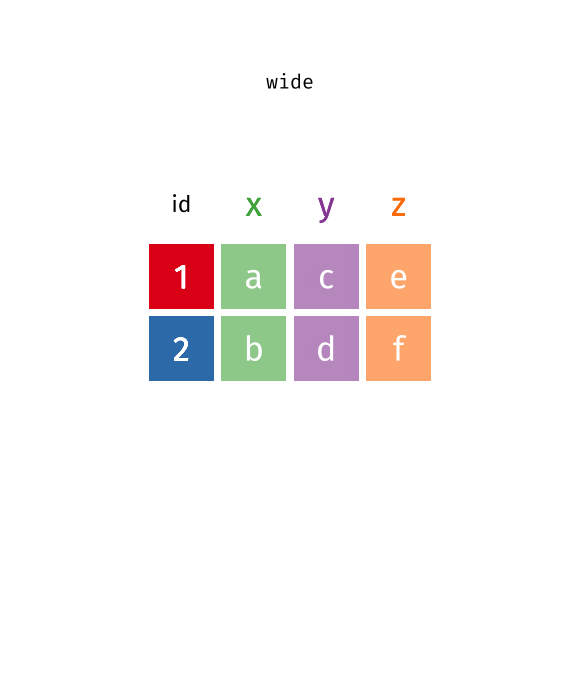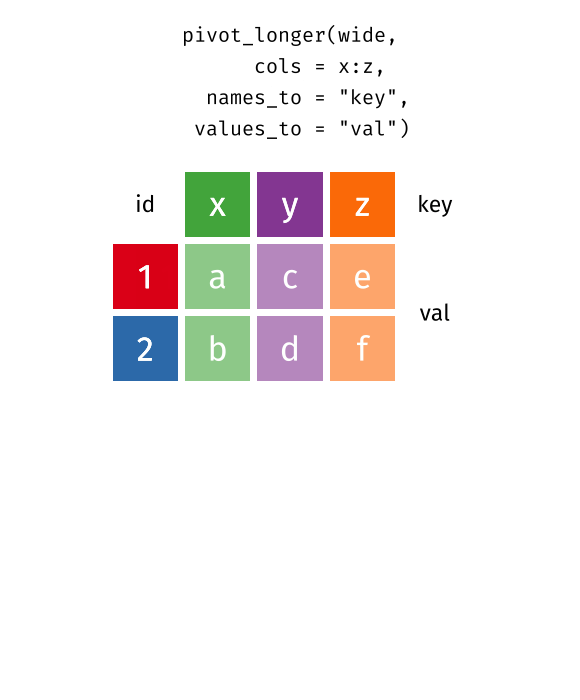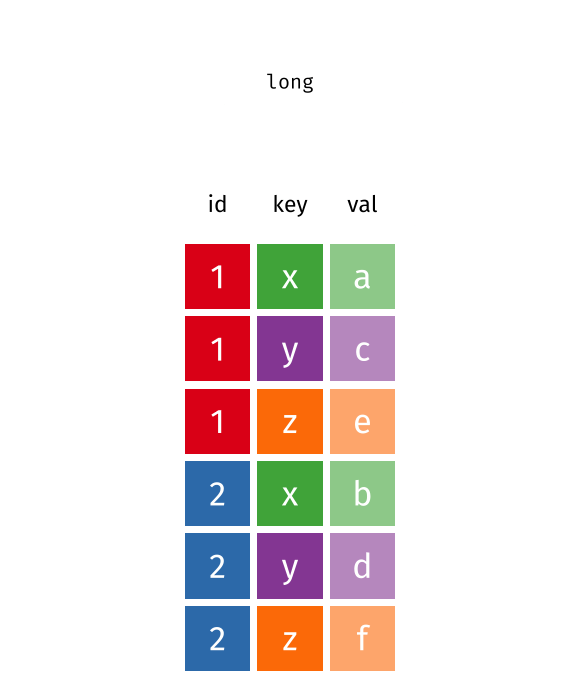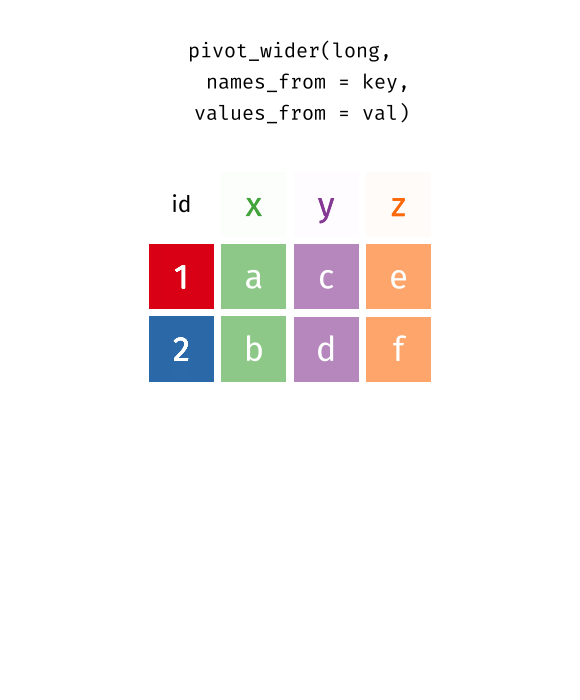
crop_long <- data.frame(year = c(1900L, 1900L, 1900L, 1900L, 2000L, 2000L, 1900L, 1900L, 1900L, 1900L, 2000L, 2000L, 2000L, 2000L),
state = c("Iowa", "Iowa", "Kansas", "Kansas", "Kansas", "Kansas", "Iowa", "Iowa", "Kansas", "Kansas", "Iowa", "Iowa", "Kansas", "Kansas"),
crop = c("barley", "barley", "barley", "barley", "barley", "barley", "wheat", "wheat", "wheat", "wheat", "wheat", "wheat", "wheat", "wheat"),
metric = c("yield", "acres", "yield", "acres", "yield", "acres", "yield", "acres", "yield", "acres", "yield", "acres", "yield", "acres"),
value = c(28.5, 620000, 18, 127000, 35, 7000, 14.4, 1450000, 18.2, 4290000, 47, 18000, 37, 9400000))