Joining two datasets
STAT1003 – Statistical Techniques
Australian National University
These slides are best viewed on a modern browser like Google Chrome on a desktop or laptop. Some interactive components may require some time to fully load.
Primary key
- A primary key (sometimes called candidate key) is the smallest subset of columns that uniquely identifies each row in a table. E.g.
species_idis the primary key in thespeciestable,plot_idis the primary key in theplotstable, andrecord_idis the primary key in thesurveystable.

Simple key & Compound key
- If only a single column then it is called a simple key.
- If a key consists of more than one column then it is called a compound key.
- E.g.
ChickWeighthas a compound key consisting ofTimeandChick.
- E.g.
- A table can also have no key (violating the relational model).
- E.g.
chickwtshas no key.
- E.g.


Foreign key
- A foreign key is a column in one table that uniquely identifies a row in another table.
plot_idandspecies_idare foreign keys in thesurveystable, which link to theplotsandspeciestables, respectively.- There are no foreign keys in the
plotsandspeciestables.
Joining tables
- To join tables, we use the primary key in one table and the foreign key in another table.
- In a relational model, a database has referential integrity if all relations between tables are valid. E.g.,
- All primary key values must be unique and not missing.
- Each foreign key value must have a corresponding primary key value.
- In a relational model, normalization aims to keep data organization as clean and simple as possible by avoiding redundant data entries.
Equality (equi) joins in dplyr
- Natural join is a special case of equality join where the join is performed on all columns with the same name in both tables.
- In
dplyr, you can useby = NULL(default) to perform a natural join.
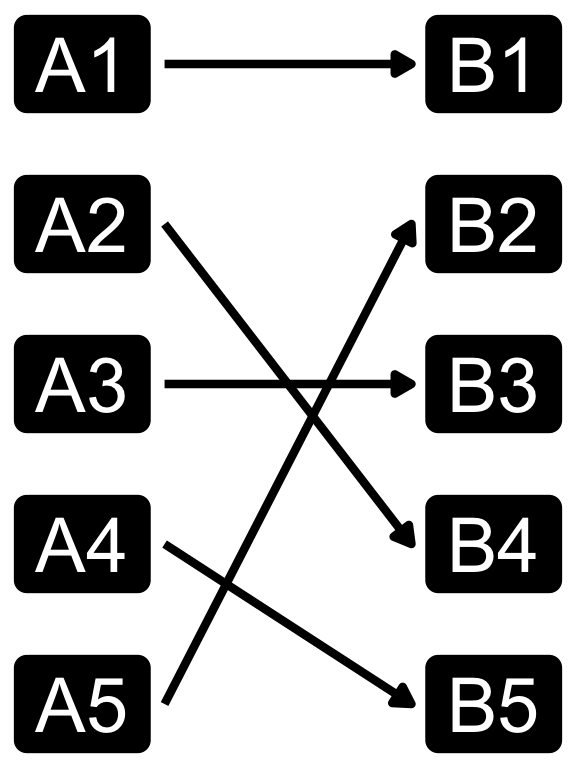
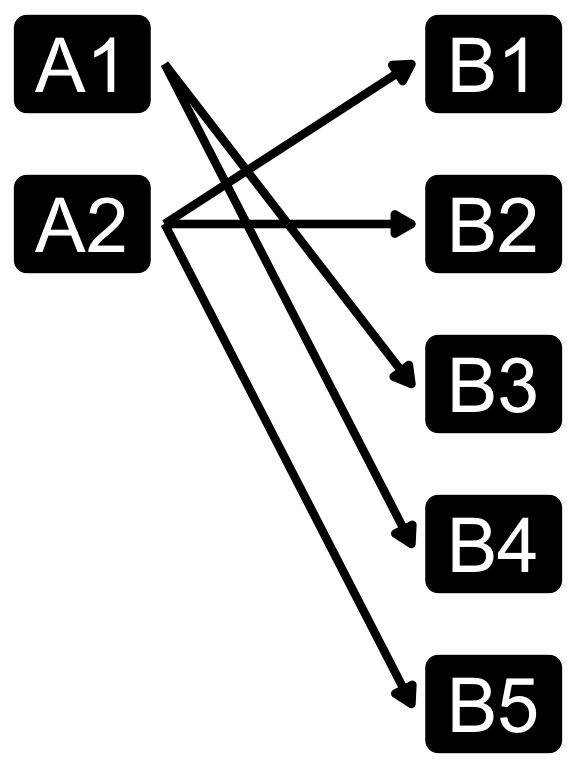
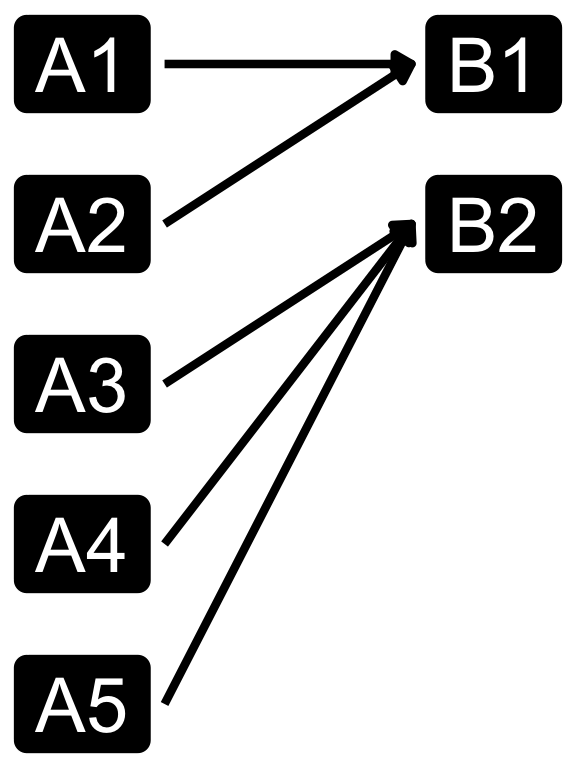
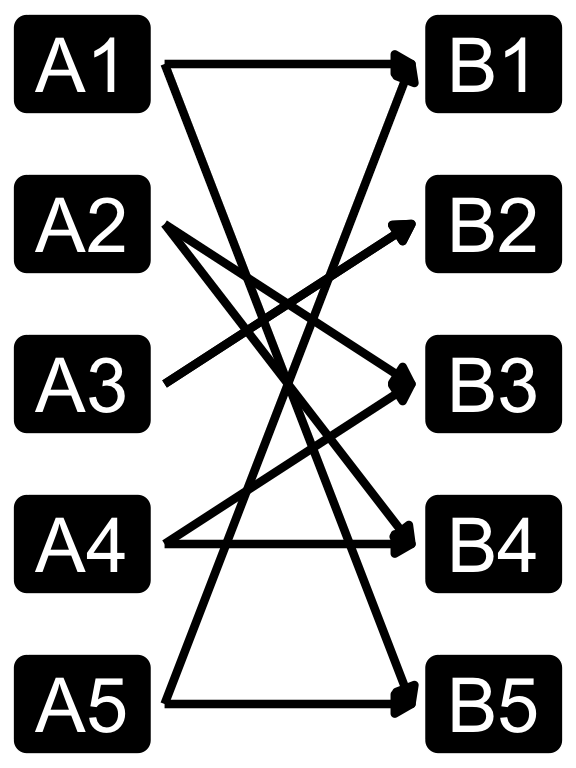
Cardinality in data modelling
- The relationship between the two tables can be categorized into four types:
Summary
- Relational data consists of multiple, linked tables.
- Primary keys uniquely identify each record in a table.
- A foreign key is required to join tables together.
- A key can be simple (one column) or compound (multiple columns).
- Cardinality describes the relationship between tables (one-to-one, one-to-many, many-to-one, or many-to-many) which can be used to ensure data integrity.
