Simple Linear Regression
STAT1003 – Statistical Techniques
Australian National University
These slides are best viewed on a modern browser like Google Chrome on a desktop or laptop. Some interactive components may require some time to fully load.
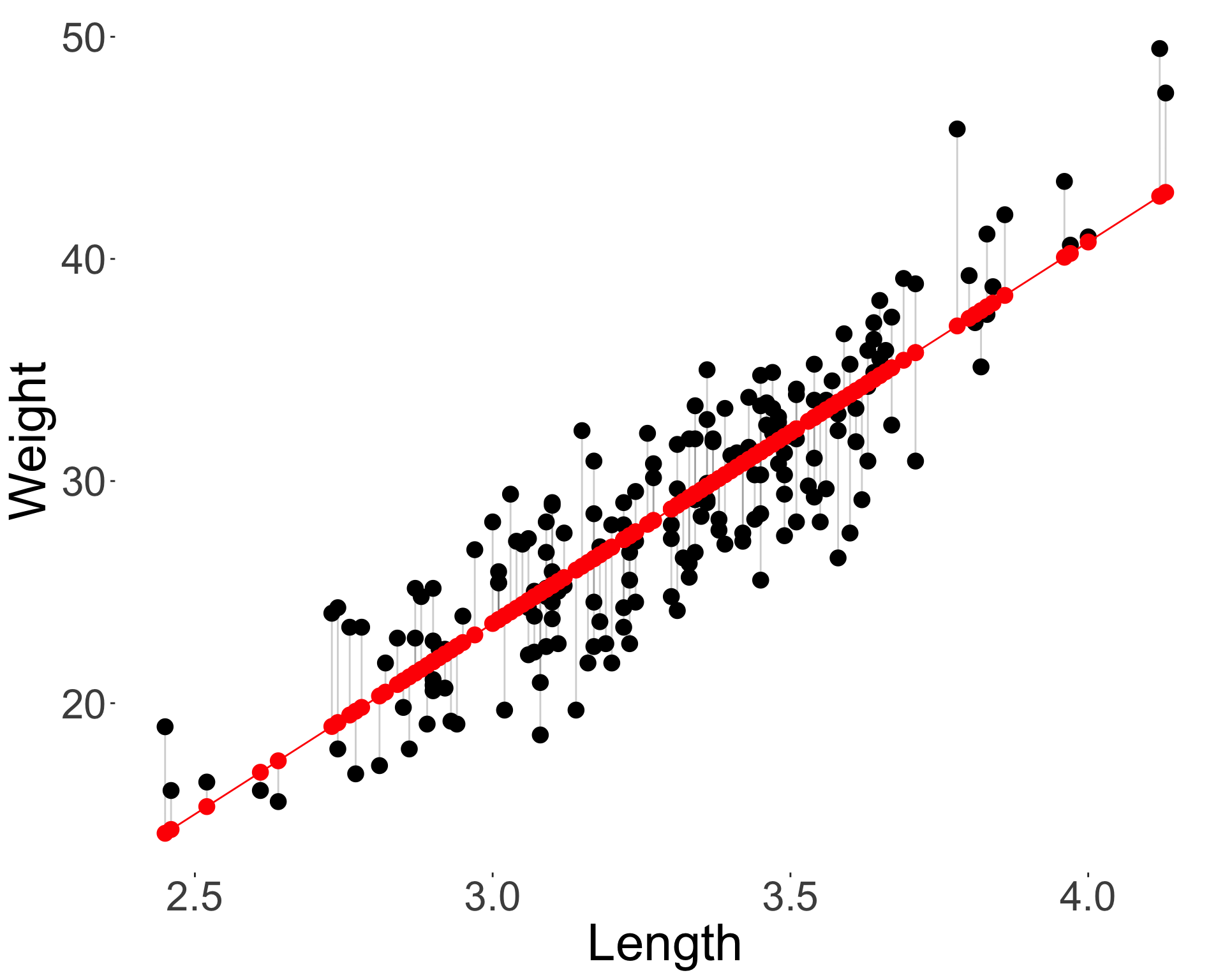
Predicted values
