Basics of Statistics
STAT1003 – Statistical Techniques
Australian National University
These slides are best viewed on a modern browser like Google Chrome on a desktop or laptop. Some interactive components may require some time to fully load.
What is statistics?
Statistics is defined as the science and technology of obtaining useful information from data, taking its variability into account.
- Statistics involves:
- designing the collection of data,
- organizing data,
- analyzing data,
- developing methods,
- interpreting the results, and
- communicating results.

Why study statistics?
The best thing about being a statistician is that you get to play in everyone’s backyard.
- In a data rich world, statistical literacy is essential for everyone.
- Statistics is essential for making sense of information across fields such as biology, medicine, physics, social sciences, finance, business, and numerous other fields.
- Statistical literacy enables us to think critically and make evidence-based decisions
Newspaper articles from The Australian in January 2026


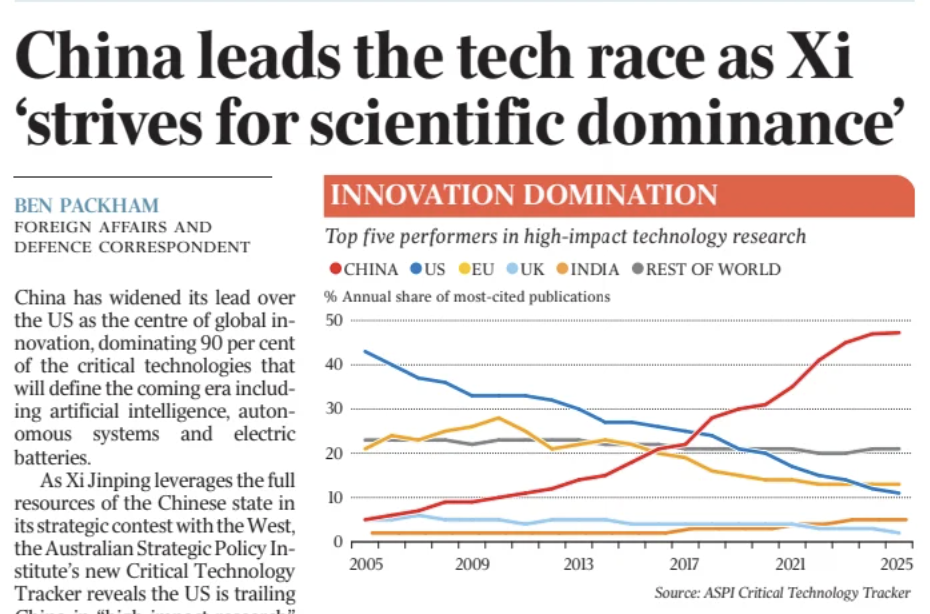

Become a data detective
Technical proficiency (understand statistical methods and skilled with statistical software for extracting and analyzing data) alone isn’t enough for practice. Think holistically.
- Curiosity: Naturally inquisitive and eager to explore the “why” behind data anomalies or trends.
- Problem-solving skills: Resourceful and persistent in finding solutions and overcoming data challenges.
- Attention to detail: Notices subtle patterns, inconsistencies, or outliers others might miss.
- Critical thinking: Evaluates information objectively, questioning assumptions and sources, and have a healthy dose of skepticism.
- Communication abilities: Clearly conveys insights and explanations to technical and non-technical audiences.
- Ethical judgment: Handles data responsibly and respects privacy and security considerations.
- Collaboration: Works well with colleagues from different domains.
- Project management: Organizes work efficiently, sets goals, and meets deadlines during investigations.

Population vs. Sample
Populations have parameters: a descriptive measure of a population that is usually unobservable and unknown.

Sample statistics are estimated from sample data and used to make inferences about population parameters.
- Ideally, we would measure every single unit of interest (e.g. marks of every STAT1003 student).
- But this is often impractical or unavailable (we only have the 2025 data).
- Instead, a (representative) sample from the population is used to make inference of the population.
Mathematical setup
How hard is STAT1003 at ANU for a typical undergraduate student as measured by the average final grade earned by students in STAT1003?

Population vs sample mean

Let \(\mu\) denote the population mean (average) final grade of all STAT1003 students. \[\begin{align*} \mu &= \frac{1}{N}(x_{1'} + x_{2'} + \dots + x_{N'}) = \frac{1}{N}\sum_{i=1}^{N} x_{i'}\\ &= {\tiny \frac{1}{14}(73 + 60 + 54 + 62 + 71 + 68 + 57 + 60 + 72 + 57 + 35 + 53 + 58 + 70)} \approx 60.7\\ \end{align*}\]
Let \(\bar{x}\) denote the sample mean (average) final grade of the sampled STAT1003 students. \[\begin{align*} \bar{x} &= \frac{1}{n}(x_1 + x_2 + \dots + x_n) = \frac{1}{n}\sum_{i=1}^{n} x_i\\ &= {\tiny \frac{1}{5}(54 + 71 + 57 + 70 + 53)} = 61\\ \end{align*}\]
\(\bar{x}\) is used to estimate \(\mu\).