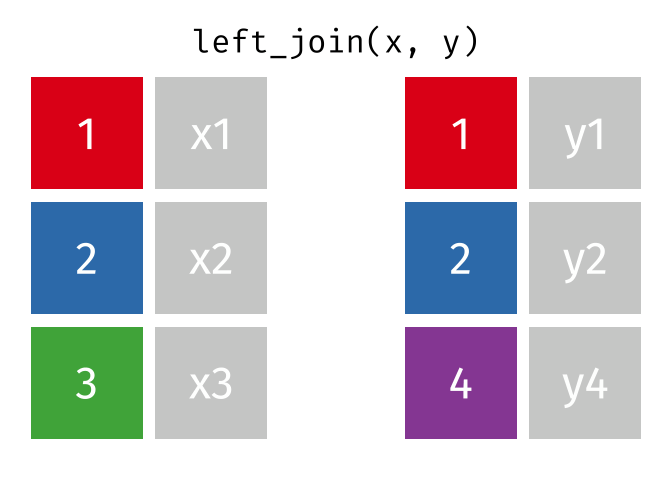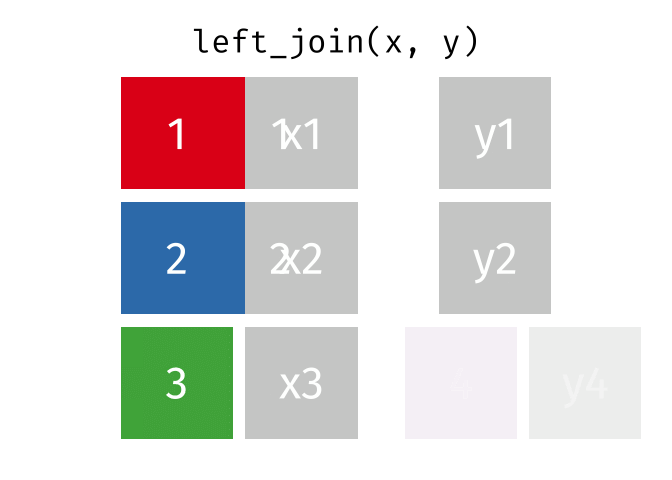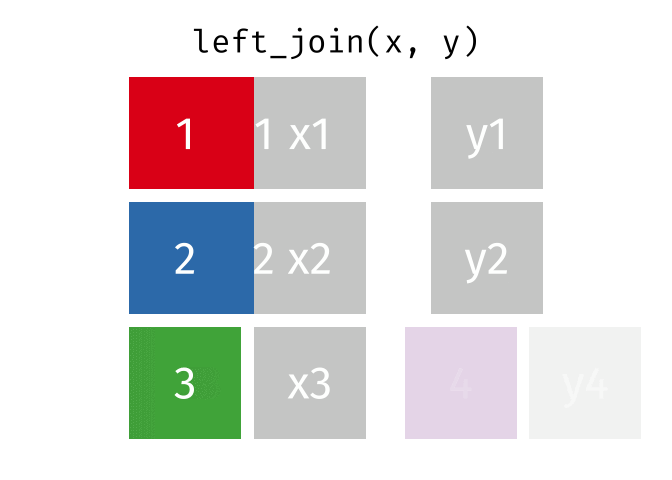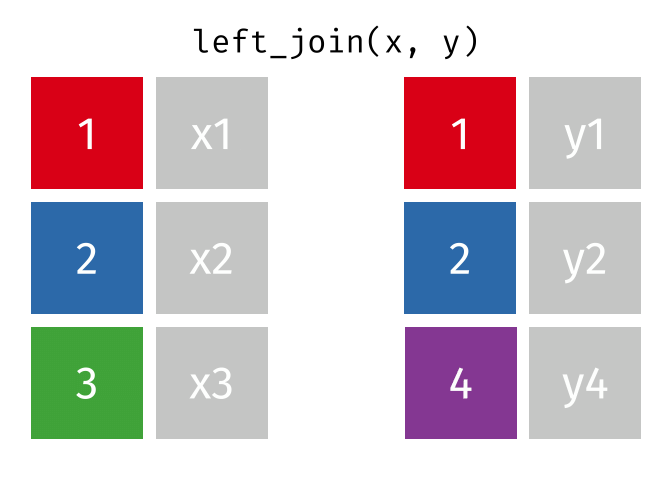
- Left join
- Left join (extra)