- The response can be predicted from the fitted model for a given \(x\) as:
\[\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 x.\]
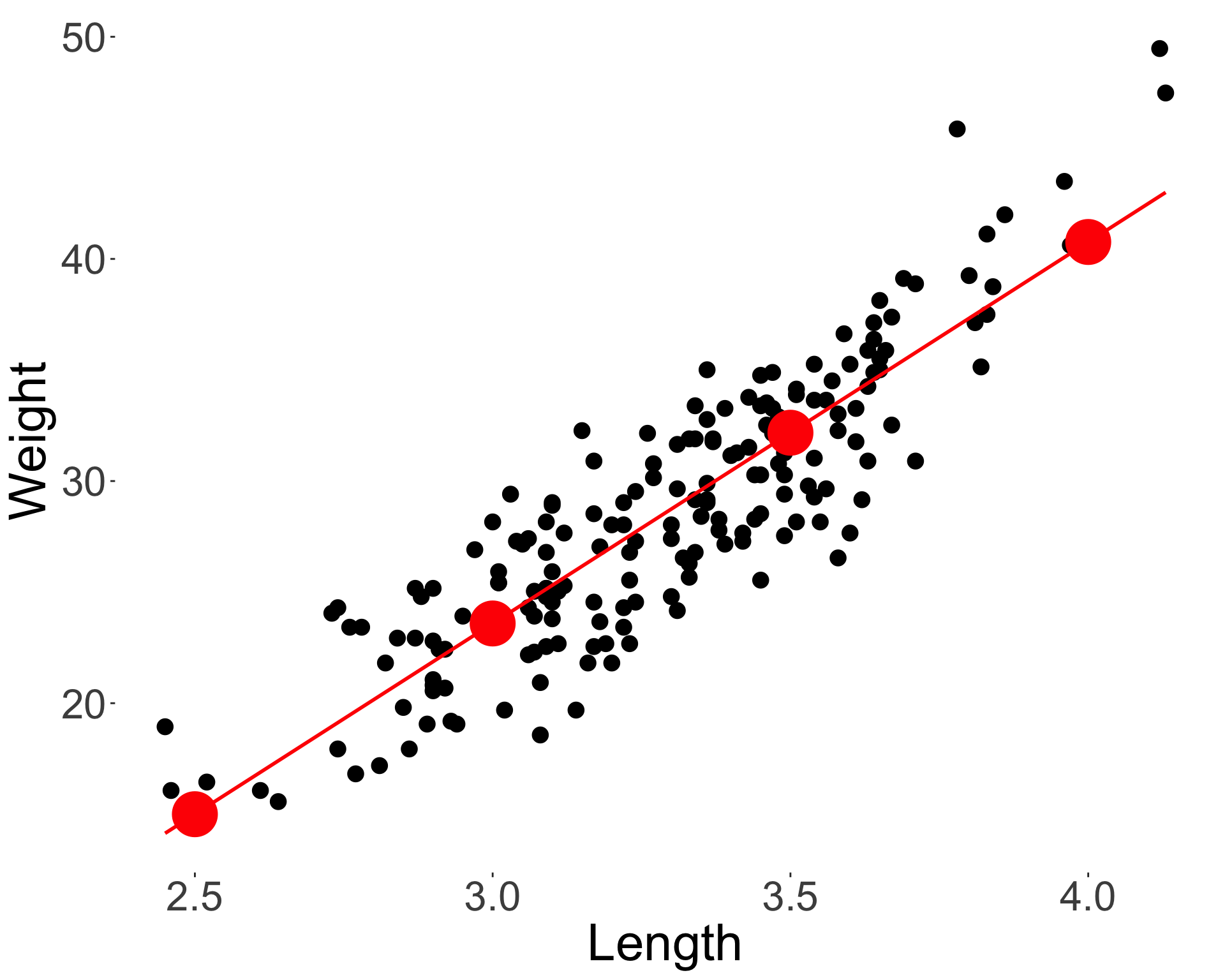
Residuals
- The residuals are the vertical distances from the fitted line to the observed points, given as:
\[\hat{\epsilon}_i = y_i - \hat{y}_i = y_i - (\hat{\beta}_0 + \hat{\beta}_1 x_i).\]
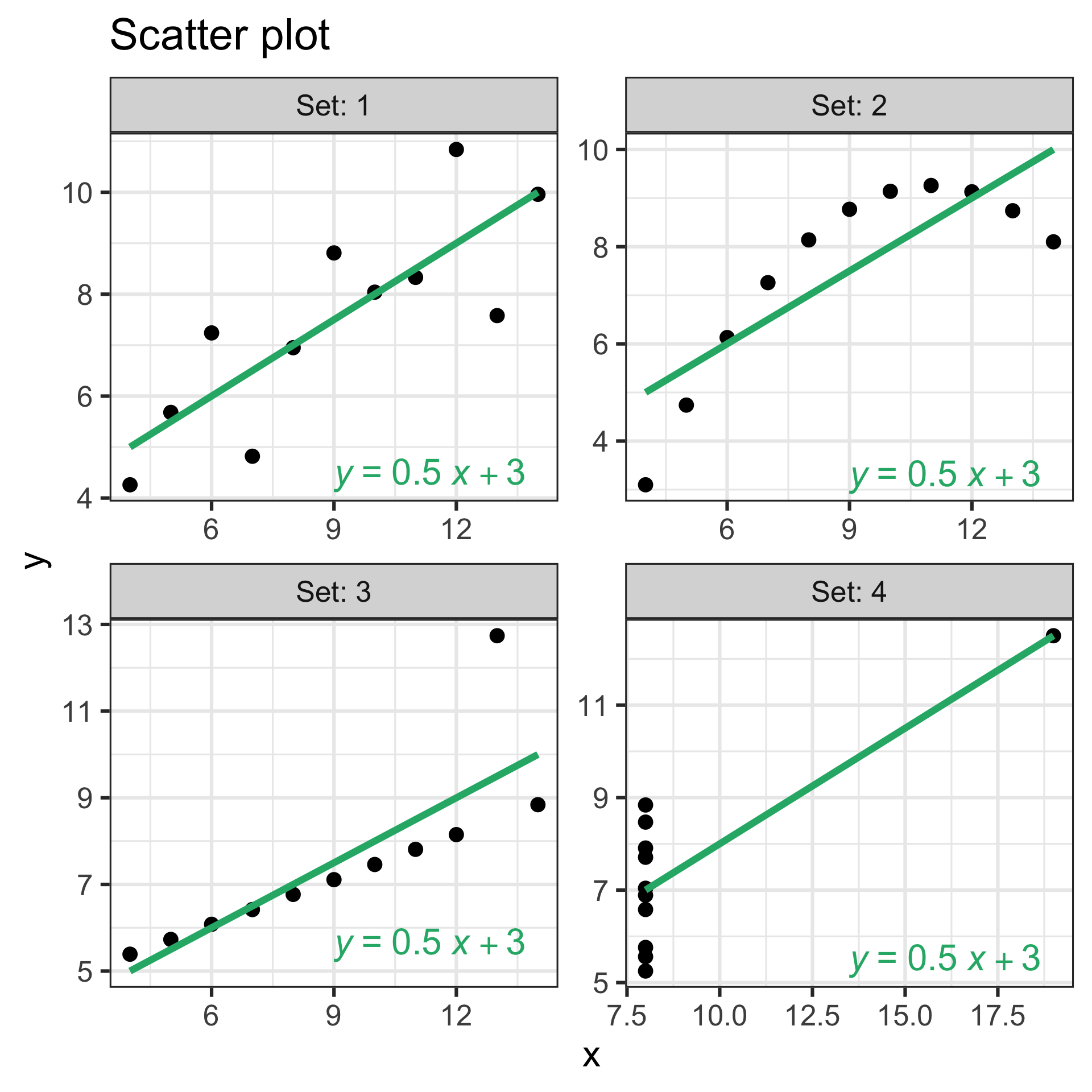
Same regression line, different data
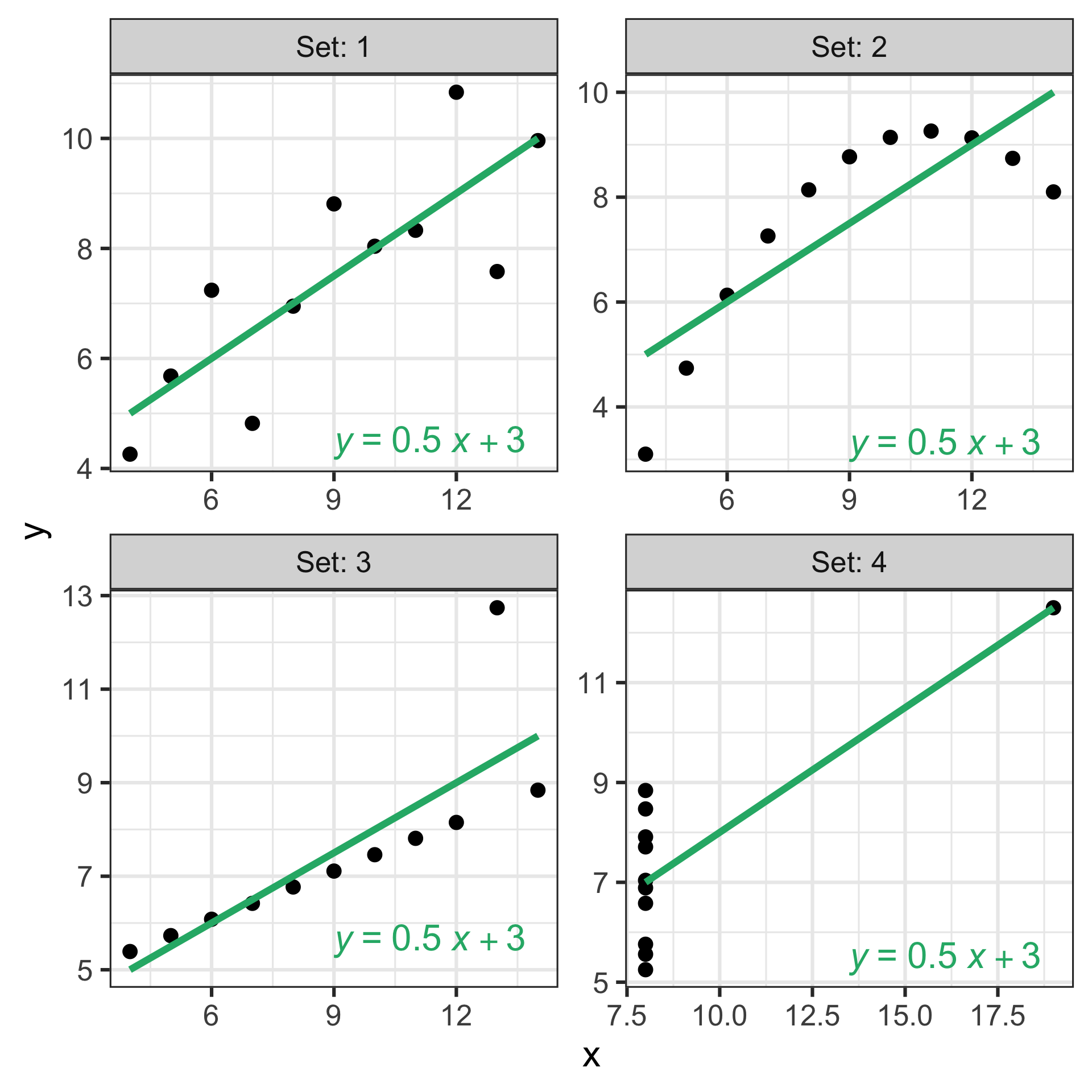
- We can fit a regression model for any data but that doesn’t mean the model is appropriate for the data.
- All four sets of data have the same regression line (same slope and intercept) but they look very different.
- Model diagnostics is important to:
- check the assumptions of the linear regression model are satisfied and
- identify any potential issues with the data that may affect the validity of the model.
