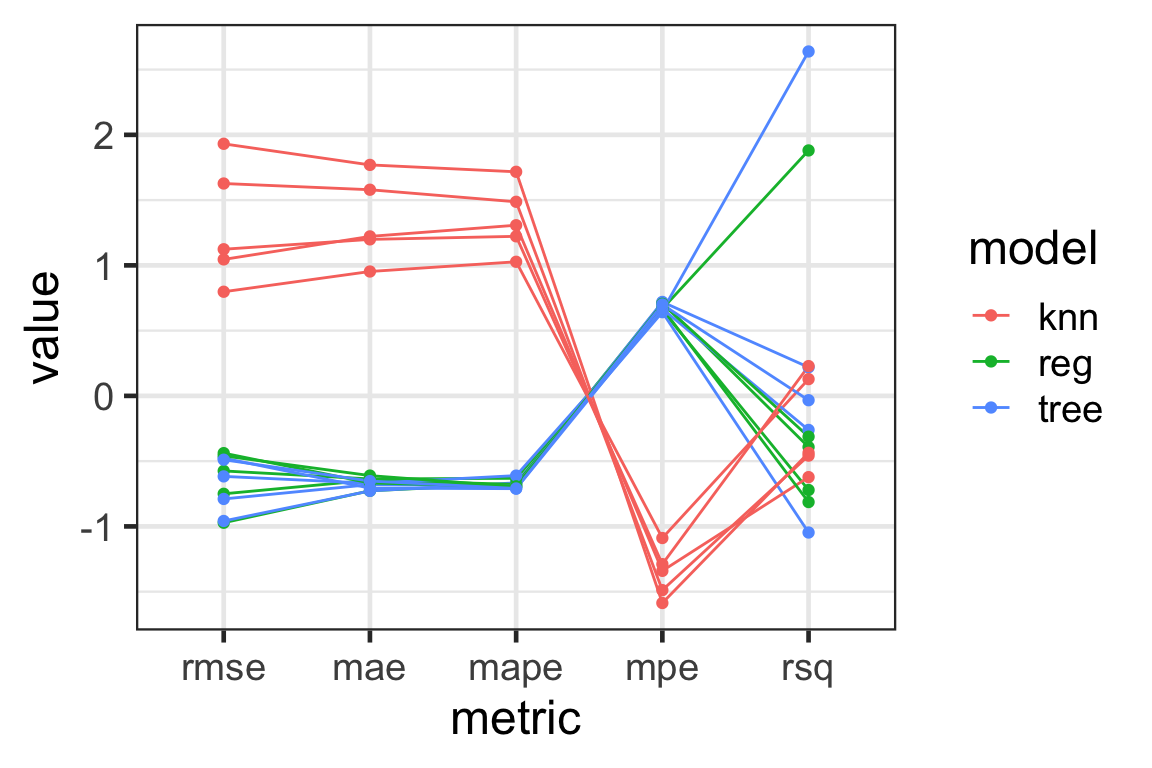
- Parallel coordinate plots can be used to visualise high-dimensional data - here our model metrics!
- Each variable is shown in the \(x\)-axis.
- The value of the variable is standardised in this plot.
- The lines correspond to an observational unit (a fold and a model combination).
- The lines are colored by the model here.
Results
- We see that
knnhas a large variation in the metrics - this means this model has a high variance and it is not desirable. - The
treeandreghas a large variation inrmseandrsq- they are somewhat similar in performance.
Bootstrap samples
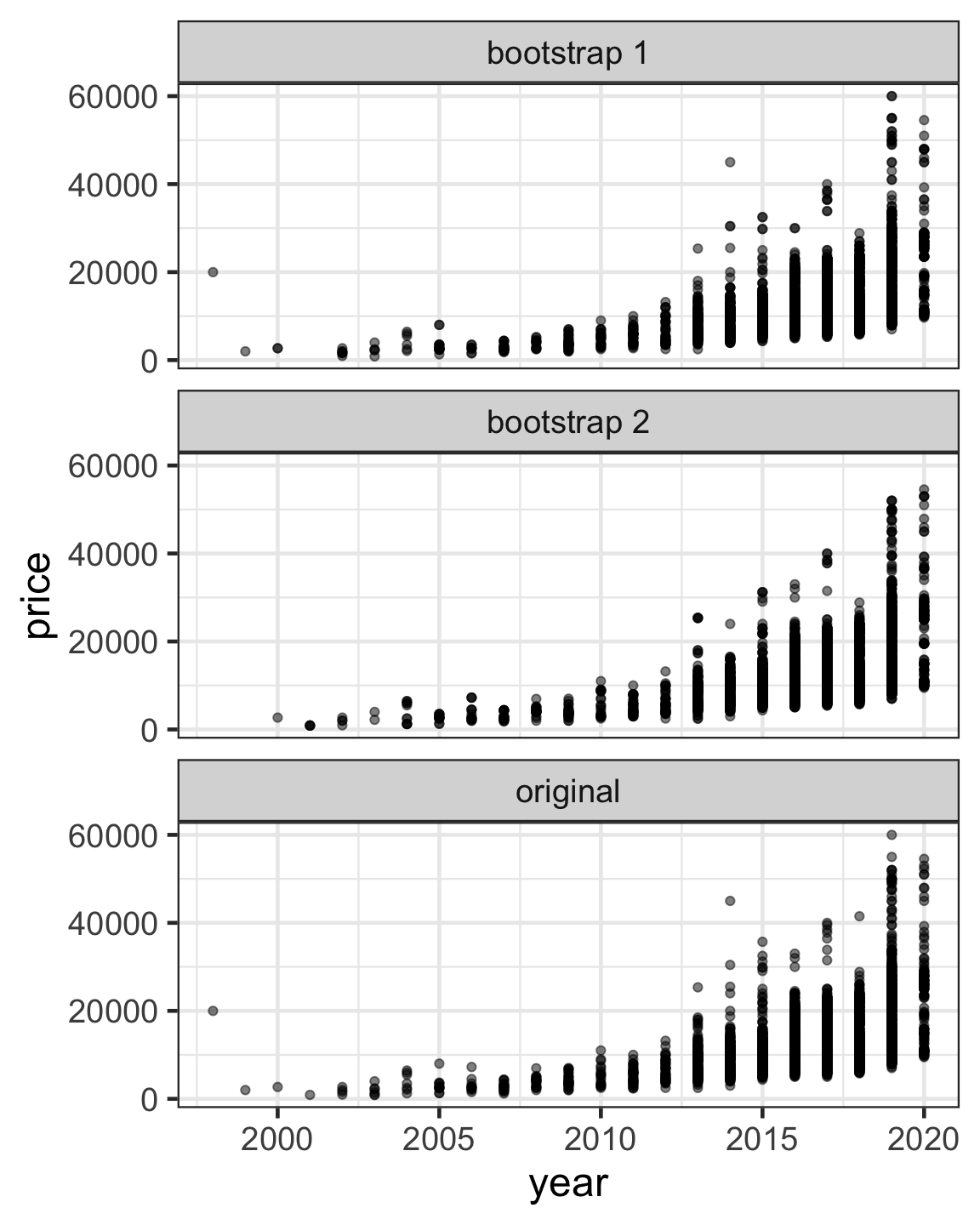
- A bootstrap sample is created by sampling with replacement the original data with the same dimension as the original data.
# A tibble: 6,738 × 9
model year price trans…¹ mileage fuelT…² tax
<chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl>
1 C-HR 2019 26499 Automa… 1970 Hybrid 140
2 Aygo 2018 7800 Manual 12142 Petrol 145
3 Yaris 2015 6490 Manual 36100 Petrol 30
4 Yaris 2018 10500 Manual 9290 Petrol 145
5 Yaris 2018 9595 Manual 20740 Petrol 145
6 Auris 2016 17490 Automa… 29031 Hybrid 0
7 Yaris 2014 8498 Automa… 57677 Hybrid 0
8 PROA… 2019 28456 Automa… 9119 Diesel 145
9 Yaris 2017 7998 Manual 63978 Petrol 150
10 Auris 2017 15095 Automa… 43405 Hybrid 0
# … with 6,728 more rows, 2 more variables:
# mpg <dbl>, engineSize <dbl>, and abbreviated
# variable names ¹transmission, ²fuelTypeCode
Takeaways
- Resampling involves repeatedly drawing samples from the training data to create new data.
- Resampling can be computationally expensive but it can give:
- a more robust estimate of the prediction error or
- help with model selection or tune hyperparameters.
