Continuous parametric distributions
STAT1003 – Statistical Techniques
Australian National University
These slides are best viewed on a modern browser like Google Chrome on a desktop or laptop. Some interactive components may require some time to fully load.
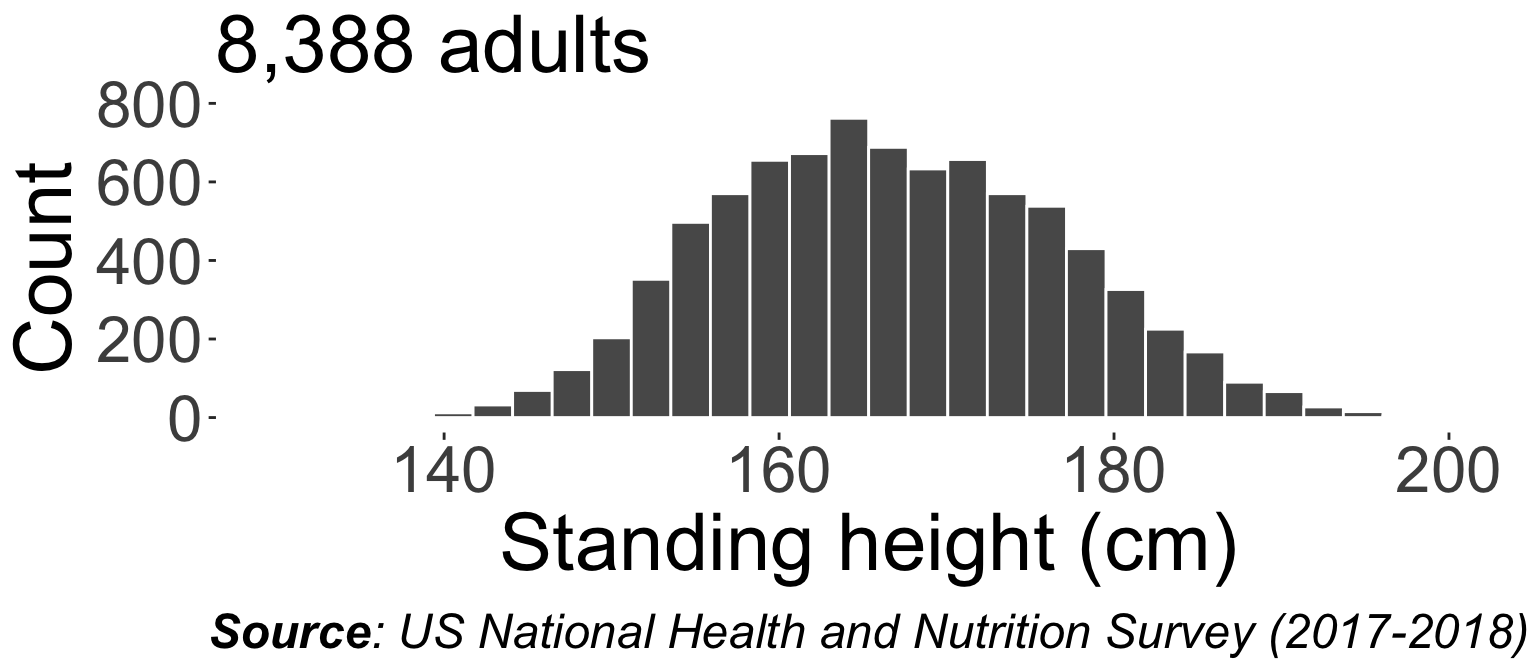
Continuous data in the wild
Comparing between normal distributions
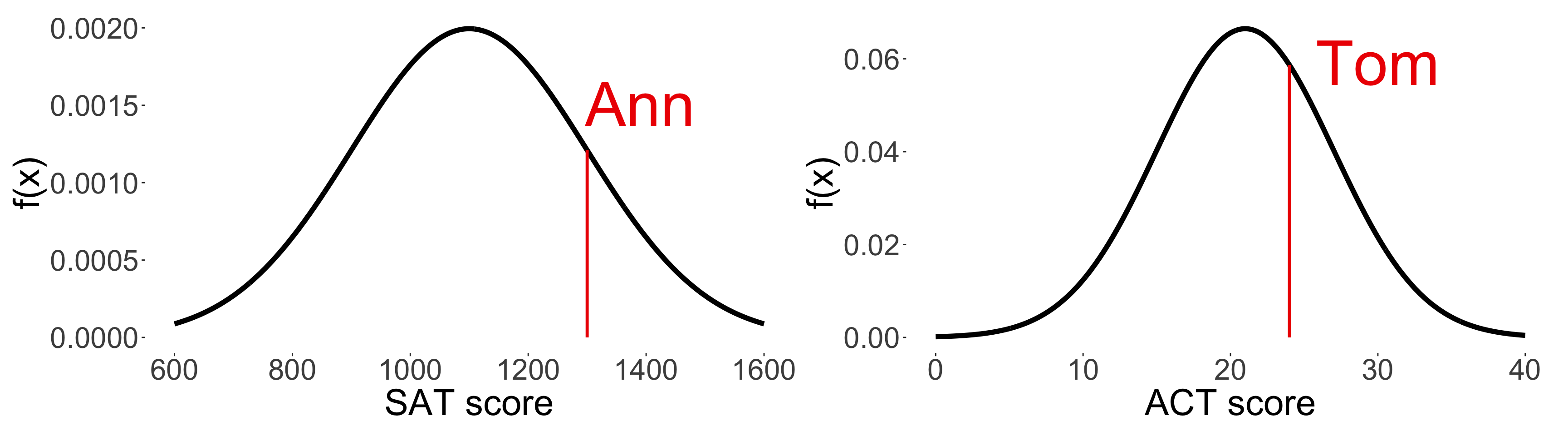
\(z_\text{Ann} = \frac{1300 - 1100}{200} = 1\) and \(z_\text{Tom} = \frac{24 - 21}{6} \approx 0.5\).
\(z_\text{Ann} > z_\text{Tom}\), so Ann performed better relative to her peers than Tom!
Probability calculation for normal distributions
Recall: the probability of a continuous random variable falling in a specific range is the area under the curve.
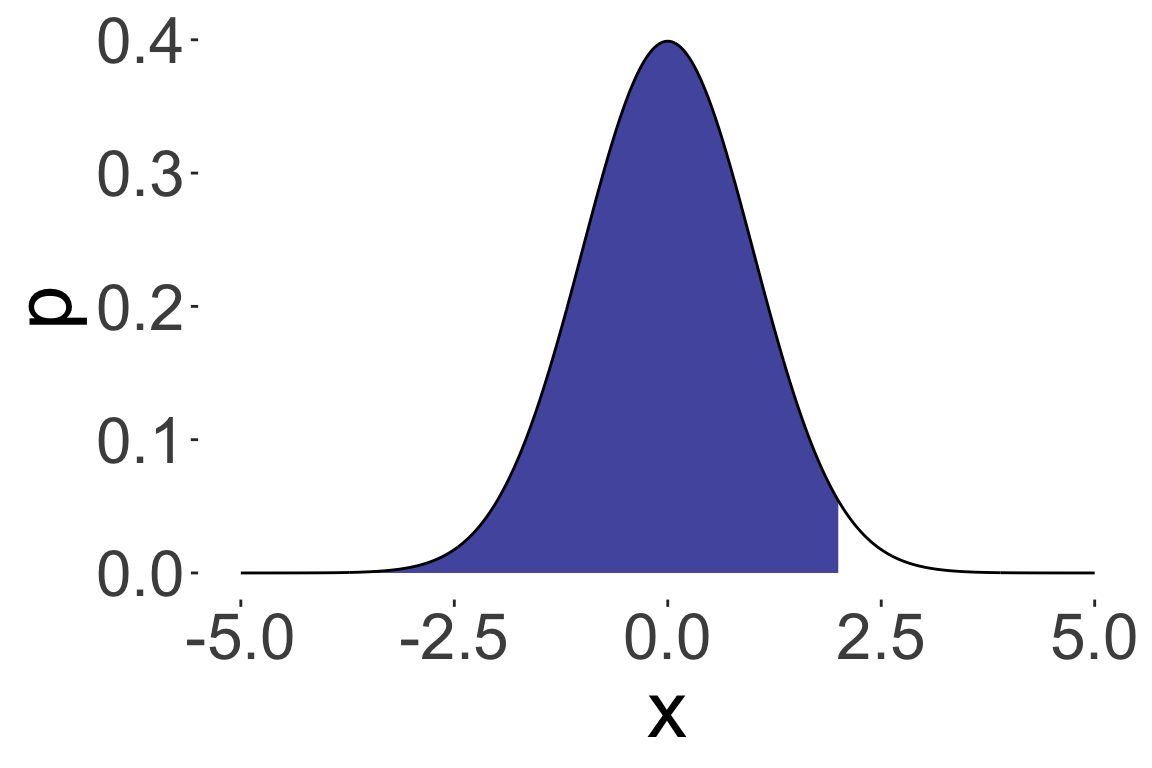
\(P(X < 2)\) where \(X \sim N(0, 1)\)
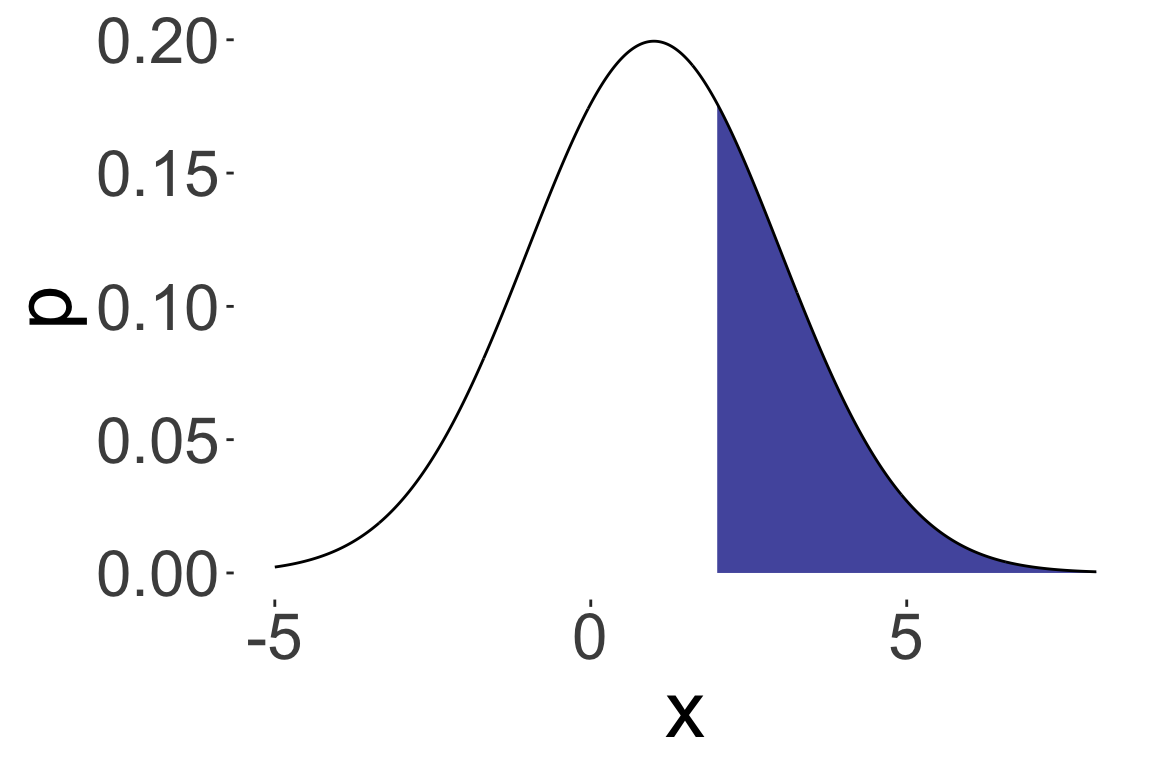
\(P(X > 2)\) where \(X \sim N(1, 2)\)
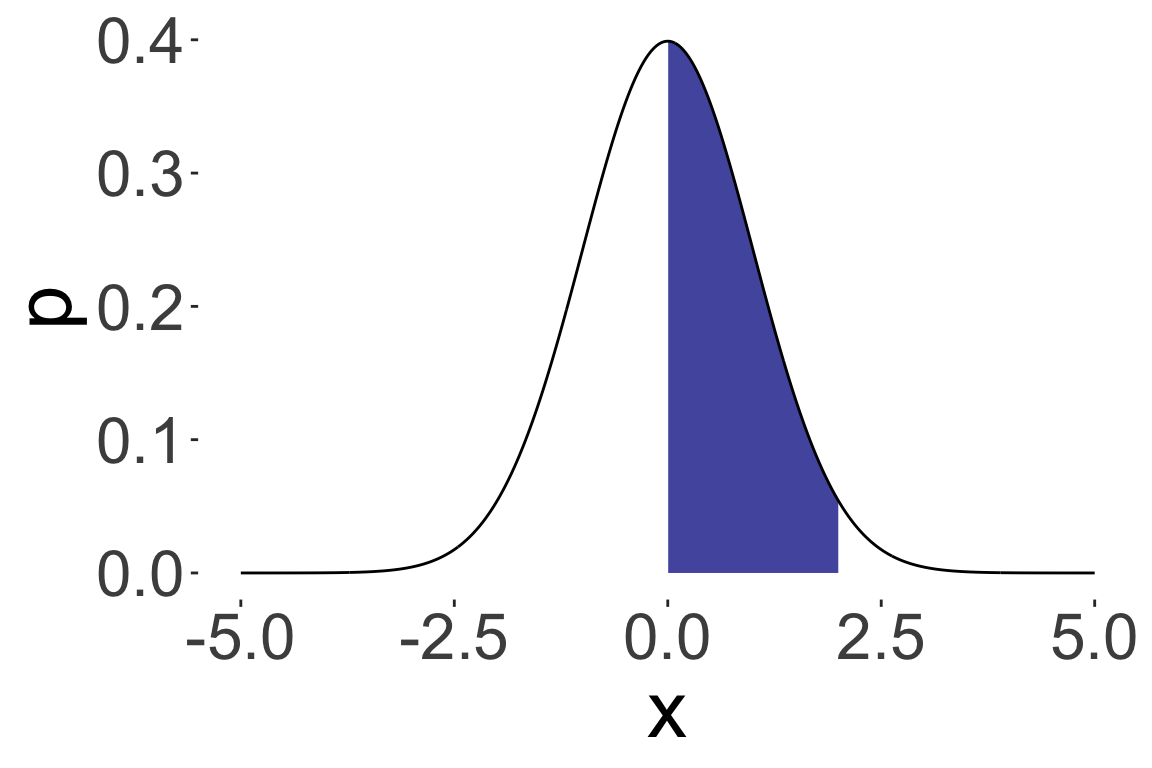
\(P(0 < X < 2)\) where \(X \sim N(0, 1)\)
68-95-99.7 rule
- For a normal distribution, approximately
- 68% of the population values are within 1 standard deviation of the mean,
- 95% are within 2 standard deviations of the mean, and
- 99.7% are within 3 standard deviations of the mean.
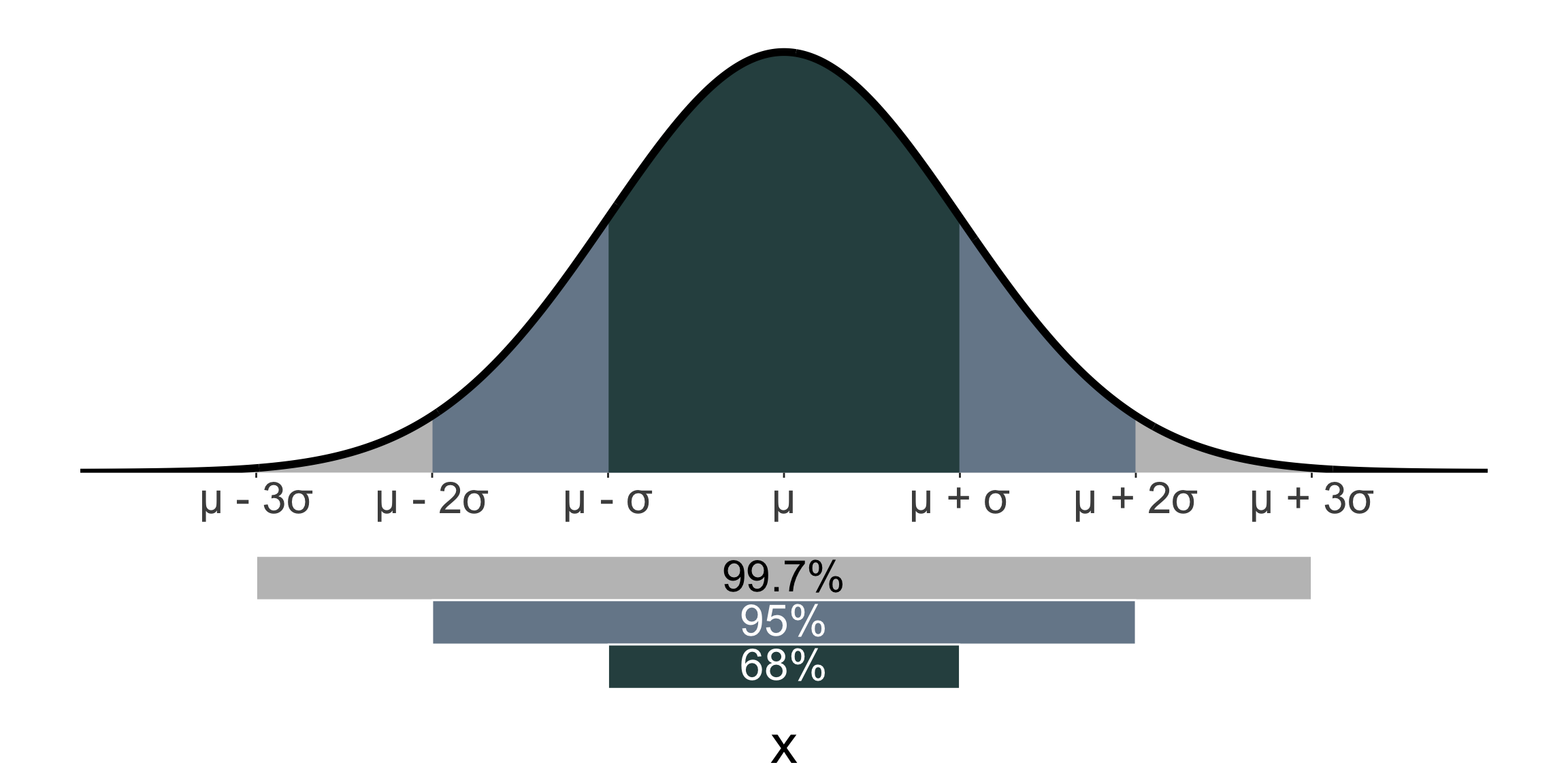
E.g. the average adult height is ~167cm, and the standard deviation is ~10cm based on US National Health and Nutrition Examination Survey (2017-2018) data. So assuming the distribution of adult heights is normal, approximately 99.7% of adults have a height between 137cm and 197cm.