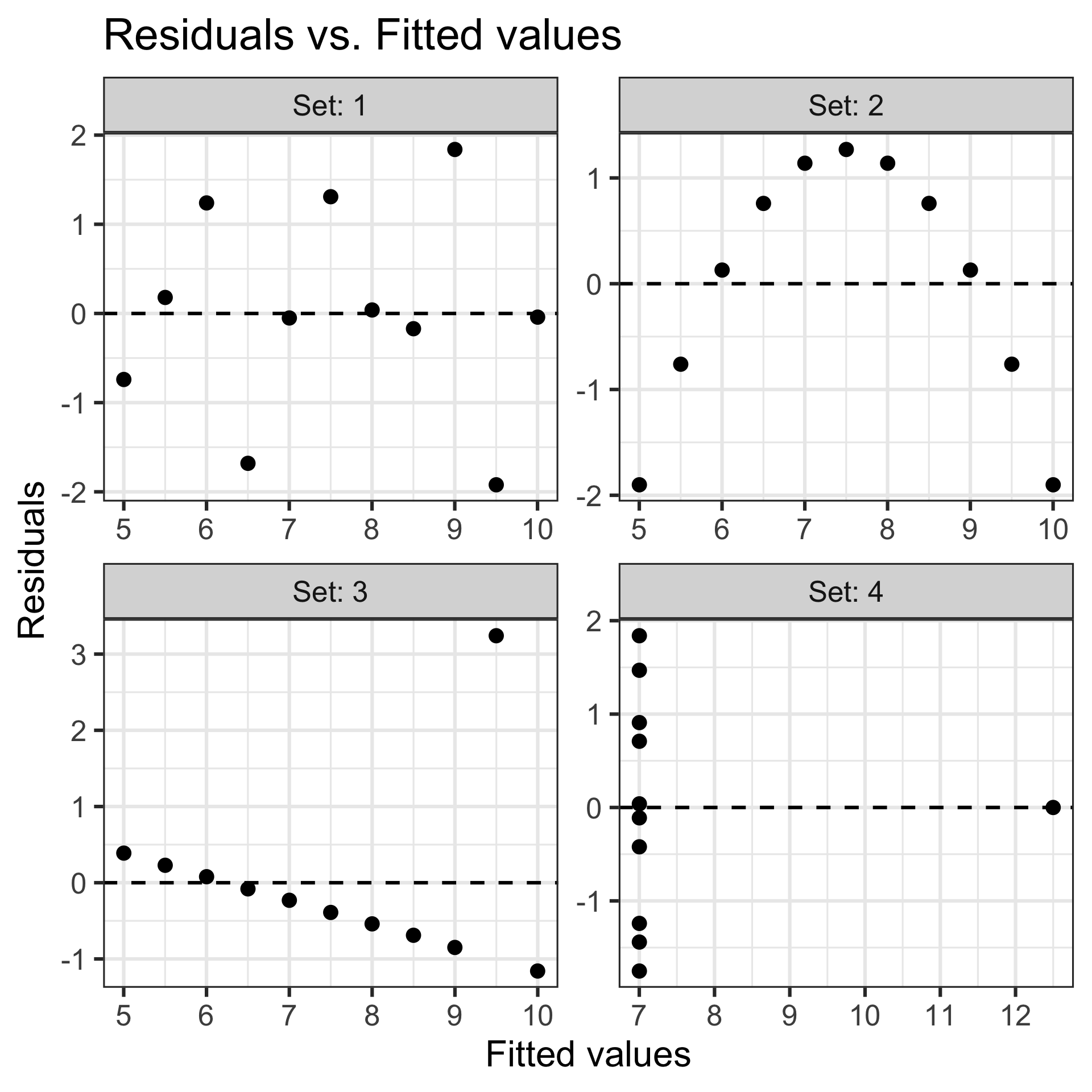
Example: Anscombe’s quartet
Example: influential points in Anscombe’s quartet
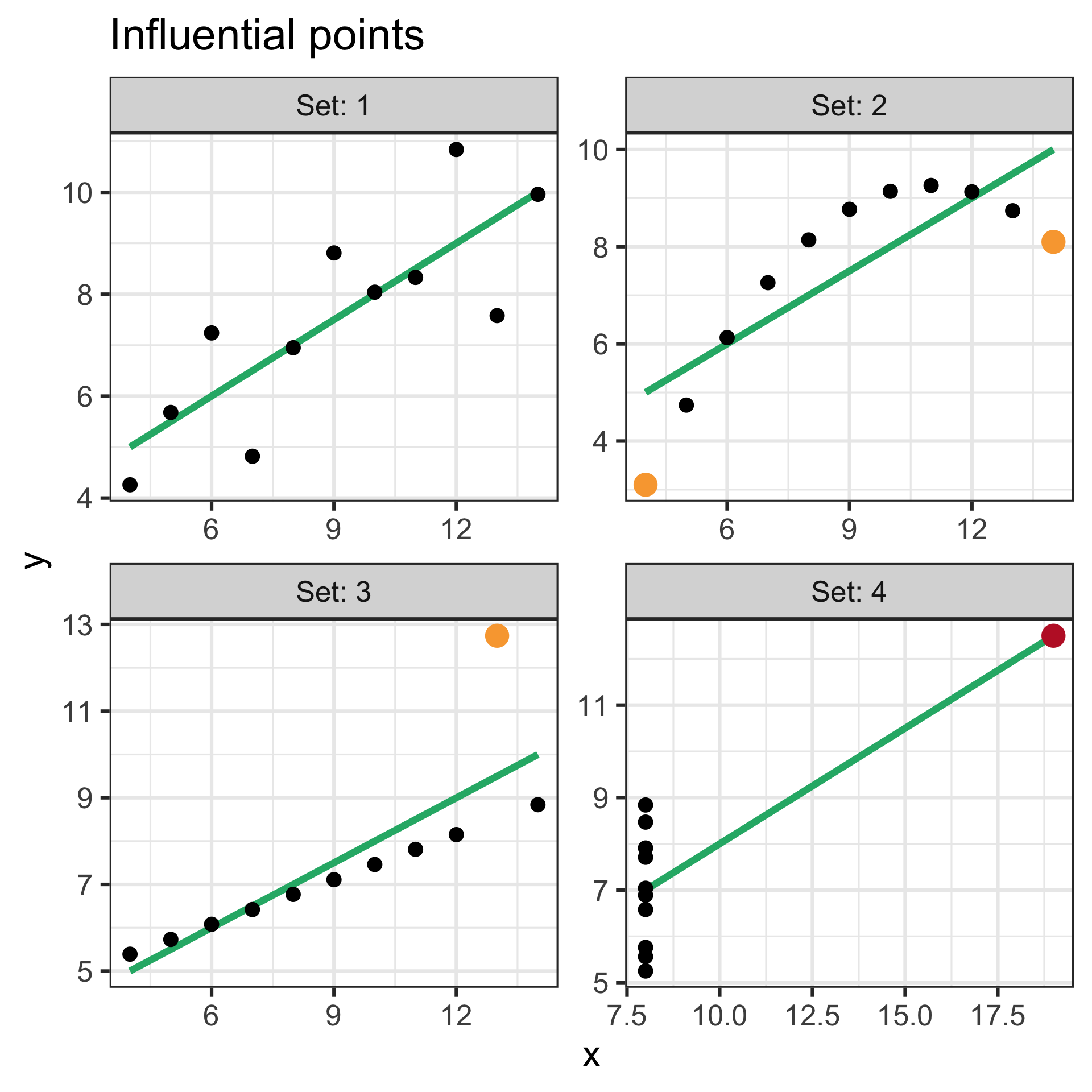
- Outliers based on Cook’s distance are highlighted in orange.
- High leverage points are highlighted in red
- These points may warrant further investigation to determine if they are data entry errors, measurement errors, or valid observations that should be retained in the analysis.
- Do not delete these points without a good reason as they may contain important information about the data and the underlying relationships between the variables.
Summary
scroll
 Source: xkcd
Source: xkcd
- Fitting a linear model:
- Getting the model summary:
- Getting just the regression coefficient estimates
- Getting the regression coefficient table in the model summary as a tibble:
- Getting the fitted values \(\hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i\):
- Getting the residuals \((y_i - \hat{y}_i)\):
- Augment the data with fitted values, residuals, etc:
- Getting the deviance (residual sum of squares):
- The estimate of the error standard deviation \(\hat{\sigma}\):
- Getting the influence measures such as Cook’s distance and leverage values:
- Selecting \(\lambda\) for box-cox transformation:
- Quick diagnostic plots:
- Confidence interval for regression parameters:
- Prediction for mean response:
- Confidence interval for mean response:
- Prediction interval for response:
- Standard error for prediction of mean response: