Hypothesis testing for comparing two population
STAT1003 – Statistical Techniques
Australian National University
These slides are best viewed on a modern browser like Google Chrome on a desktop or laptop. Some interactive components may require some time to fully load.
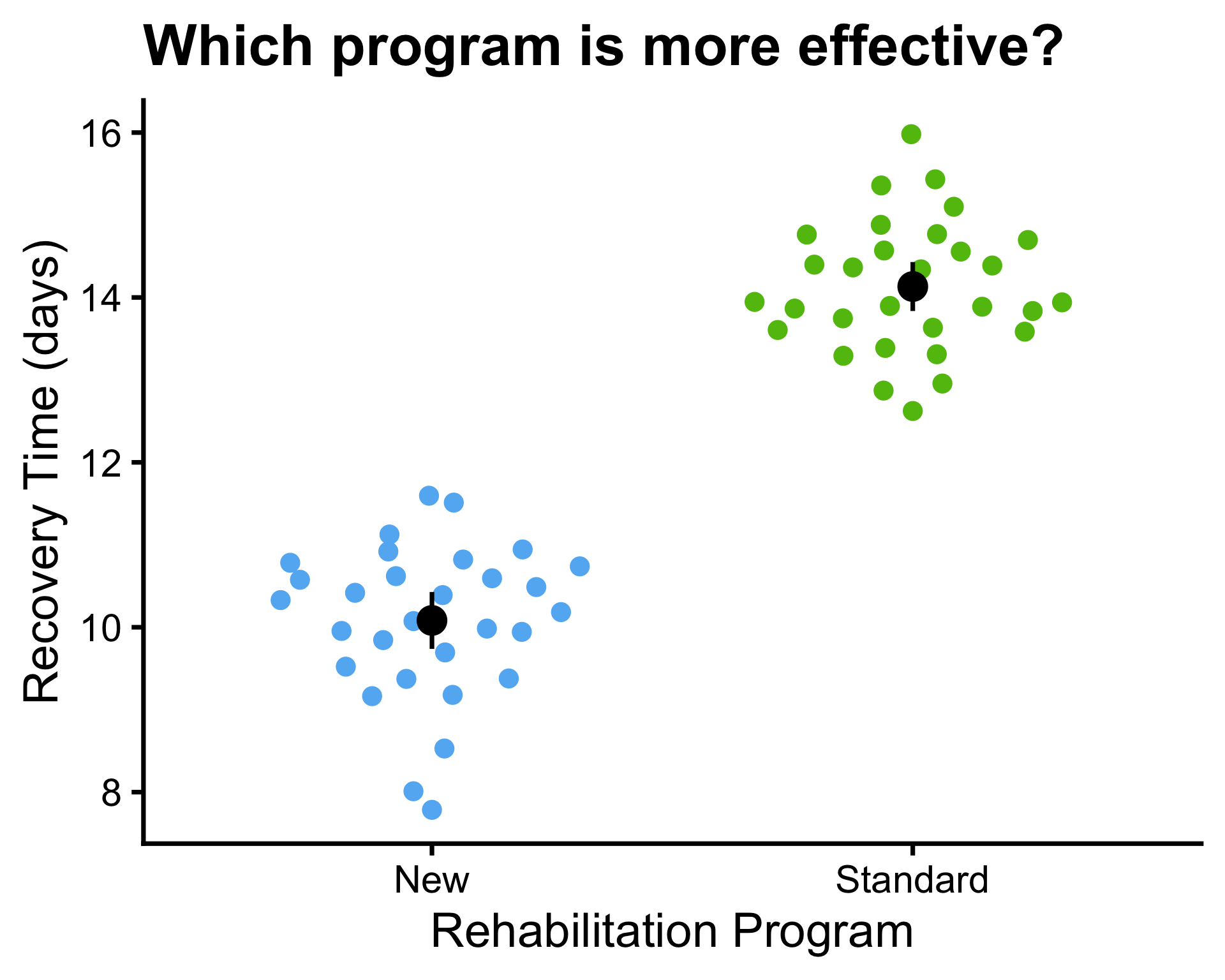
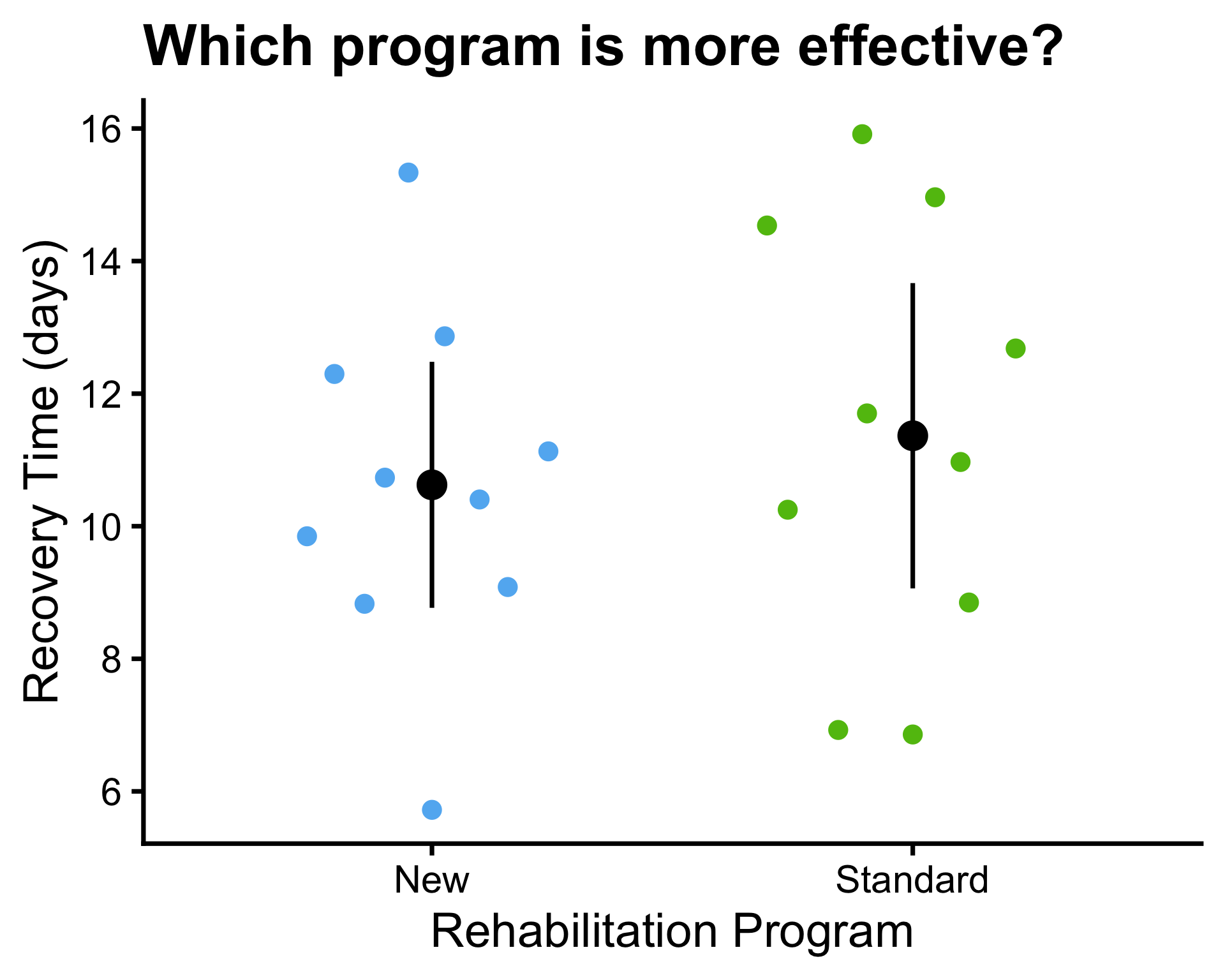
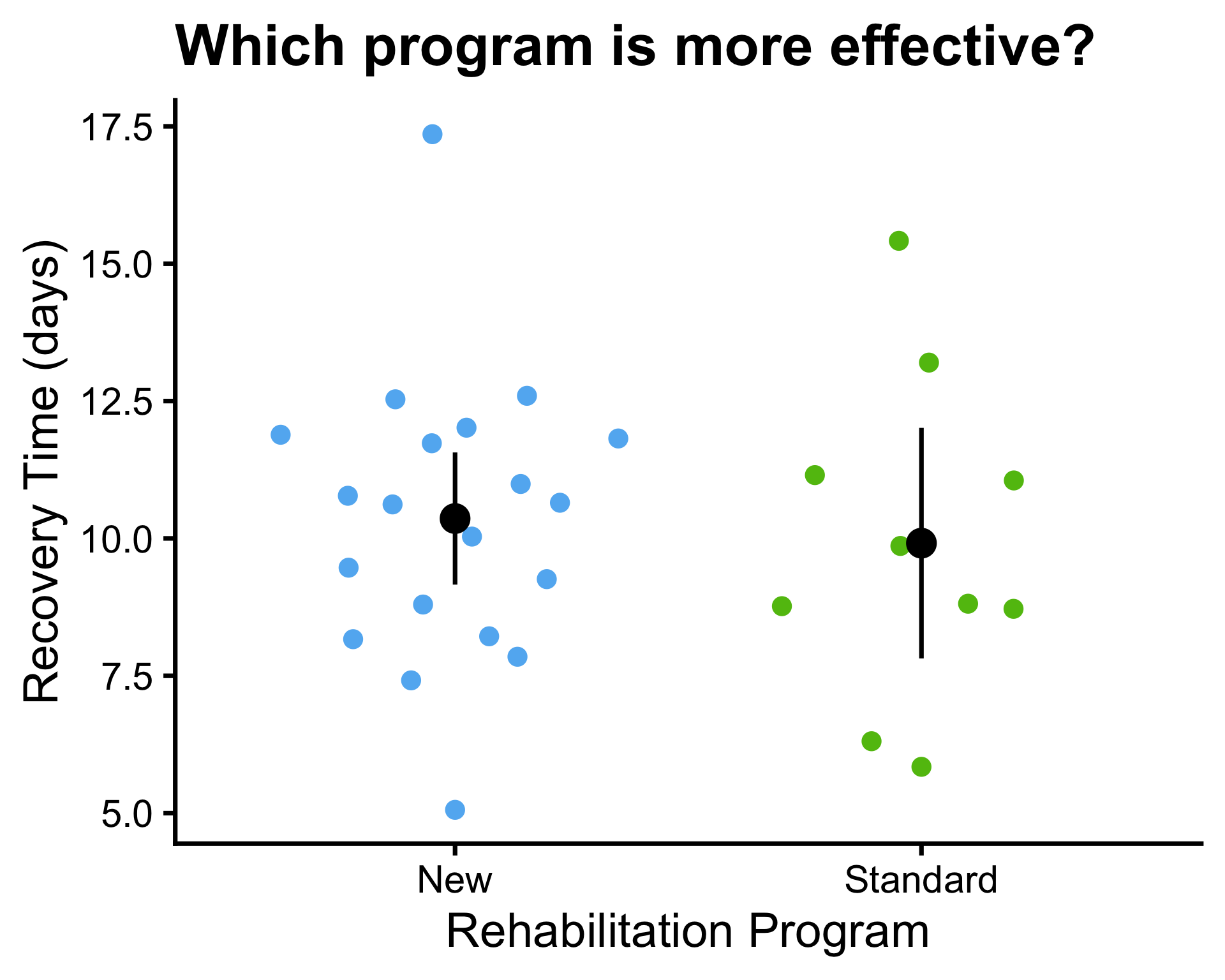
Example: rehabilitation program
- A hospital is comparing two rehabilitation programs (Standard and New) for patients recovering from knee surgery.
- Patients are randomly assigned to one of the two programs.
- The recovery time (in days) until patients can walk unassisted is recorded for each patient.
Is the new program more effective than the standard program in reducing recovery time?
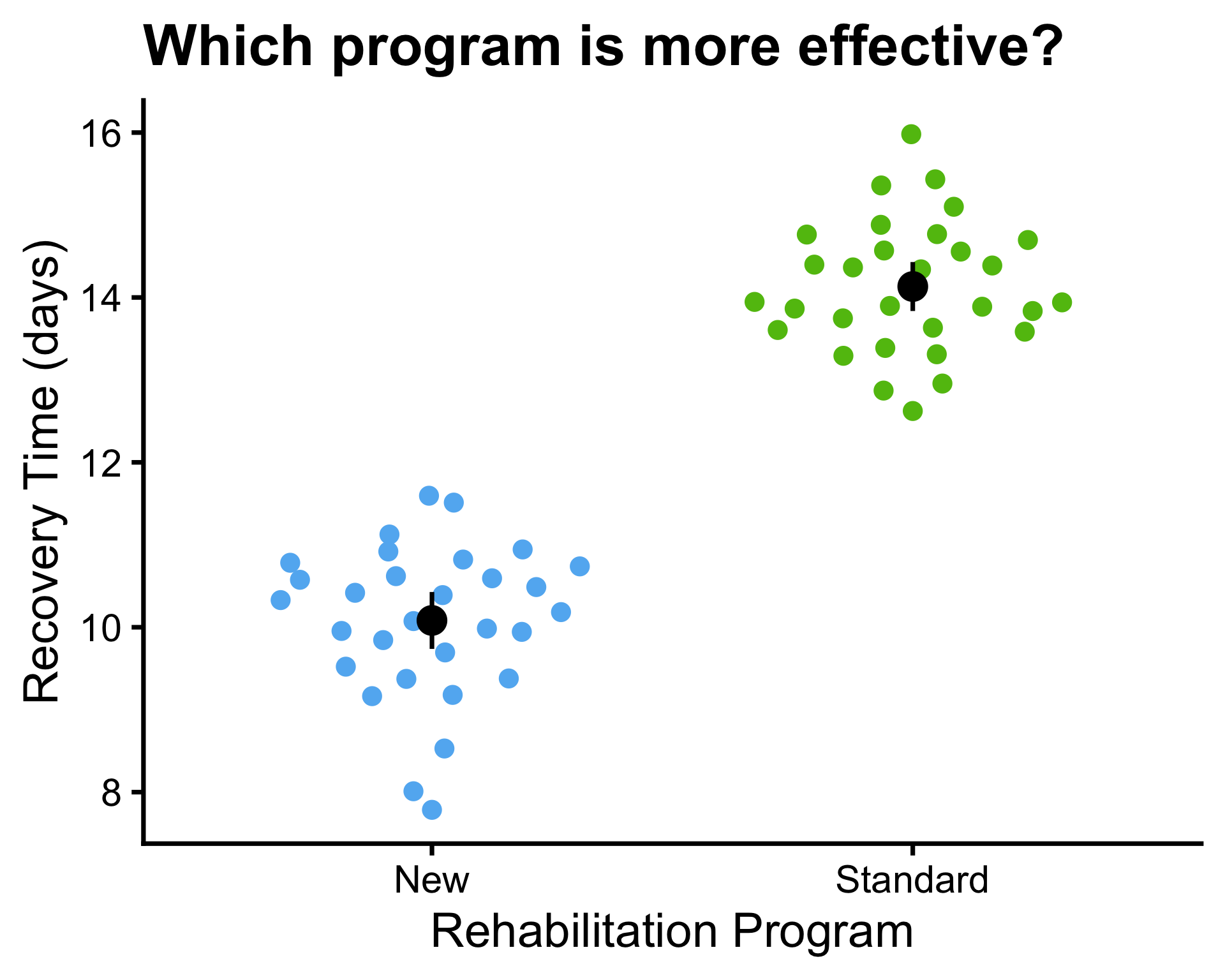
- A beeswarm plot is a type of scatter plot that shows the distribution of a continuous variable across different groups.
- In a beeswarm plot, the data points are arranged in a way that minimizes overlap, allowing for a clearer visualization of the distribution and density of the data within each group.
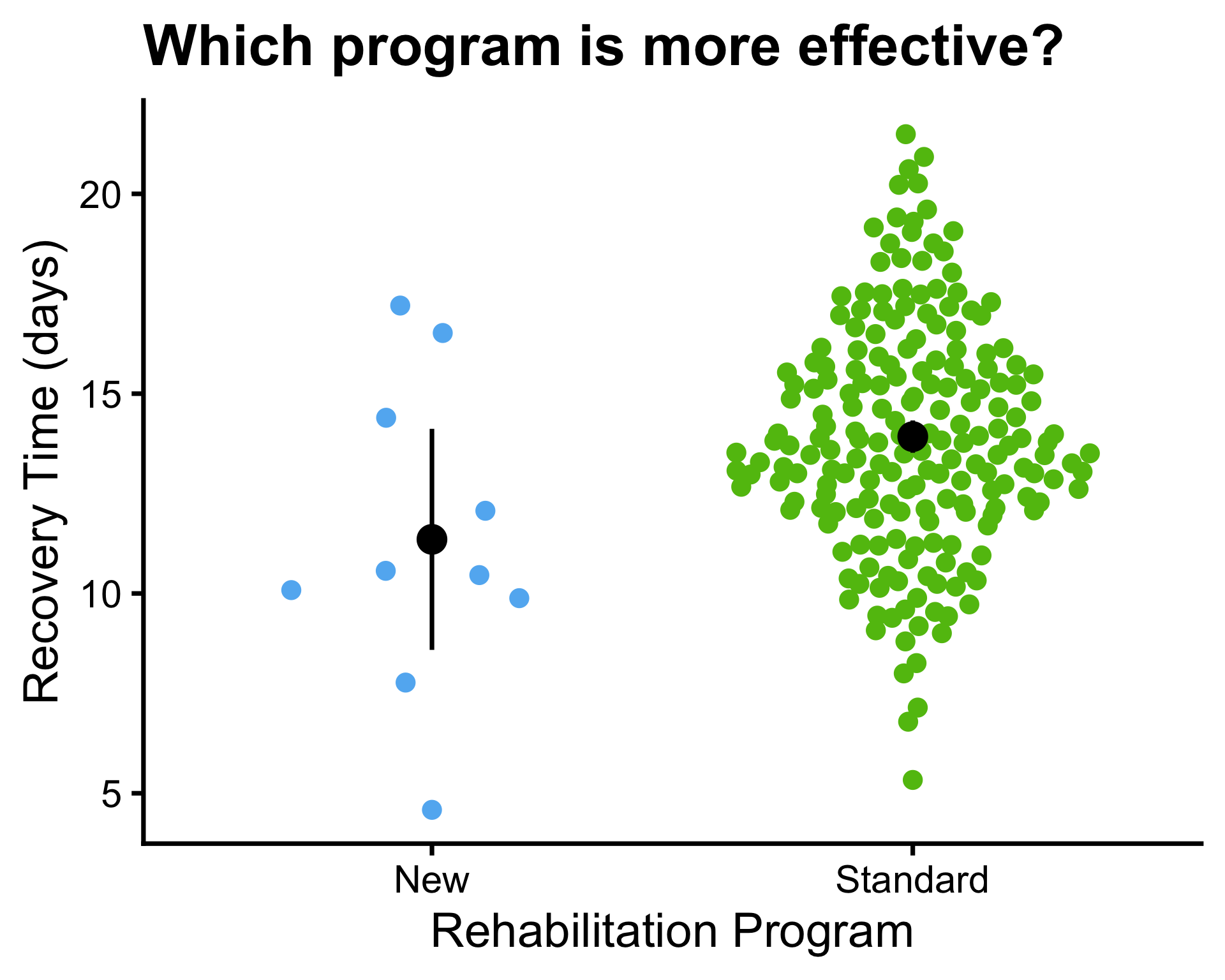
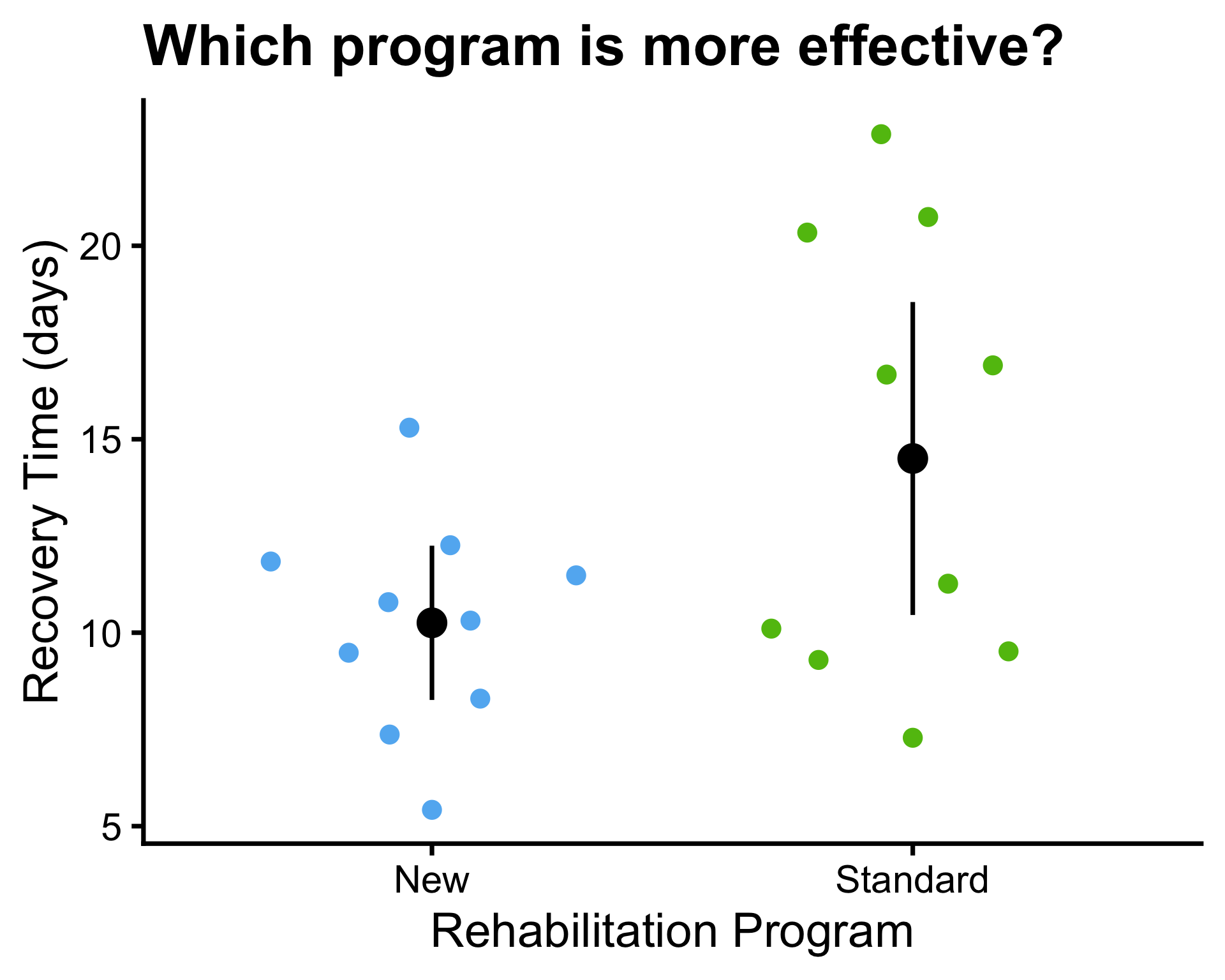
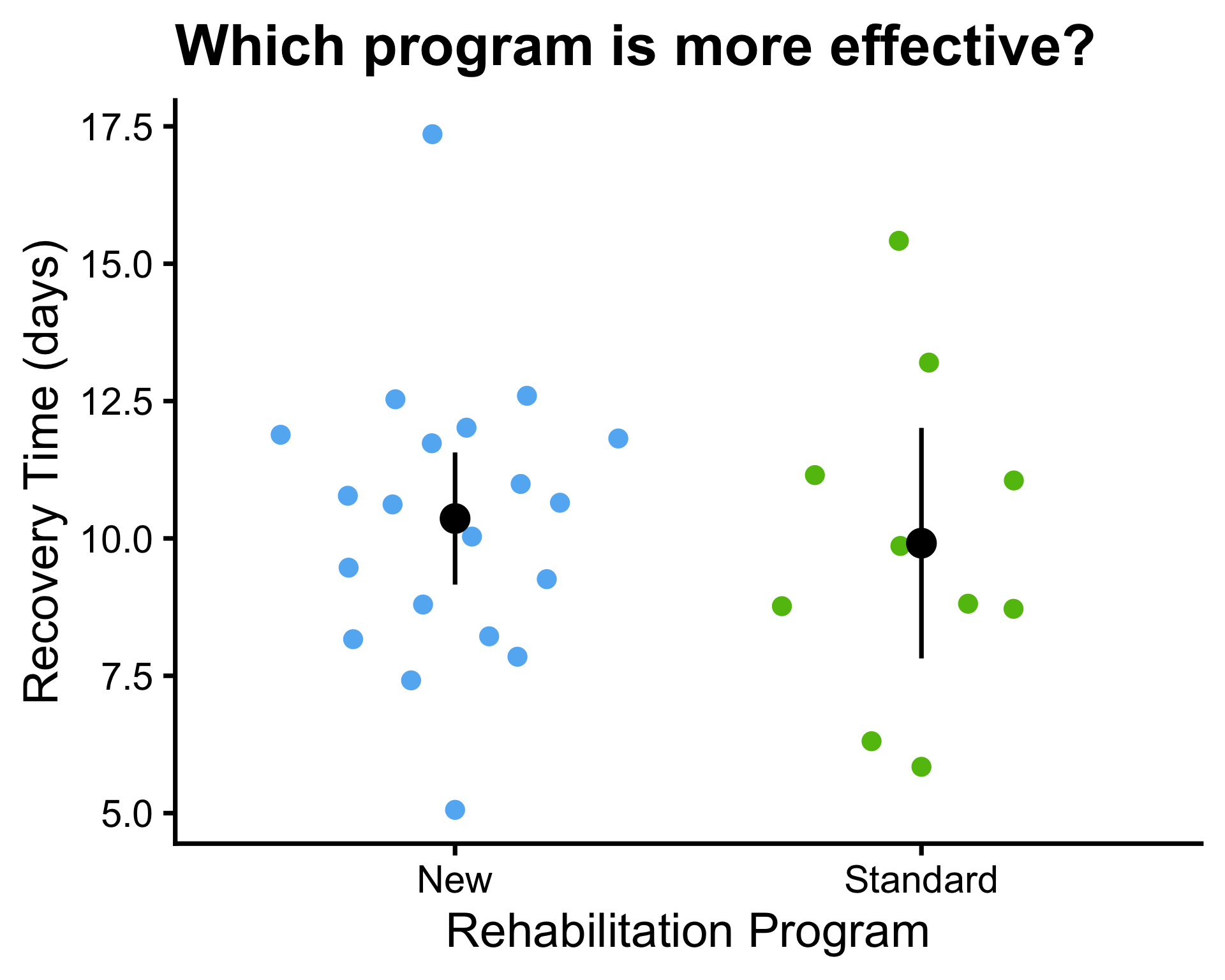
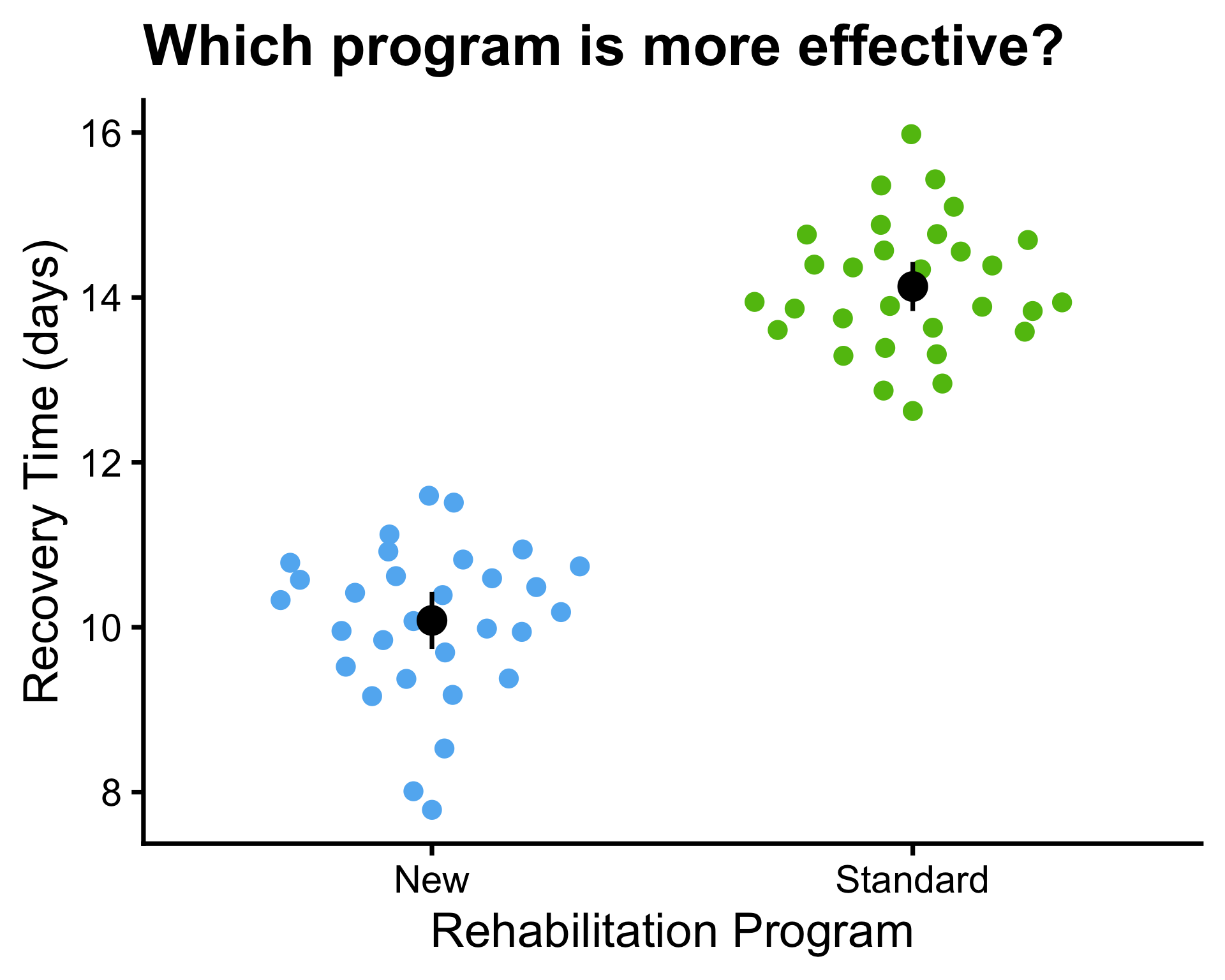
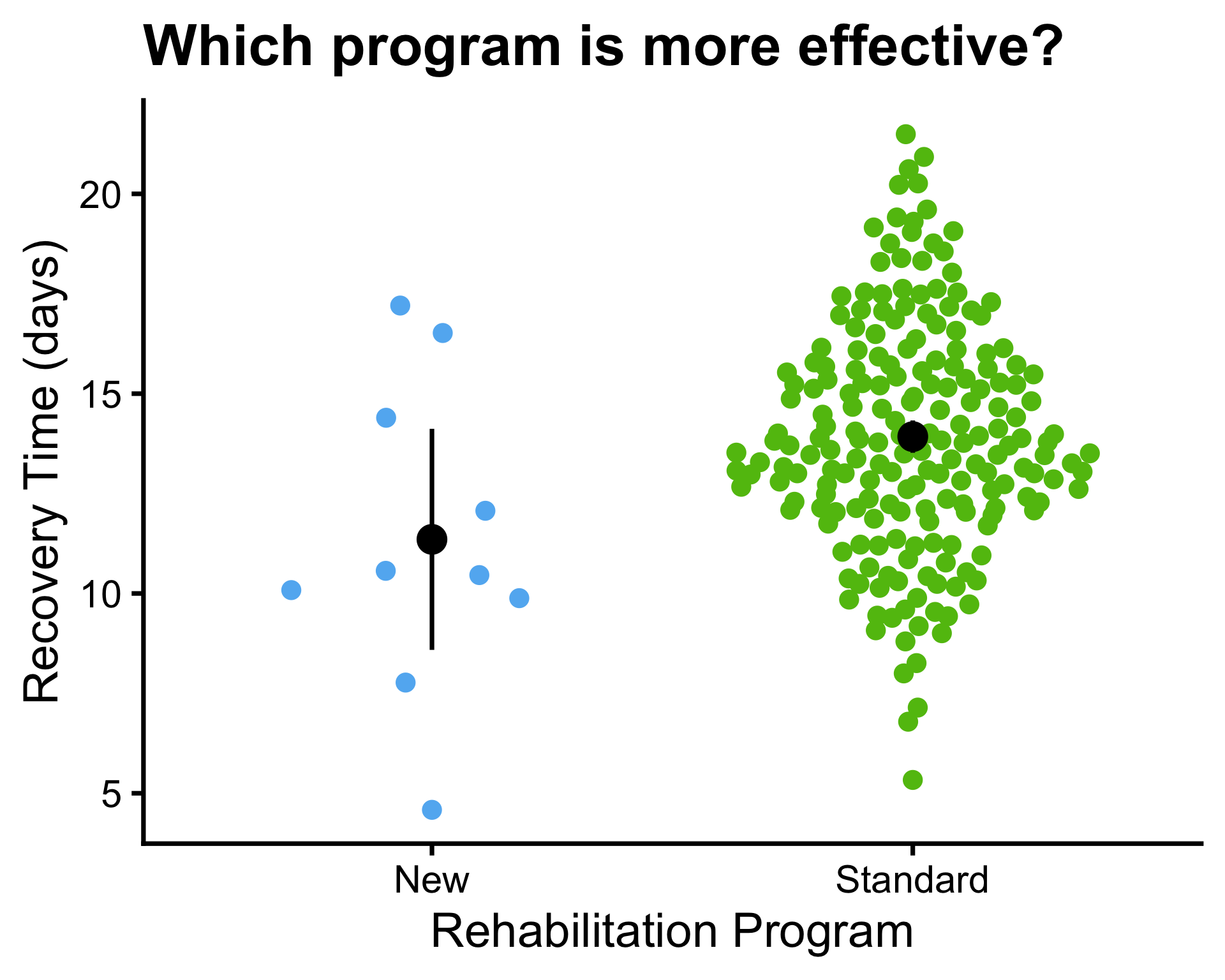
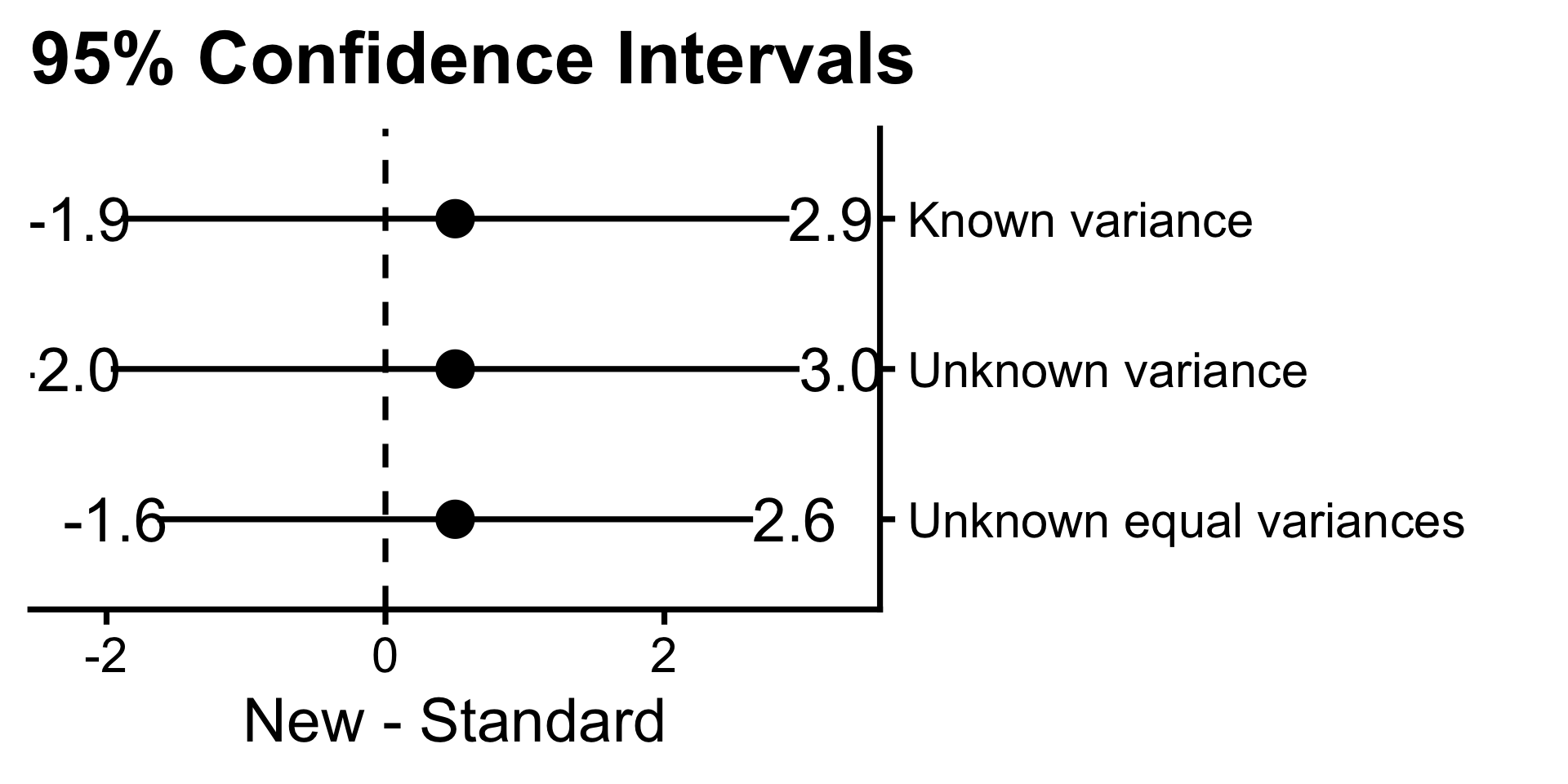
Example: 95% confidence interval
- \(\mu_1 = 10\) and \(\mu_2 = 14\)
- \(\bar{x}_1 = 10.1\) and \(\bar{x}_2 = 14.1\)
- \(\sigma^2_1 = 1\) and \(\sigma^2_2 = 1\)
- \(s_1^2 = 0.85\) and \(s_2^2 = 0.63\), \(s_p^2 = 0.74\)
- \(n_1 = 30\) and \(n_2 = 30\)

- \(\mu_1 = 10\) and \(\mu_2 = 14\)
- \(\bar{x}_1 = 11.4\) and \(\bar{x}_2 = 13.9\)
- \(\sigma^2_1 = 9\) and \(\sigma^2_2 = 9\)
- \(s_1^2 = 14.95\) and \(s_2^2 = 8.4\), \(s_p^2 = 8.69\)
- \(n_1 = 10\) and \(n_2 = 200\)
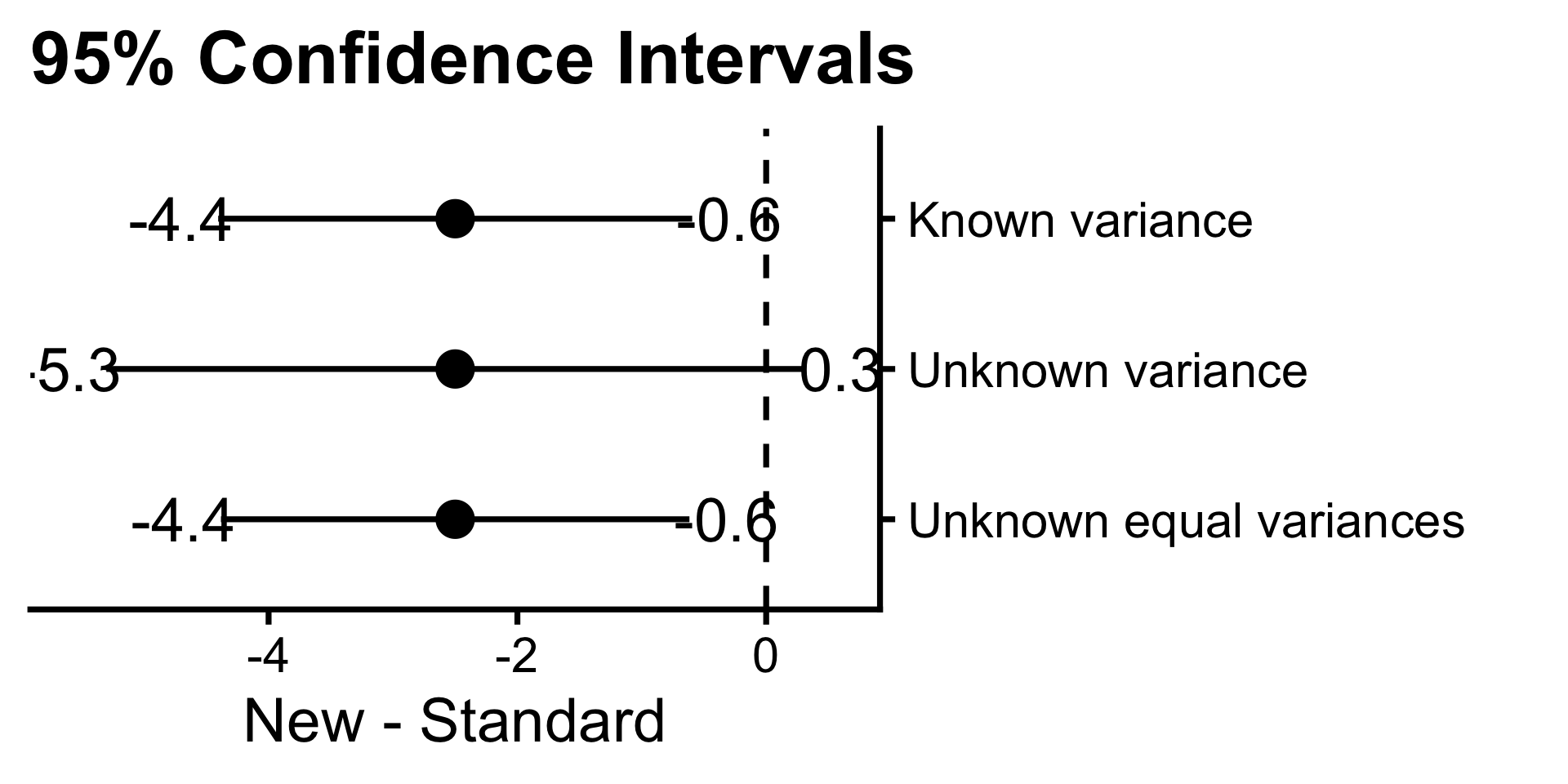
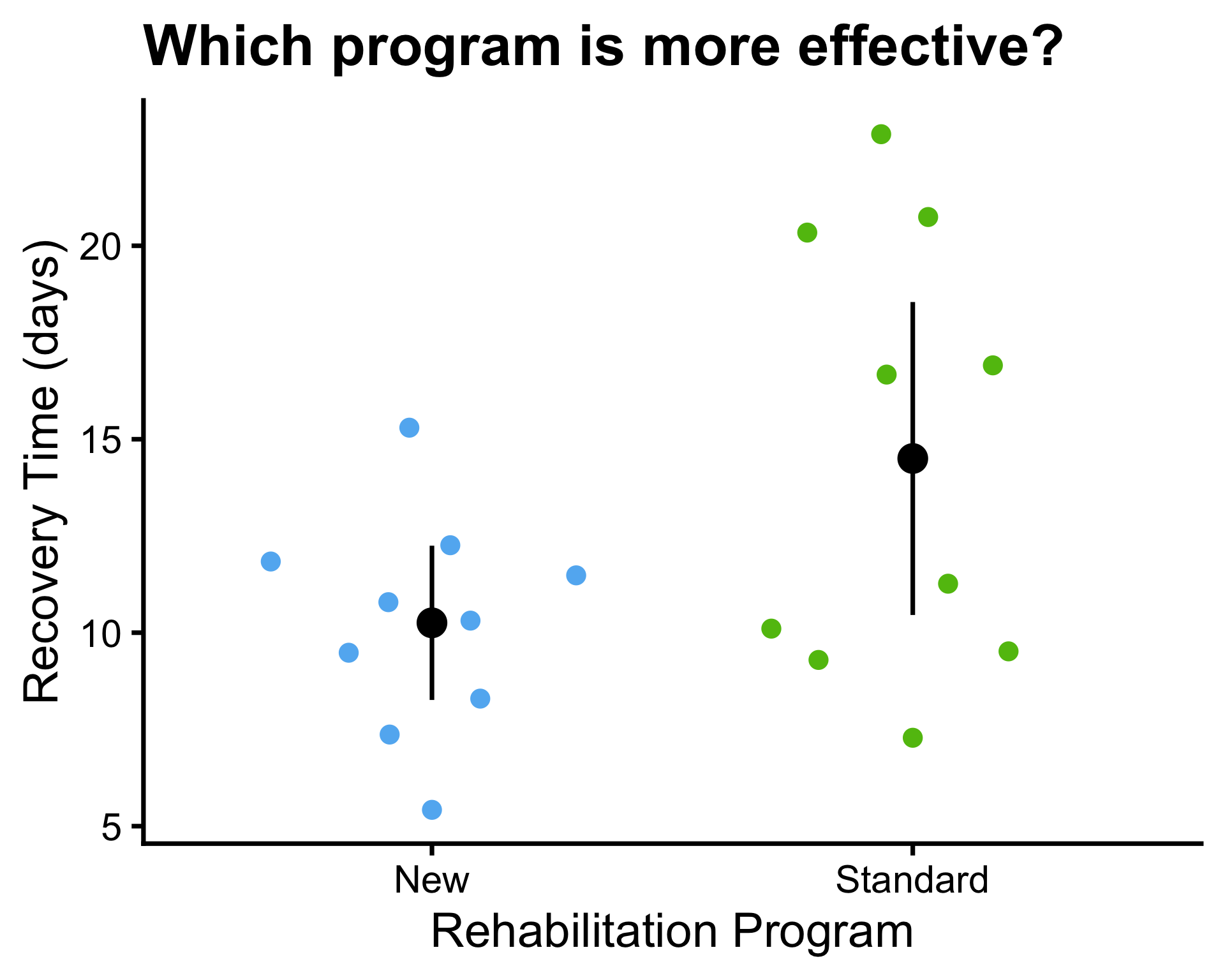
- \(\mu_1 = 10\) and \(\mu_2 = 14\)
- \(\bar{x}_1 = 10.3\) and \(\bar{x}_2 = 14.5\)
- \(\sigma^2_1 = 4\) and \(\sigma^2_2 = 45\)
- \(s_1^2 = 7.77\) and \(s_2^2 = 31.96\), \(s_p^2 = 19.86\)
- \(n_1 = 10\) and \(n_2 = 10\)
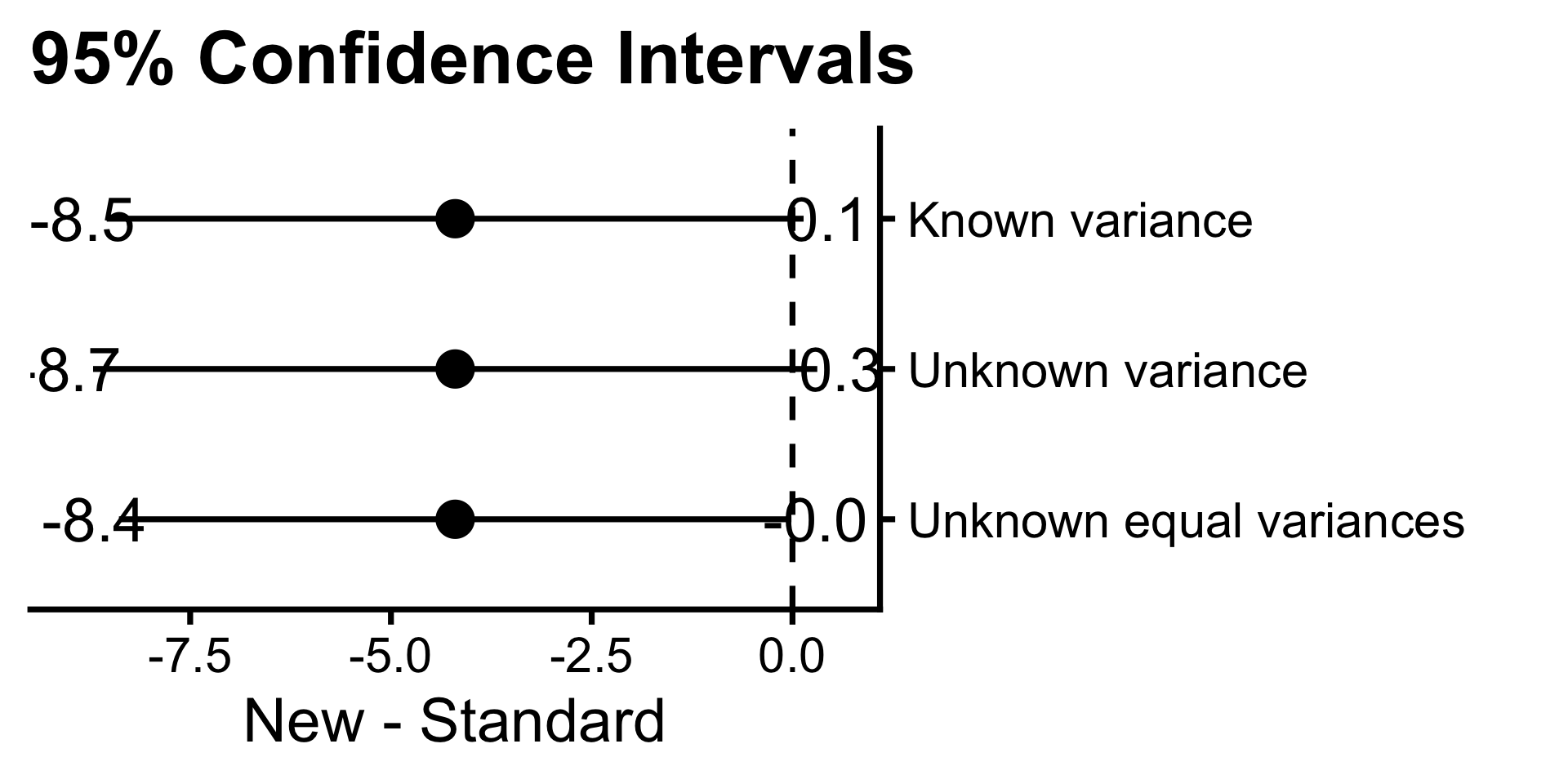
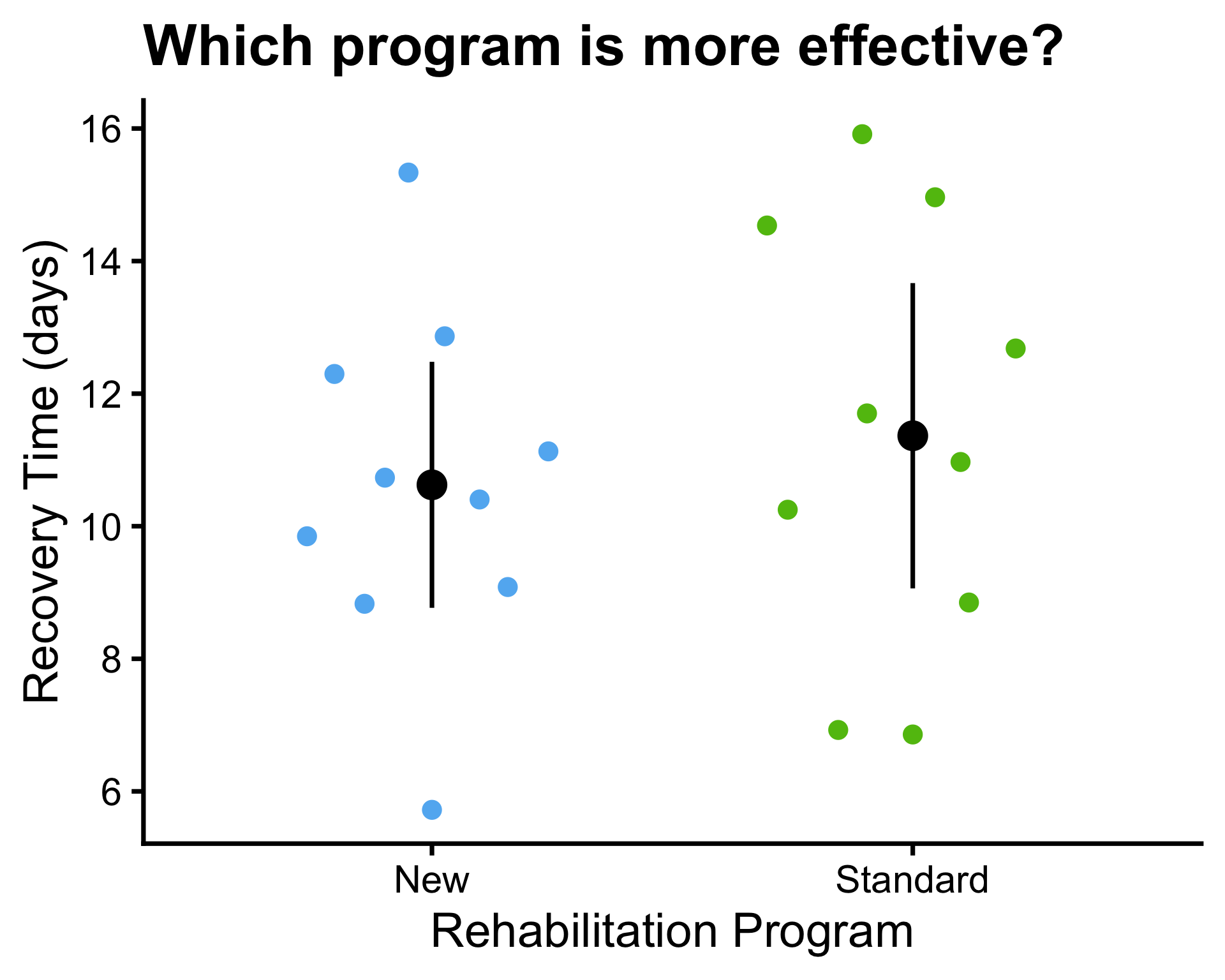
- \(\mu_1 = 10\) and \(\mu_2 = 10\)
- \(\bar{x}_1 = 10.6\) and \(\bar{x}_2 = 11.4\)
- \(\sigma^2_1 = 9\) and \(\sigma^2_2 = 9\)
- \(s_1^2 = 6.73\) and \(s_2^2 = 10.37\), \(s_p^2 = 8.55\)
- \(n_1 = 10\) and \(n_2 = 10\)

- \(\mu_1 = 10\) and \(\mu_2 = 10\)
- \(\bar{x}_1 = 10.4\) and \(\bar{x}_2 = 9.9\)
- \(\sigma^2_1 = 9.89\) and \(\sigma^2_2 = 10\)
- \(s_1^2 = 6.61\) and \(s_2^2 = 8.61\), \(s_p^2 = 7.25\)
- \(n_1 = 20\) and \(n_2 = 10\)
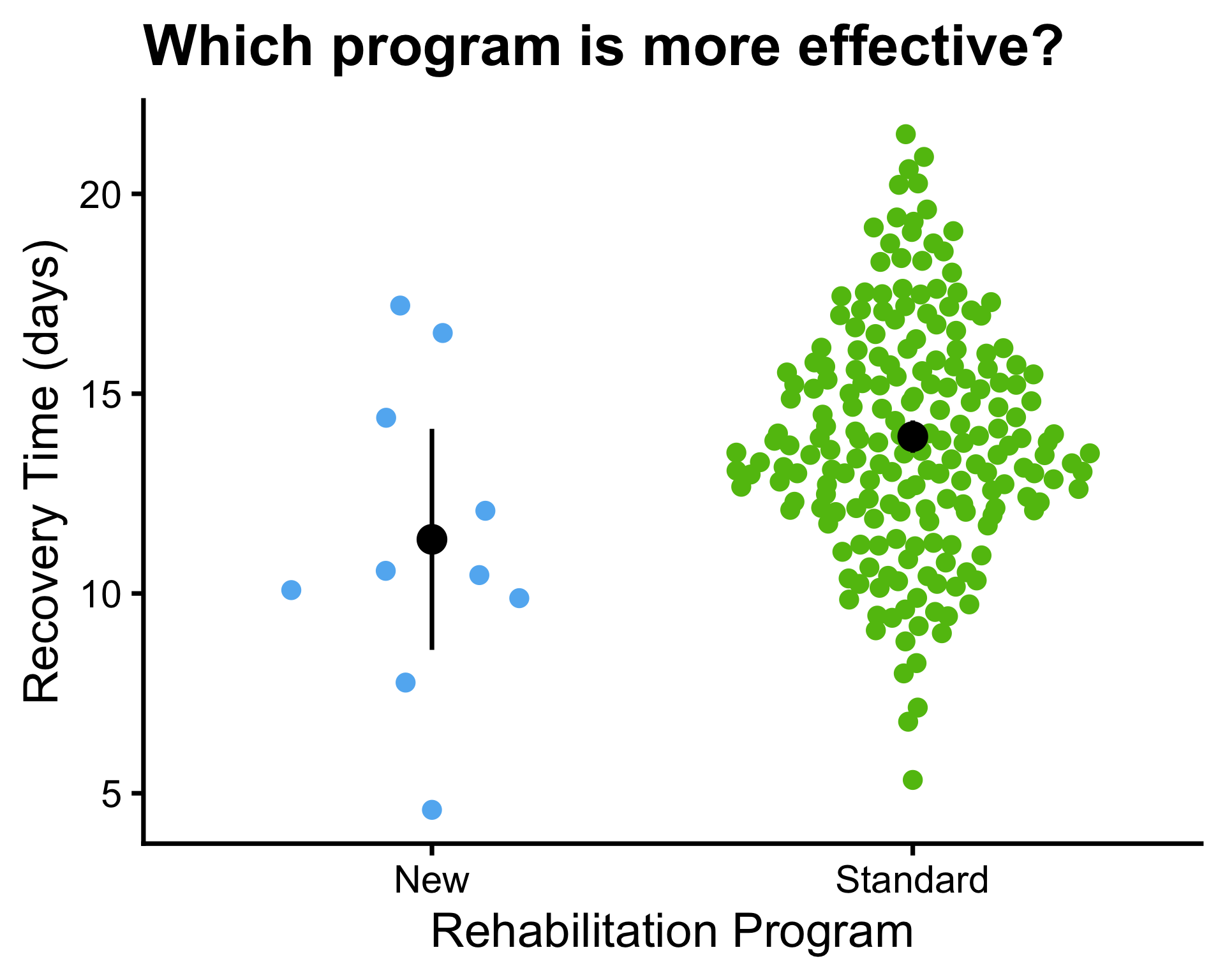
Example: p-values
- \(\mu_1 = 10\) and \(\mu_2 = 14\)
- \(\bar{x}_1 = 10.1\) and \(\bar{x}_2 = 14.1\)
- \(\sigma^2_1 = 1\) and \(\sigma^2_2 = 1\)
- \(s_1^2 = 0.85\) and \(s_2^2 = 0.63\), \(s_p^2 = 0.74\)
- \(n_1 = 30\) and \(n_2 = 30\)
P-values:
- Known variance: \(P(Z \leq -15.49) = 0.0000\)
- Unknown variance: \(P(t_{29} \leq -18.01) = 0.0000\)
- Unknown equal variances: \(P(t_{58} \leq -18.01) = 0.0000\)
- \(\mu_1 = 10\) and \(\mu_2 = 14\)
- \(\bar{x}_1 = 11.4\) and \(\bar{x}_2 = 13.9\)
- \(\sigma^2_1 = 9\) and \(\sigma^2_2 = 9\)
- \(s_1^2 = 14.95\) and \(s_2^2 = 8.4\), \(s_p^2 = 8.69\)
- \(n_1 = 10\) and \(n_2 = 200\)
P-values:
- Known variance: \(P(Z \leq -2.57) = 0.0051\)
- Unknown variance: \(P(t_{9} \leq -2.02) = 0.0371\)
- Unknown equal variances: \(P(t_{208} \leq -2.62) = 0.0047\)
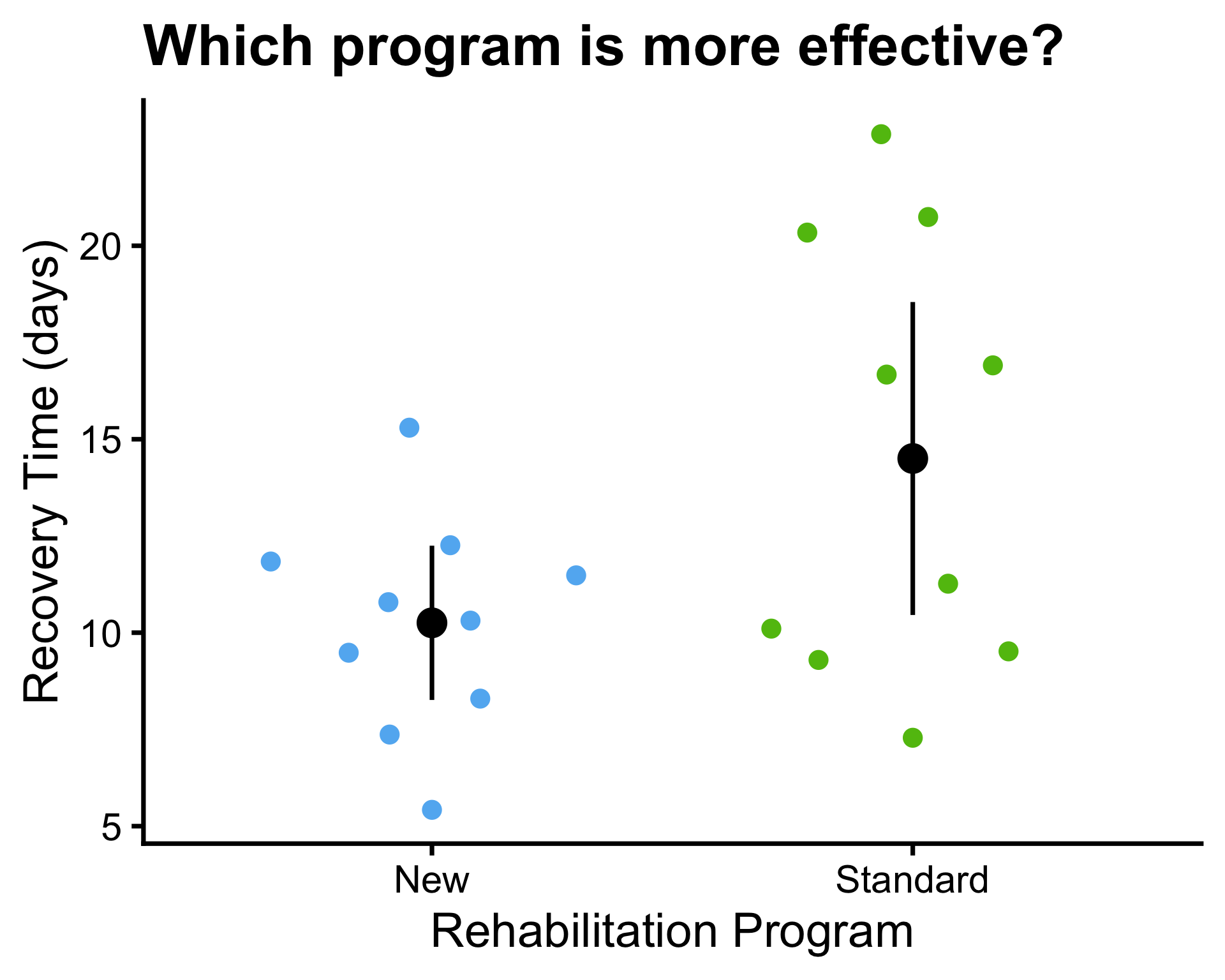
- \(\mu_1 = 10\) and \(\mu_2 = 14\)
- \(\bar{x}_1 = 10.3\) and \(\bar{x}_2 = 14.5\)
- \(\sigma^2_1 = 4\) and \(\sigma^2_2 = 45\)
- \(s_1^2 = 7.77\) and \(s_2^2 = 31.96\), \(s_p^2 = 19.86\)
- \(n_1 = 10\) and \(n_2 = 10\)
P-values:
- Known variance: \(P(Z \leq -1.9) = 0.0287\)
- Unknown variance: \(P(t_{9} \leq -2.11) = 0.0320\)
- Unknown equal variances: \(P(t_{18} \leq -2.11) = 0.0246\)
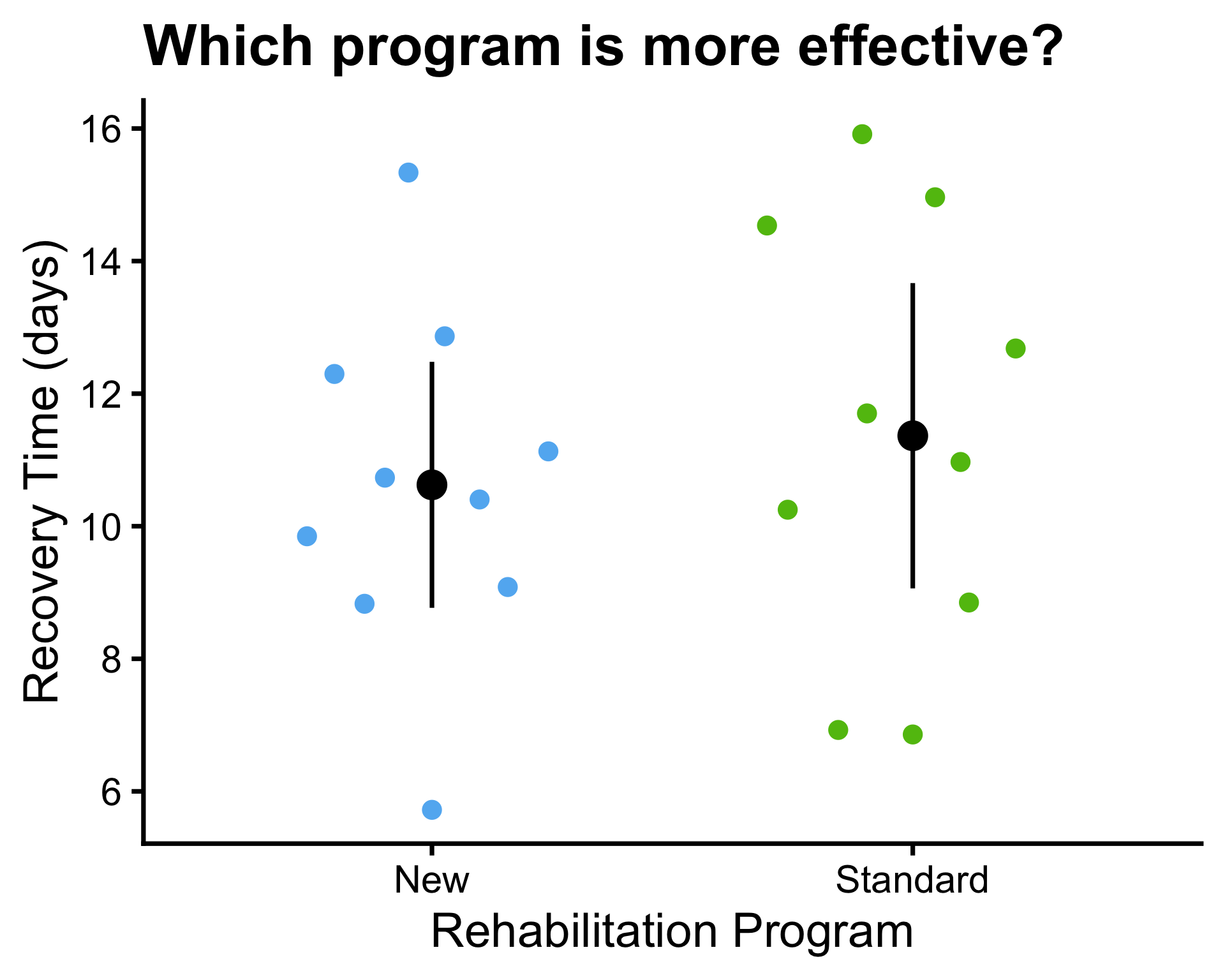
- \(\mu_1 = 10\) and \(\mu_2 = 10\)
- \(\bar{x}_1 = 10.6\) and \(\bar{x}_2 = 11.4\)
- \(\sigma^2_1 = 9\) and \(\sigma^2_2 = 9\)
- \(s_1^2 = 6.73\) and \(s_2^2 = 10.37\), \(s_p^2 = 8.55\)
- \(n_1 = 10\) and \(n_2 = 10\)
P-values:
- Known variance: \(P(Z \leq -0.6) = 0.2743\)
- Unknown variance: \(P(t_{9} \leq -0.61) = 0.2785\)
- Unknown equal variances: \(P(t_{18} \leq -0.61) = 0.2747\)
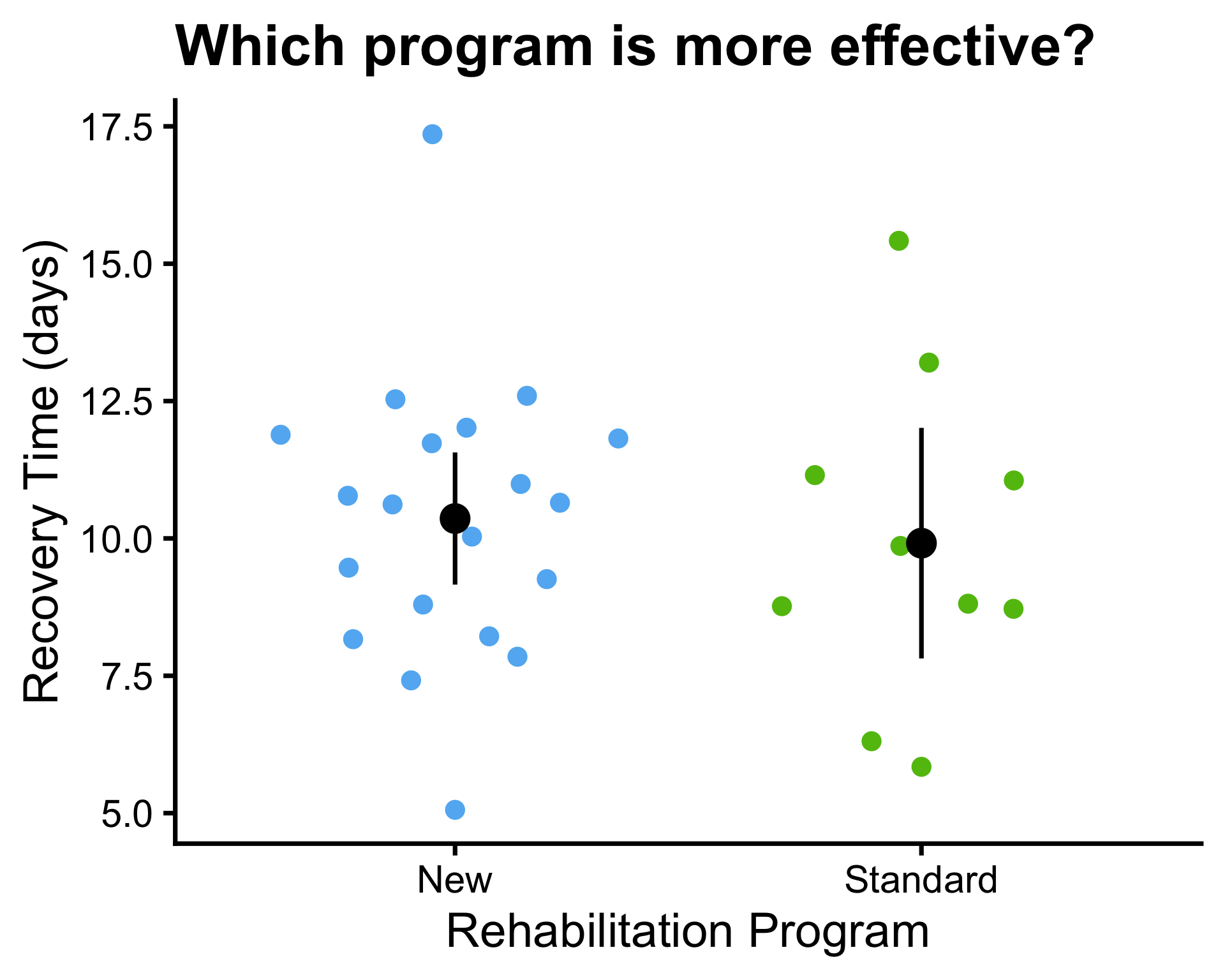
- \(\mu_1 = 10\) and \(\mu_2 = 10\)
- \(\bar{x}_1 = 10.4\) and \(\bar{x}_2 = 9.9\)
- \(\sigma^2_1 = 9.89\) and \(\sigma^2_2 = 10\)
- \(s_1^2 = 6.61\) and \(s_2^2 = 8.61\), \(s_p^2 = 7.25\)
- \(n_1 = 20\) and \(n_2 = 10\)
P-values:
- Known variance: \(P(Z \leq 0.41) = 0.6591\)
- Unknown variance: \(P(t_{9} \leq 0.46) = 0.6718\)
- Unknown equal variances: \(P(t_{28} \leq 0.48) = 0.6825\)
Paired data
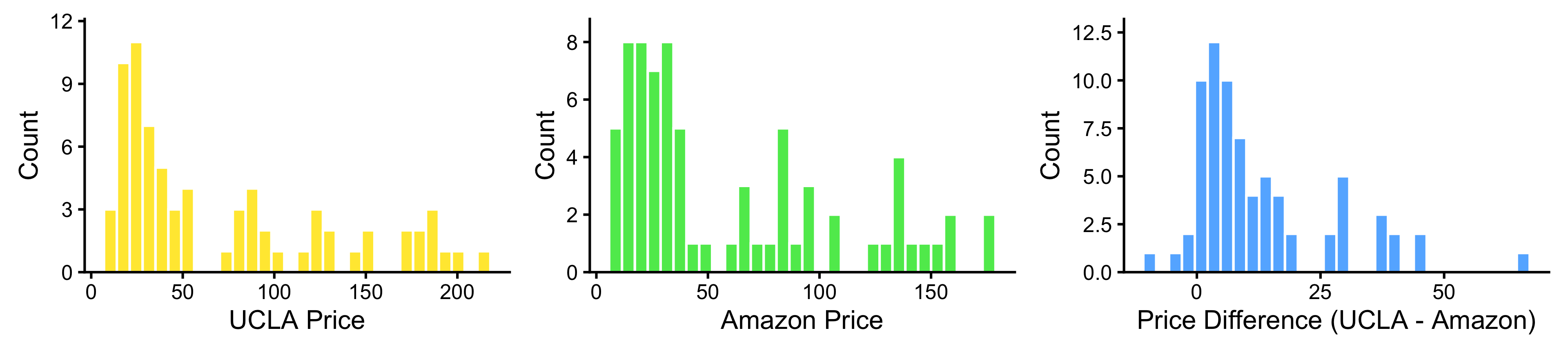
- The price of the same textbook on Amazon and the university bookstore are paired data.
- Let:
- \(X_{1i}\) be the price of the \(i\)-th textbook at the university bookstore,
- \(X_{2i}\) be the price of the \(i\)-th textbook on Amazon, and
- \(X_{di} = X_{1i} - X_{2i}\) be the price difference for the \(i\)-th textbook.
- For paired data, we are often interested in the difference between the two responses, \(D_i\), effectively reducing the problem to a one-sample.