Basic Statistical Concepts and Programming II
STAT1003 – Statistical Techniques
Australian National University
These slides are best viewed on a modern browser like Google Chrome on a desktop or laptop. Some interactive components may require some time to fully load.
Wrong interpretation of correlation coefficient

Source: xkcd
Just because \(x\) and \(y\) are highly correlated, it does not mean that \(x\) causes \(y\) or vice versa – correlation is not causation!
- Number of ice cream sales and the rate of drowning deaths.
- It is also easy to get spurious correlation if computing many pairwise correlations.
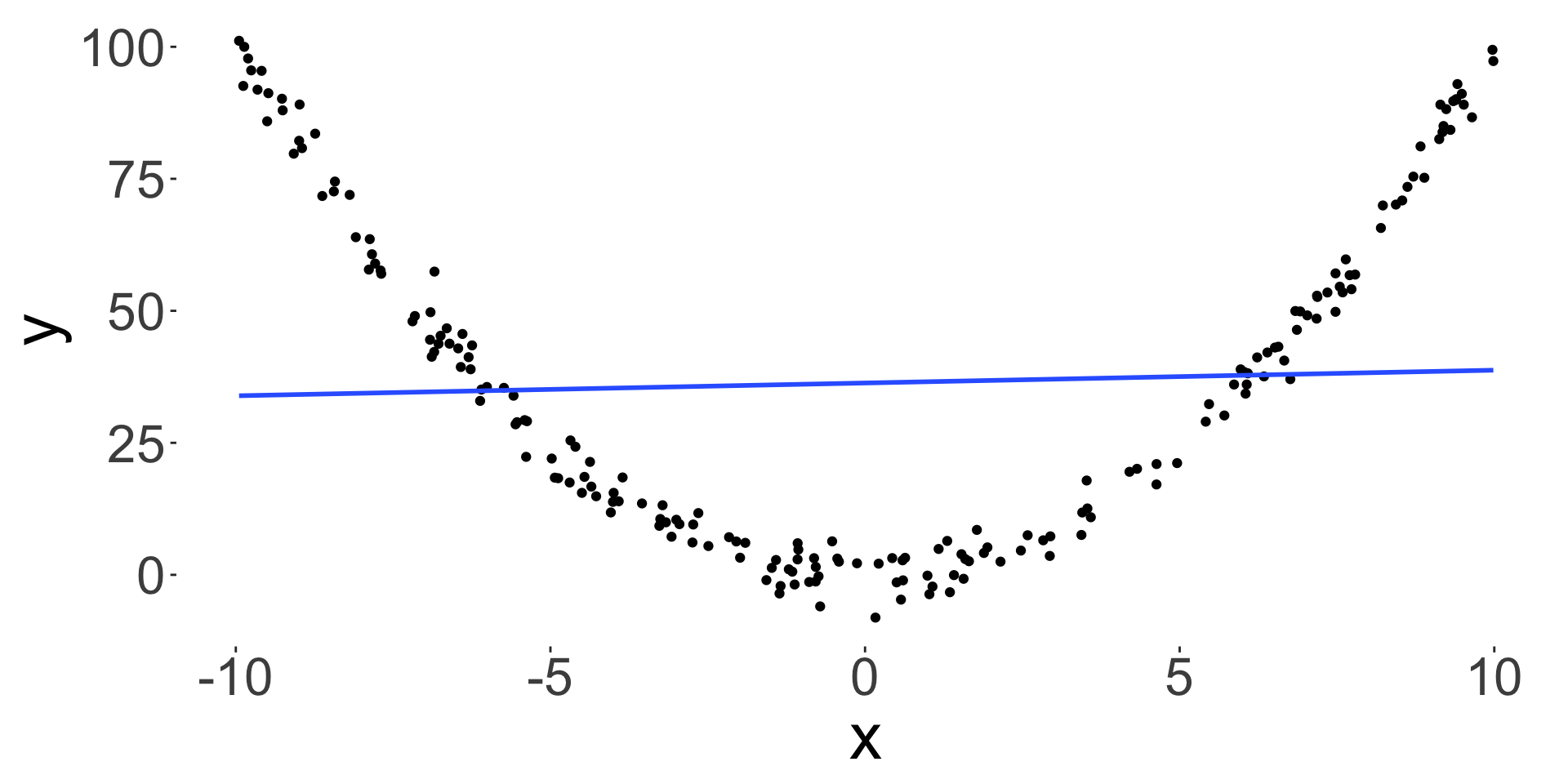
- Correlation also only measures a linear relationship, so low correlation doesn’t mean that there is no relationship.
\[r = -0.0315557\]
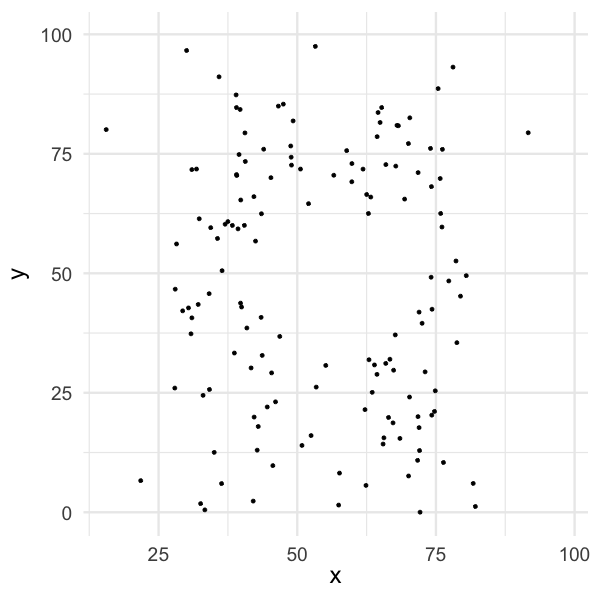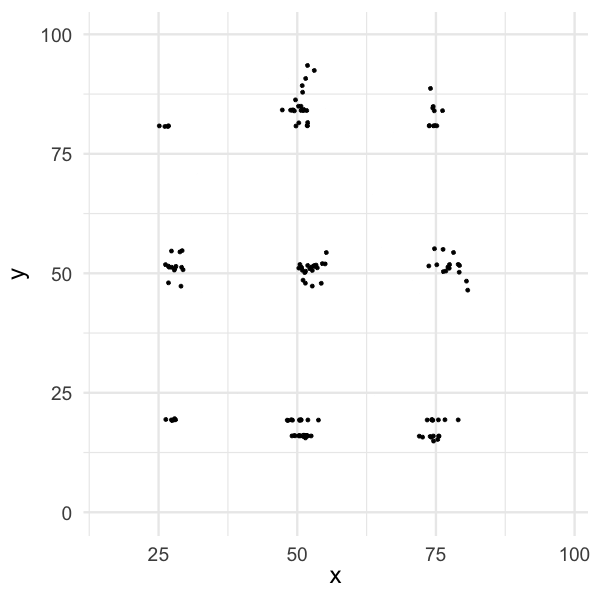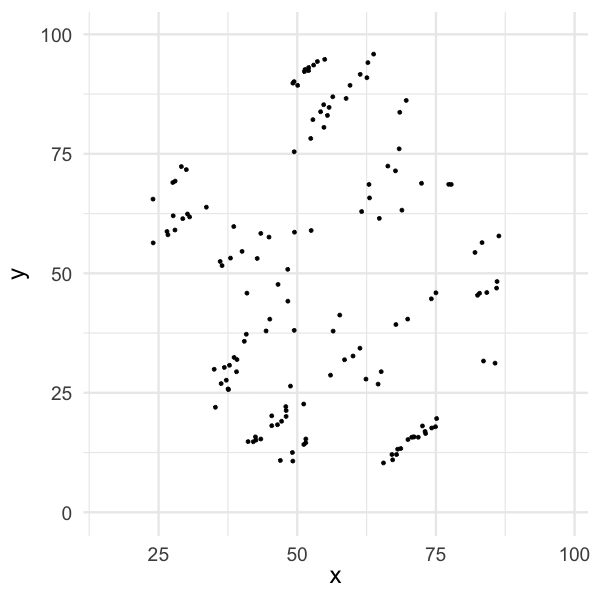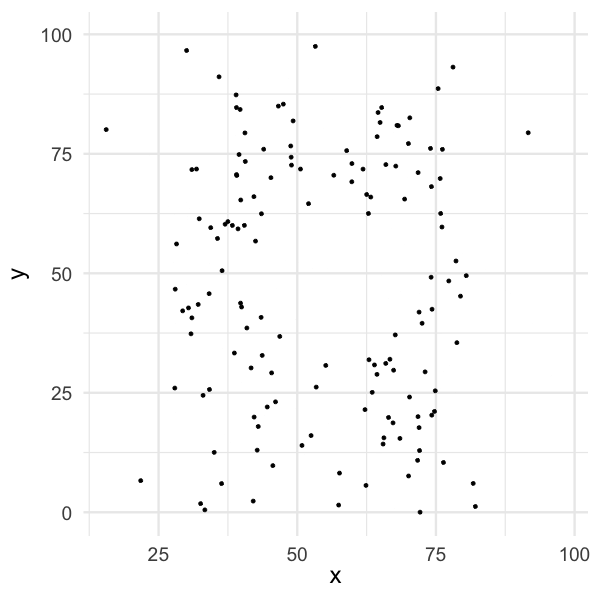
Summary statistics can be misleading
- You can have a bivariate dataset with the exact same:
- marginal mean,
- marginal variance and
- correlation, but the relationship between the two variables can be very different.
- Always plot your data!

