Hypothesis Testing for a Single Population
STAT1003 – Statistical Techniques
Australian National University
These slides are best viewed on a modern browser like Google Chrome on a desktop or laptop. Some interactive components may require some time to fully load.
Statistical inference
Estimation (last topic)
Draw inferences about a population by estimating population parameters from a sample (point and interval estimators).
Hypothesis testing (this topic)
Draw inferences about a population by making a claim or hypothesis about a population parameter and testing whether the hypothesis is supported by the sample.

The judicial system
- In a criminal court case, the defendant is either:
- not guilty of the alleged crime or
- guilty of the alleged crime.
- The prosecutor and the defence lawyer present their evidence with assumptions to the jury and/or judge during the trial.
- The jury has to decide whether to convict the defendant or not based on the evidence.
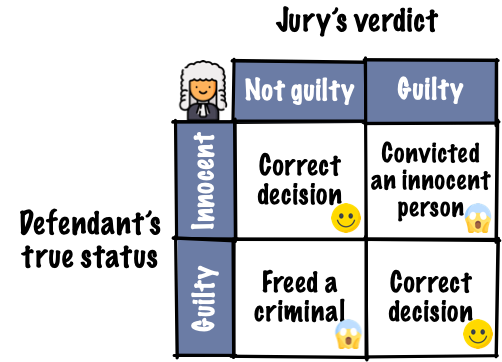
The “statistical” judicial system
- In a “statistical” court case, there are two competing hypotheses:
- The null hypothesis (\(H_0\)) or
- The alternative hypothesis (\(H_A\) or \(H_1\)).
- A sample of data is collected and a test statistic under assumptions provides evidence to test the \(H_0\).
- Based on the strength of evidence, we decide whether to reject the \(H_0\) or not.
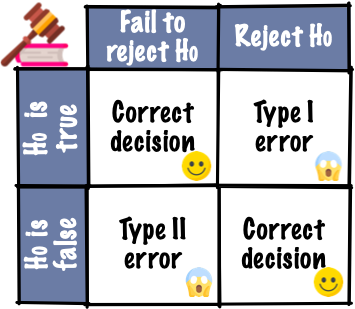
Two types of errors can occur in this process:
- Type I error: rejecting the \(H_0\) when it is actually true.
- Type II error: failing to reject the \(H_0\) when the \(H_A\) is actually true.
Example: Is this coin biased towards heads?
Suppose I have a coin that I’m going to flip

I have some suspicion that the coin has been tweaked to be biased towards heads.
Let \(p\) be the probability of getting a head.
If the coin is biased towards heads, then
So how would we test if a coin is biased towards head or not?
We’ll collect some data.
I flipped the coin 10 times and this is the result:

- The result is 7 head and 3 tails. So 70% are heads.
- Do you believe the coin is biased towards heads based on this data?
Example: Is this coin biased towards heads?
Suppose now I flip the coin 200 times and this is the outcome:
- We observe 140 heads and 60 tails. So again 70% are heads.
- Based on this data, do you think the coin is biased towards heads?
- If the coin was fair, how many heads did you expect to see?
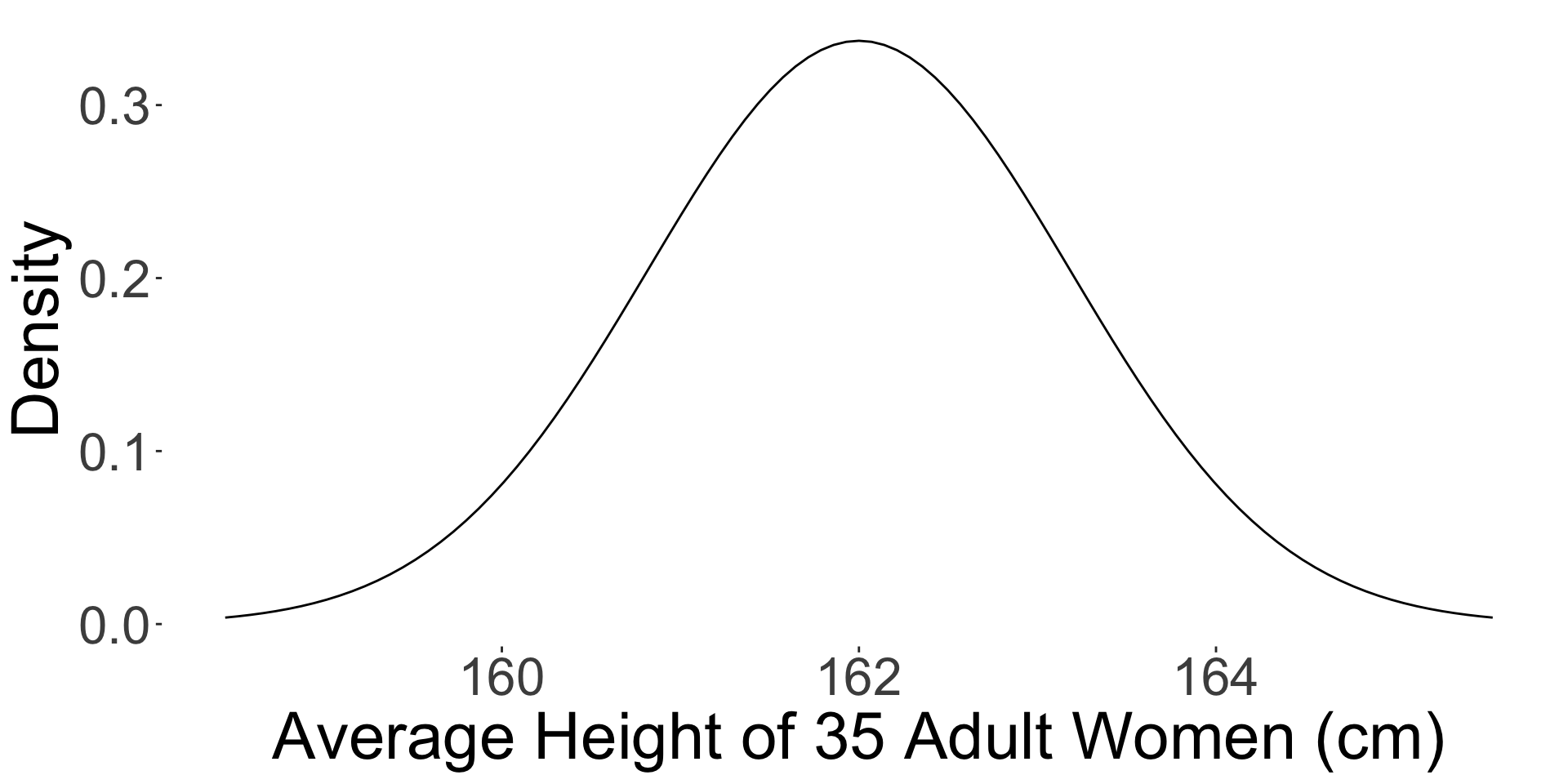
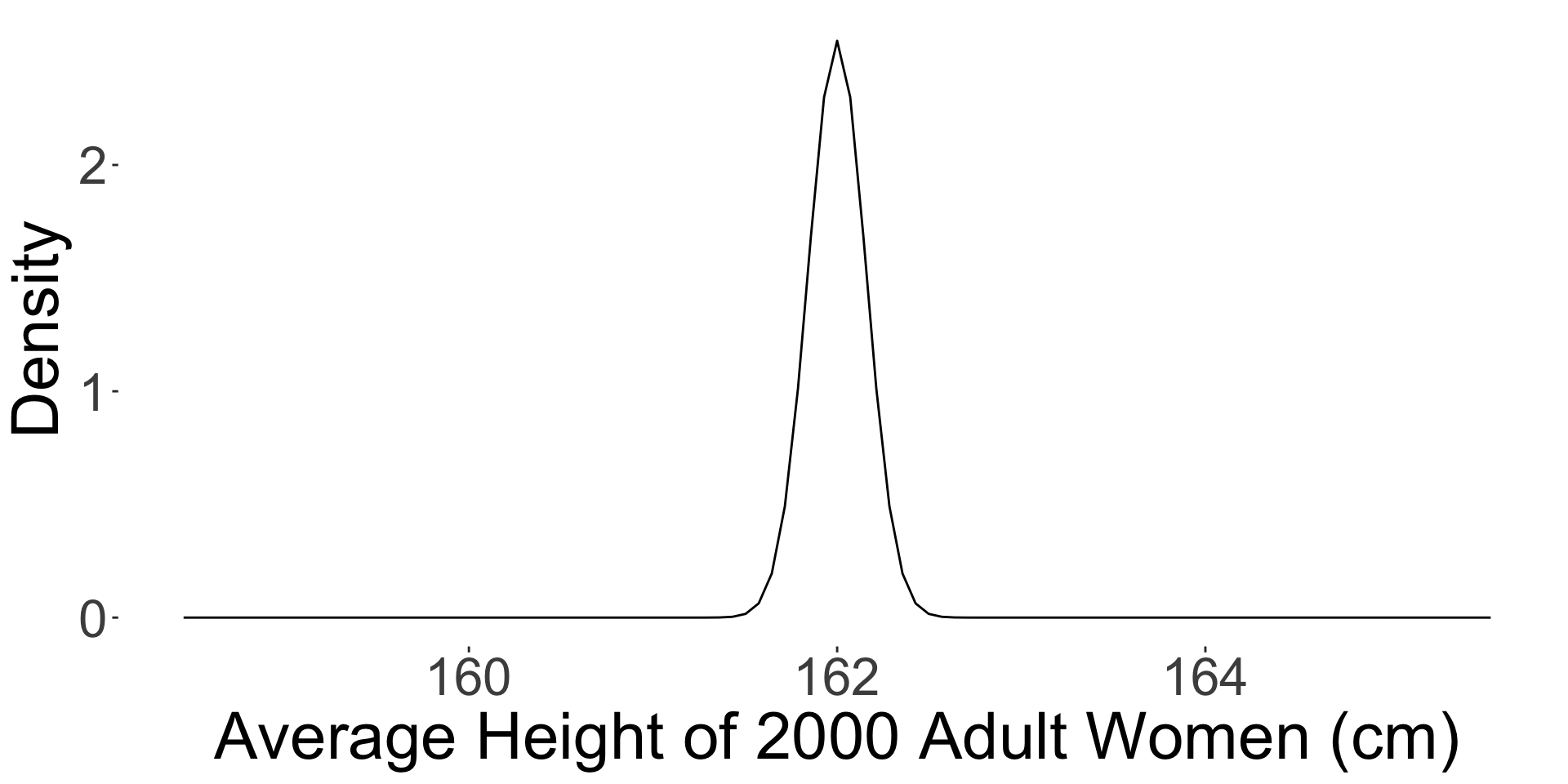
Example: adult height
I am 160 cm tall.
Am I significantly shorter than the average adult woman in Australia?
- I collect a random sample of 35 adult women in Australia and measure their heights.
- The sample mean height is 162 cm and the sample standard deviation is 7 cm.
- I collect a random sample of 2000 adult women in Australia and measure their heights.
- The sample mean height is 162 cm and the sample standard deviation is 7 cm.