- Right join
- Semi join
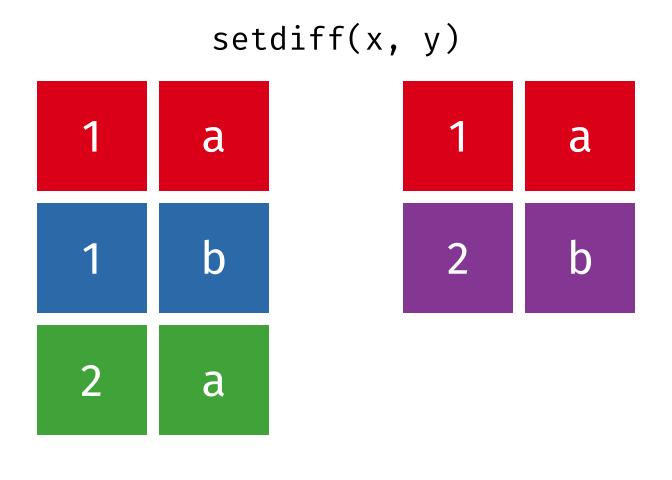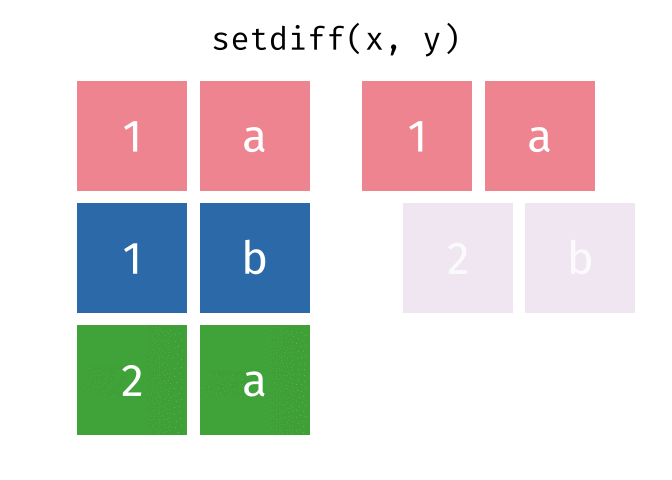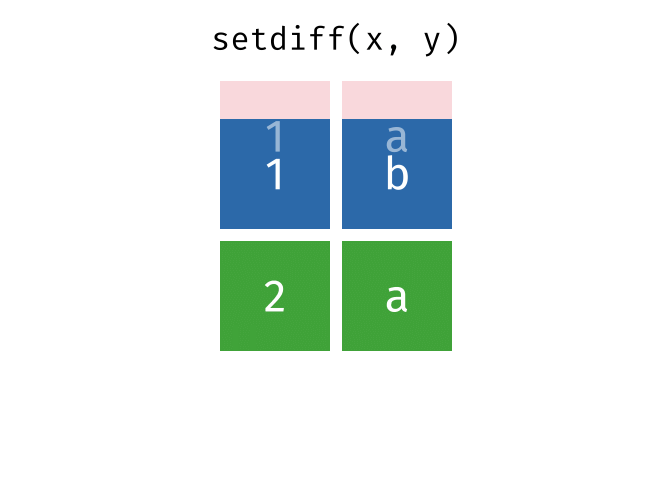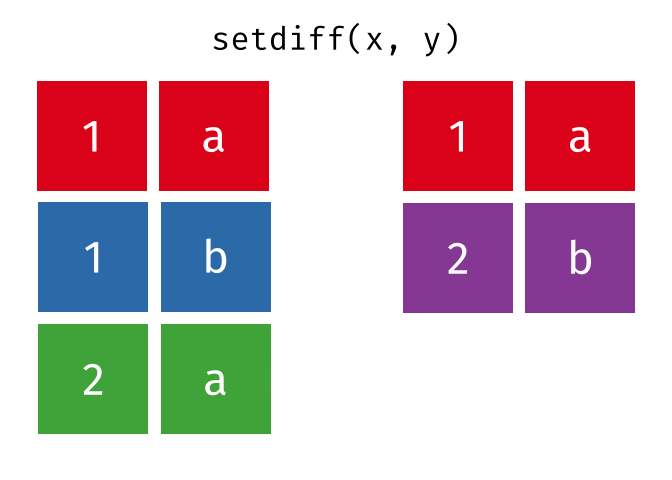
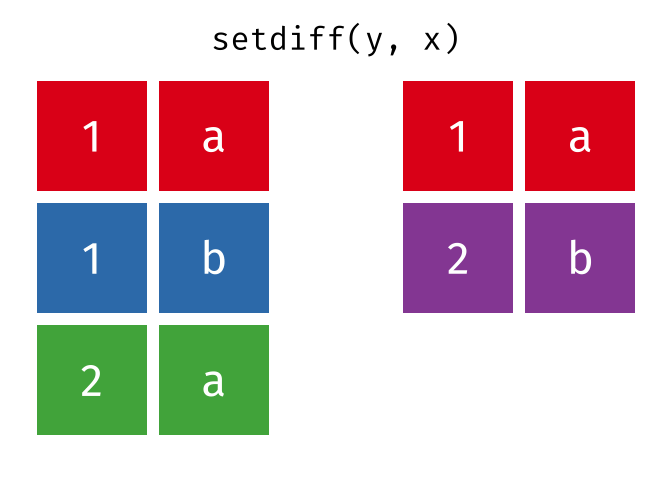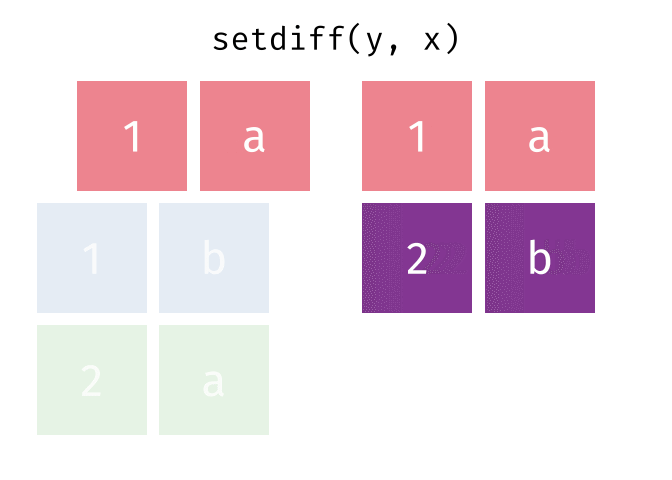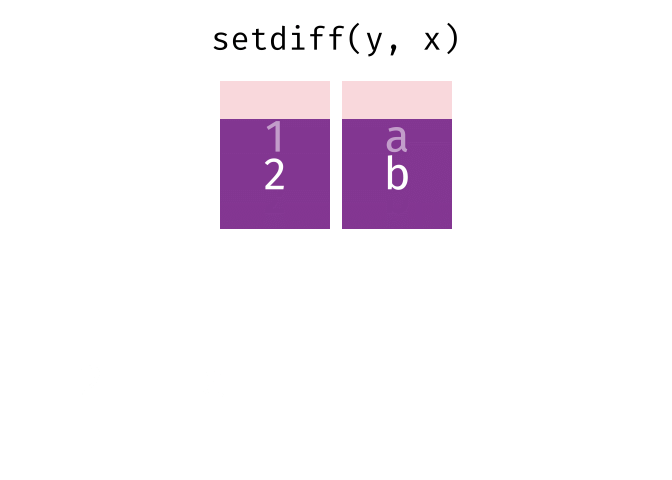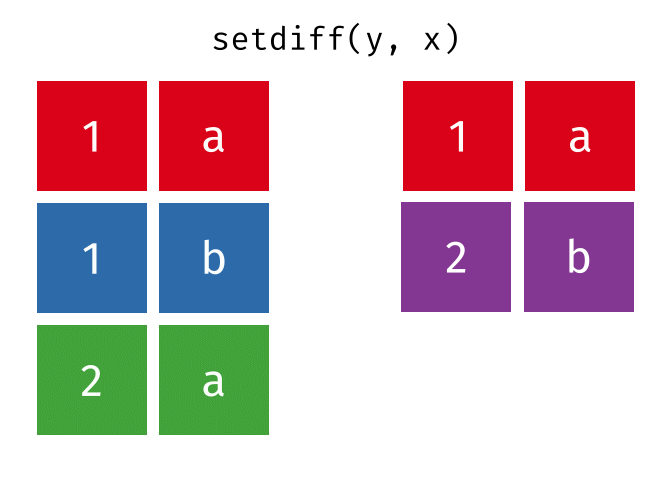
- Set diff
- Set diff (reverse)
- Anti join
- Full join
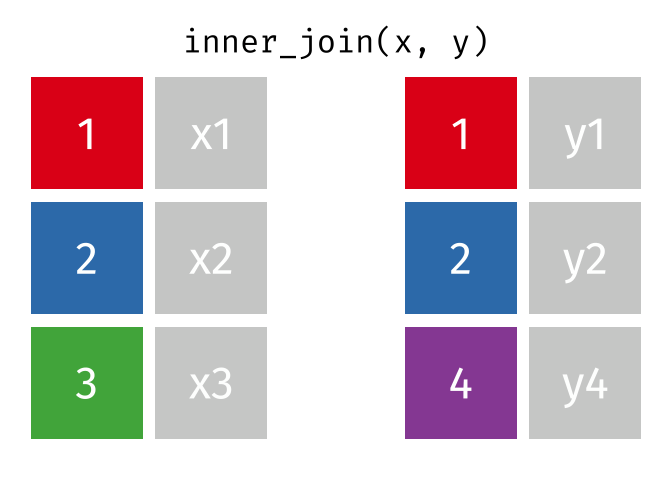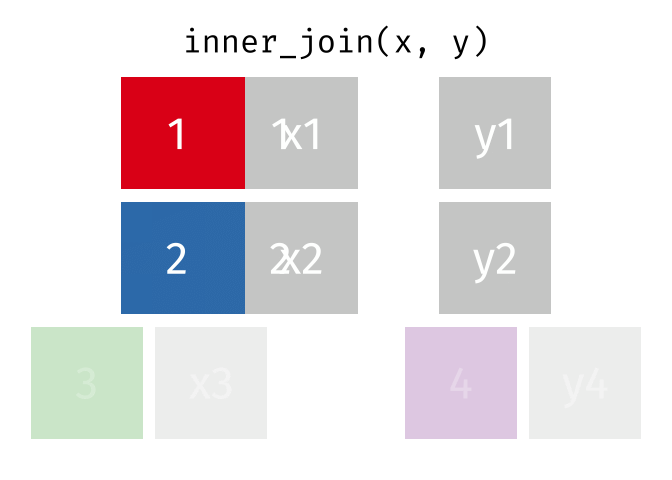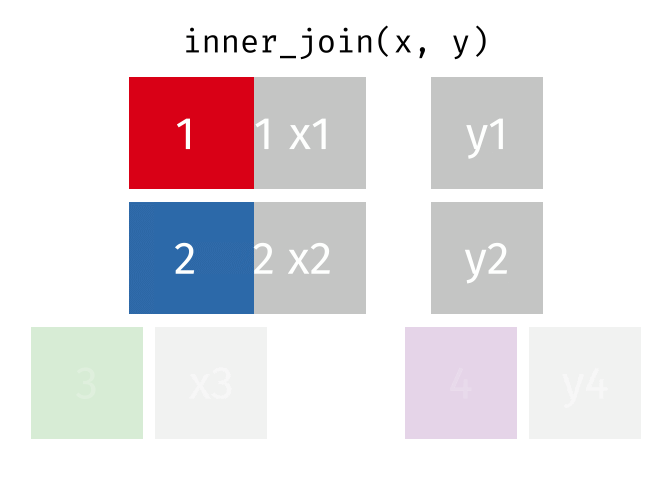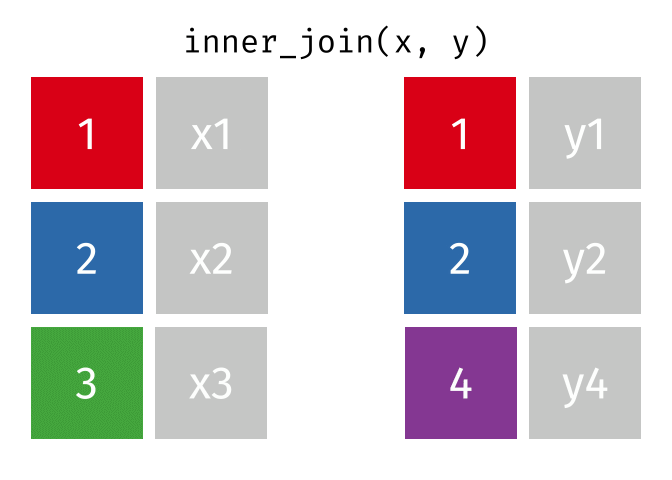