Base R Cheatsheet


Tidyverse
- Tidyverse refers to a collection of R-packages that share a common (opinionated) design philosophy, grammar and data structure.










- This trains your mental model to do data science tasks in a manner which may make it easier, faster, and/or fun for you to do these tasks.
library(tidyverse)is a shorthand for loading the 9 core tidyverse packages:ggplot2,dplyr,tidyr,readr,tibble,purrr,stringr,forcats,lubridate.
A grammar of data manipulation
dplyris a core package intidyverse- It provides a grammar of data manipulation that is consistent with the tidyverse design philosophy.
- Similar data manipulation can be achieved with base R but
dplyrprovides a more consistent and user-friendly interface for data manipulation tasks. - The earlier concept of
dplyr(first on CRAN in 2014-01-29) was implemented inplyr(first on CRAN in 2008-10-08). - The functions in
dplyrhas been evolving butdplyrv1.0.0 was released on CRAN in 2020-05-29 suggesting that functions indplyrare maturing and thus the user interface is unlikely to change.
Lifecycle





- Functions (and sometimes arguments of functions) in
tidyversepackages often are labelled with a badge like on the left
Lionel Henry (2020). lifecycle: Manage the Life Cycle of your Package Functions. R package version 0.2.0.
dplyr cheatsheet
![]()
![]()
Reproducible Example with reprex LIVE DEMO
- Copy your minimum reproducible example then run
- Once you run the above command, your clipboard contains the formatted code and output for you to paste into places like Canvas discussion board