- Inner join
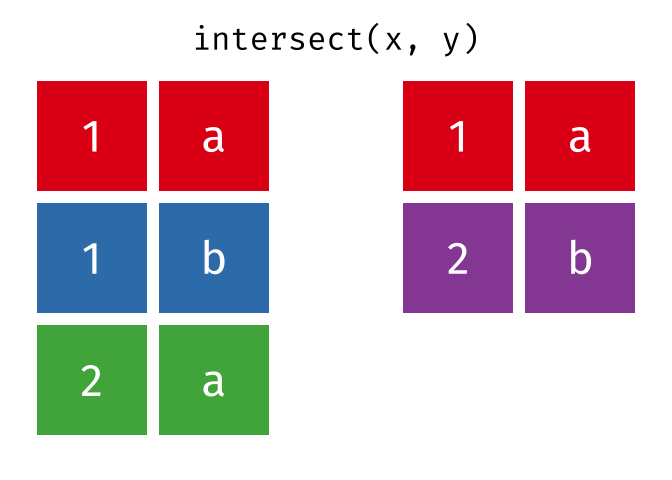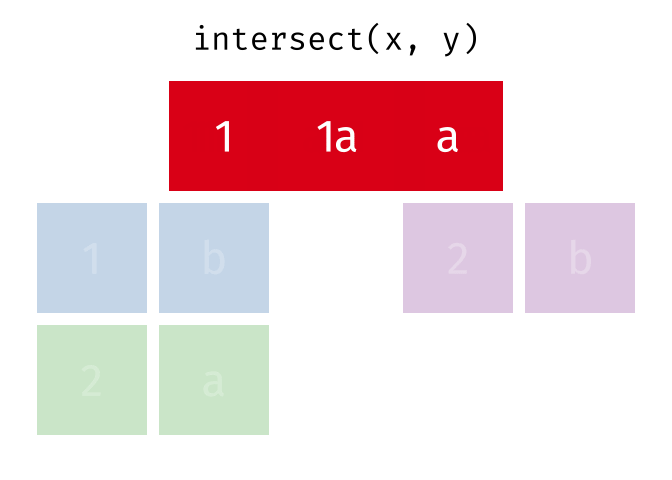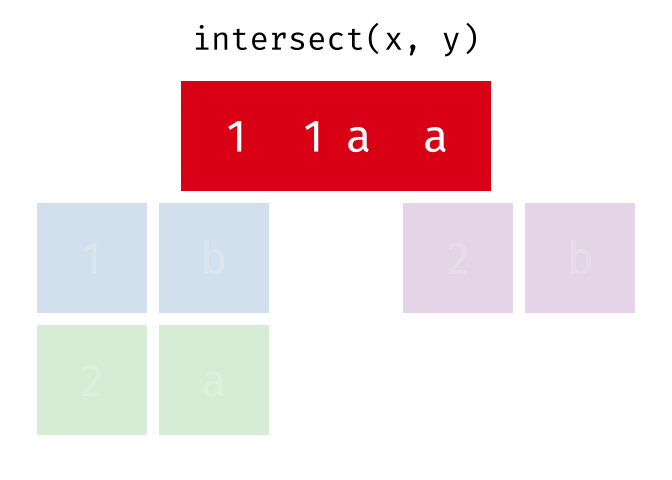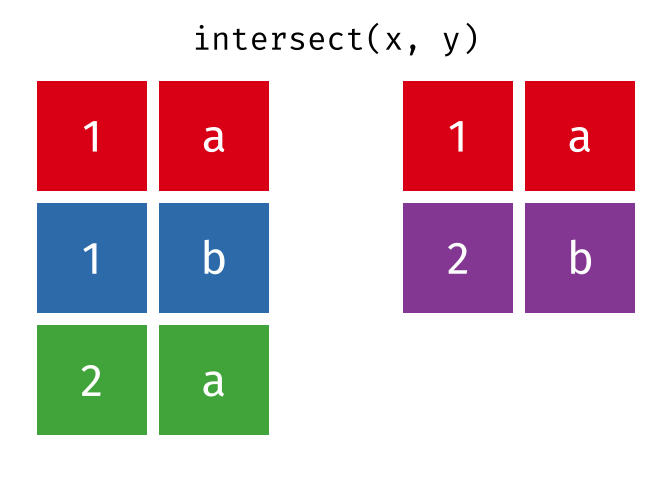
- Intersect